
代码的艺术
作者简介:章淼,章博士,清华大学计算机博士,百度云前端技术负责人,百度 Golang & Python 技术委员会成员。
笔记
对比Google的工程师,国内的工程师写代码的占用时间显然过多了,而不太注重提前设计 ;Google 工程师们在开始实现某一模块或功能时,会事先在代码库中搜索是否已经有可重用的代码,并且代码库中的代码具有完整的注释和文档。
提前设计的重要性
尽可能地提前完成两个文档
- 需求分析文档
- 系统设计文档
原因:在未启动实现细节代码之前构思设计时发现问题的修改,对比后期真正已经开始Coding的时候,对比发现问题进行修改,成本要低很多。文档一般只写主要逻辑,而代码涉及更多细节。
笔者备注:但这不是绝对的,修改是正常的,不要惧怕修改,反复尝试积累经验。
- 需求分析文档:主要是在定义黑盒状态,描述外在,描述
WHAT要做什么? - 系统设计文档:主要实在定义白盒状态,描述内在,描述
HOW怎么做?
两者要有区分,不要混淆 ,也不要混在一起写!
需求分析文档的误区:
不要过早提前构想实现细节,我们的大脑会下意识地在我们构想如何实现时遇到的各种难题,而将原本的需求分析的思考挂起;举例:导弹 vs 炸弹,两者都有摧毁目标的能力,但是很明显导弹的价值更高,重要的是制导的功能,而不是爆炸本身。
系统设计文档的误区:
主要要写定义系统的架构、模块、接口、数据、关键算法、设计思路等等得过程记录。
系统架构要写什么以及方法
概念、模型、视图等等。
- 静:系统静态的样子,功能模块如何划分等
- 动:系统运转起来,各模块联动起来的样子
- 细:不同角度,不同层次去描述
- 每一个组件(模块、函数)保证单一性, Single purpose. 只做一件事!
- 轻耦合,低内聚(避免全局变量(多处操作难以控制))
- 当前系统设计所受到的约束(当前设计的瓶颈在哪?比如网络、吞吐量、占用 CPU 或文件位置资源等)
- 需求分析是系统设计的来源
- 模型和抽象的思维能力很重要(涉及概念:模型、数据结构、算法等等)
设计接口(Interface)要注意什么?
- 接口定义系统外在的功能
- 接口定义当前系统与外部系统之间的关系
接口Interface定义了系统对外的接口,往往比系统实现内部细节代码更重要,不要过于草率,因为一旦定义了接口,提供出去给调用方使用,想修改就太难了。所以设计接口有重要原则,站在使用者的角度考虑问题!
两点细节:
- 向前兼容(尽量不要接口已升级,老接口全不能用,那就不是好的接口设计)
- 使用方便(让调用者可以一目了然知道接口的作用,简化传参,说明返回值等等)
如何写代码?
代码是一种表达的方式。是写给人看的,要有编程规范 。
拥有编程规范的理想状态:
- 看别人代码就像看自己代码一样易懂;
- 看代码主要看逻辑,不要过多注重细节;
- 代码尽可能地不要让人去多想。
Don’t make me think!
Moudle模块
紧内聚,低耦合。单一功能。反例,定义一个 utils.py 内部包含诸多方法,不易懂。
模块一般可以分为两类:
- 数据类的模块(1. 主要完成对数据的封装; 2. 对外提供的数据接口)
- 过程类的模块(1. 不要包含数据,可以是调用数据类的模块或者调用其他过程类模块; 2. 具备操作性质的模块)
模块的重要性:
- 降低维护成本;
- 更好地复用
Class类和Function函数
两者是不同的模型,各自有各自适用的范围。
推荐方法: 和类的成员无关的函数,尽量独立出去单独一个函数,不建议作为类的成员函数。
面向对象思想的讨论:多态和继承,需要谨慎适用,作为Python的工程师,不太推崇Java中继承和多态,因为系统是逐渐长起来的,并不是从一开始就是一个成熟的样子,所以很难凭空去设计一个继承的关系。
模块的构成
文件头(注释)
- 模块的说明,简要功能
- 修改历史(时间、修改人,修改的内容)
- 其他特殊细节的说明
函数(重要性仅次于模块)
- 描述功能
- 传入参数的描述(含义、类型、限制条件等等)
返回值得描述(有足够明确的语义说明)
逻辑判断型 check is XXX
操作型(成功 or 失败)
数据获取型(状态 + 数据)
异常如何处理(是抛出?还是内部catch?要明确)
- 明确单入口和单出口(多线程开发时尤为重要)
函数要尽可能的规模小,足够短(BUG 往往出现在非常长的一个函数里)
代码块的分段也很重要,分段背后是划分和逻辑表达。
代码是一种表达能力的体现,也算是文科的范畴! 注释不是补出来的!
命名的重要性:要准确、易懂、可读性强,尽量做到 望名生义 。
互联网时代的系统是运营出来的。
可检测性也是尤其重要的。(埋点、监控等等)
没有数据的收集,等于系统没有上线。
监控不单单只有传统意义上的内存、CPU、网络、崩溃率的监控,还应有线上真实数据监控,需要有足够多的状态记录。
日志是很有限的一种监控手段,并且采集日志也是一种资源耗费。推荐的手段:可以使用埋点,对外提供接口,有单独的系统调用接口进行有针对性的采集。
修身
好的程序员,与工作年限无关,与学历无关
学习-思考-实践
学习:主观意愿地学习,途径也有很多,例如书籍、开源代码、社区。忌讳夜郎自大、井底之蛙。注重培养自己学习吸收的能力,多读多看但是数量不是最终目的。
Stay Hungry, Stay Foolish. – Steve Jobs
思考:学习需要经过思考,形成自己的思维。
实践:《卓有成效的时间管理者 - 德鲁克》推荐阅读
知识-方法-精神
知识过时会非常快!
方法:分析问题、解决问题的能力尤其重要(定义问题、识别问题、定义关键问题)
精神:决定型,要做就要坚持做
前进的道路上不能永远都是鲜花和掌声。
基础乃治学之根本。
数据结构、软件工程、逻辑思维能力、研究能力,需要5-8年时间磨炼。
收起阅读 »Python的发展趋势
一、Python发展历史
Python是一种计算机程序设计语言。你可能在之前听说过很多编程语言,比如难学的C语言(语法和实现难度),非常流行的JAVA语言(尤其是现在分布式存储和服务),非常有争议的PHP(常见 WordPress 大多网站),前端HTML、JavaScripts、Node.JS、还有最近随着容器风行的Golang等等。那Python是What?
- 1989年,Python的创始人为吉多·范罗苏姆(Guido van Rossum)。1989年的圣诞节期间,吉多·范罗苏姆为了在阿姆斯特丹打发时间,决心开发一个新的脚本解释程序,作为ABC语言的一种继承。
- 1991年,第一个Python编译器诞生。它是用C语言实现的,并能够调用C语言的库文件。从一出生,Python已经具有了:类,函数,异常处理,包含表和词典在内的核心数据类型,以及模块为基础的拓展系统。
- 1992年,Python之父发布了Python的web框架Zope1.
- Python 1.0 - January 1994 增加了 lambda, map, filter and reduce.
- Python 2.0 - October 16, 2000,加入了内存回收机制,构成了现在Python语言框架的基础
- Python 2.4 - November 30, 2004, 同年目前最流行的WEB框架Django 诞生
- Python 2.5 - September 19, 2006
- Python 2.6 - October 1, 2008
- Python 2.7 - July 3, 2010
- In November 2014, it was announced that Python 2.7 would be supported until 2020, and reaffirmed that there would be no 2.8 release as users were expected to move to Python 3.4+ as soon as possible
- Python 3.0 - December 3, 2008
- Python 3.1 - June 27, 2009
- Python 3.2 - February 20, 2011
- Python 3.3 - September 29, 2012
- Python 3.4 - March 16, 2014
- Python 3.5 - September 13, 2015
最新参考:https://www.python.org/downloads/release
二、Python的前景
最新的TIOBE( https://www.tiobe.com/tiobe-index/ )排行榜,Python赶超JAVA占据第二名了, Python崇尚优美、清晰、简单,是一个优秀并广泛使用的语言。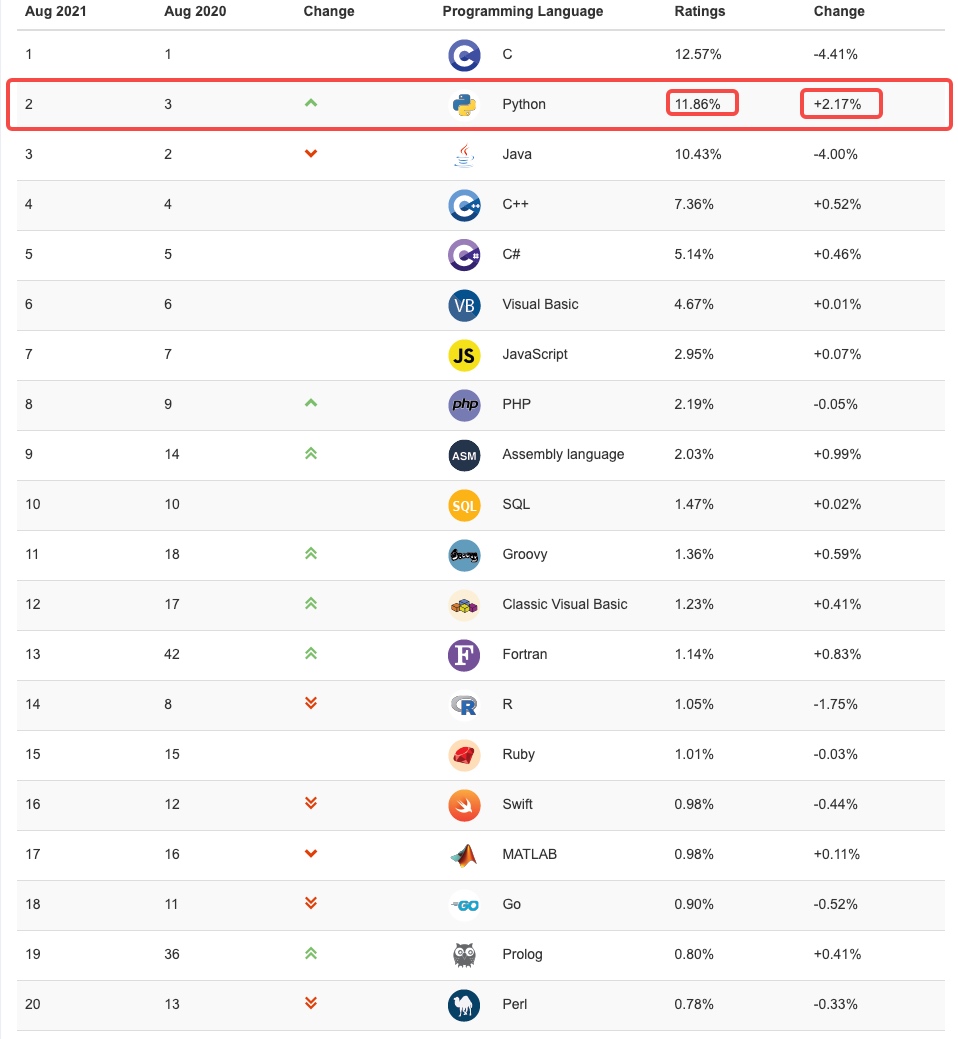
我们看看17年Python的排名: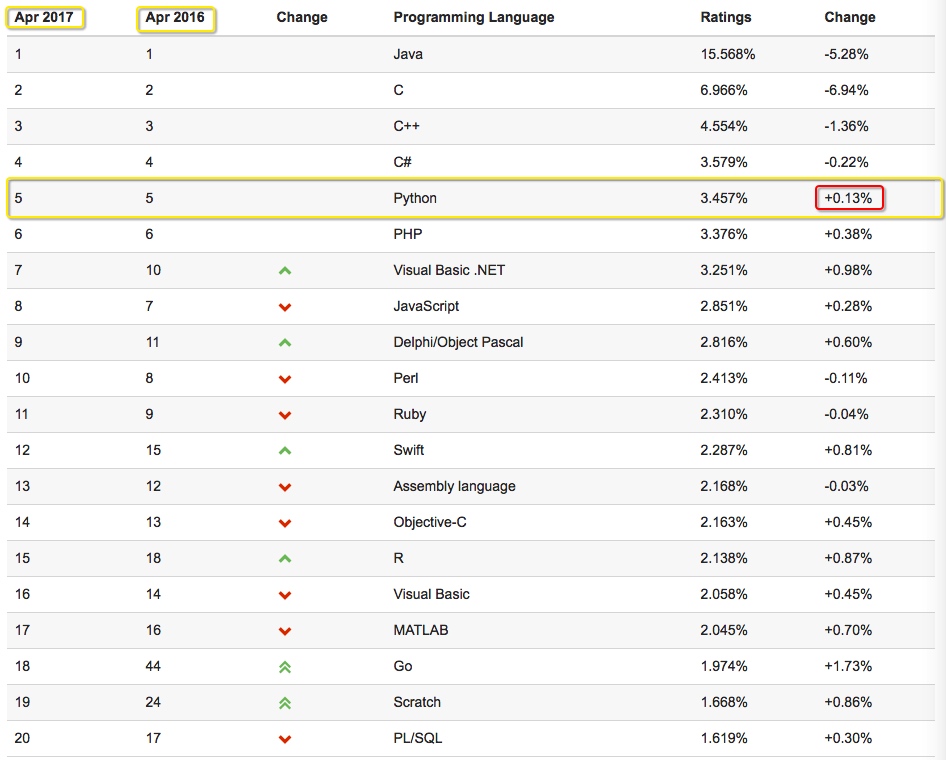
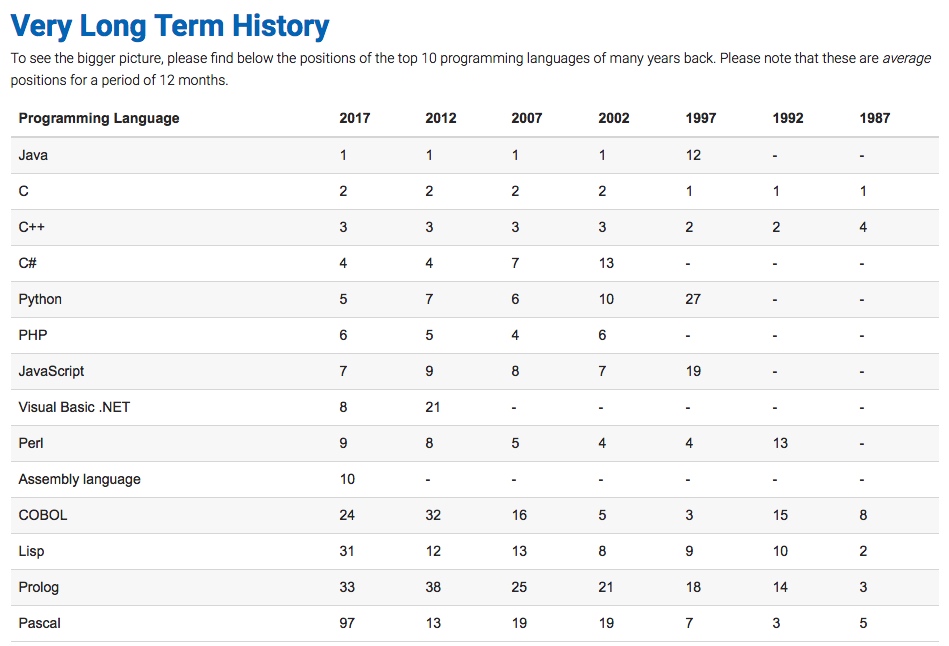
由上图17年预测可见,Python整体呈上升趋势,反映出Python应用越来越广泛并且也逐渐得到大家的认知和认可,影响度也越来越大,在国内Python开发招聘的岗位也越来越多,我们来看看2017年100offer统计情况: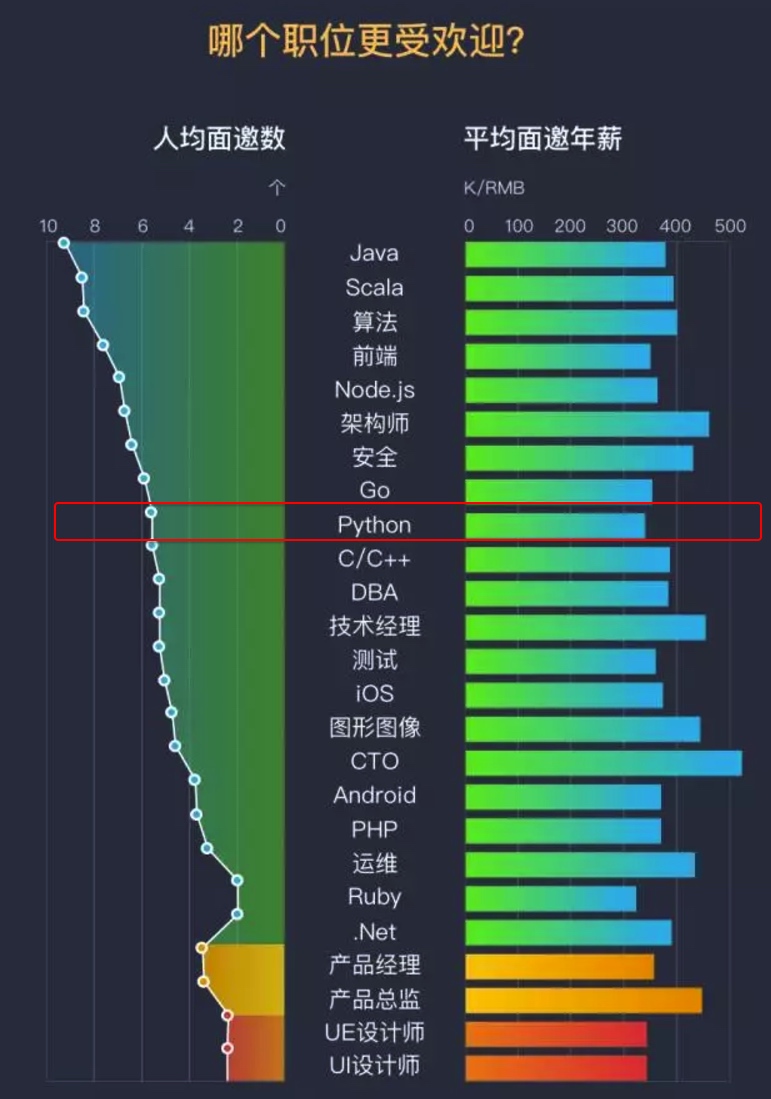
从上图我们可以看出Python的人均面邀数为6,整体年薪在34w左右,在职位招聘排行榜前十名,应该还算不错的表现哦。
三、Python的应用领域
Python可以应用于众多领域,如:数据分析、组件集成、网络服务、图像处理、数值计算和科学计算等众多领域。
目前业内几乎所有大中型互联网企业都在使用Python,如:Youtube、Dropbox、BT、Quora(中国知乎)、豆瓣、知乎、Google、Yahoo!、Facebook、NASA、阿里、百度、腾讯、汽车之家、美团等。
目前Python主要的应用领域
云计算: 在云计算领域Python可谓有一席之地, 典型应用OpenStack这个大体量的开源云计算产品就是居于Python开发的。
WEB开发: 已有众多大型网站均为Python开发,Youtube, Dropbox, 豆瓣, 知乎等…., Python也有许多Web开发框架,典型WEB框架有Django、Pylons,还有Tornado、Bottle、Flask等。
系统运维: 从国内的趋势来看,掌握一门编程语言已经成为了必然的结果,Python在国内已经成为了首选,不管是做自动化运维还是业务运维现在Python在运维领域已经应用极广。
金融:量化交易,金融分析,在金融工程领域,Python不但在用,且用的最多,而且重要性逐年提高。原因:作为动态语言的Python,语言结构清晰简单,库丰富,成熟稳定,科学计算和统计分析都很牛逼,生产效率远远高于c,c++,java,尤其擅长策略回测
图形GUI: PyQT, WxPython, TkInter, PySide等在图形用户接口领域都有广泛被应用。
哪些公司在用Python
谷歌:Google App Engine 、code.google.com 、Google earth 、谷歌爬虫、Google广告等项目都在大量使用Python开发。
CIA: 美国中情局网站就是用Python开发的。
NASA: 美国航天局(NASA)大量使用Python进行数据分析和运算。
YouTube:世界上最大的视频网站YouTube就是用Python开发的。
Dropbox:美国最大的在线云存储网站,全部用Python实现,每天网站处理10亿个文件的上传和下载。
Instagram:美国最大的图片分享社交网站,每天超过3千万张照片被分享,全部用python开发。
Facebook:大量的基础库均通过Python实现的
Redhat: 世界上最流行的Linux发行版本中的yum包管理工具就是用python开发的
豆瓣: 公司几乎所有的业务均是通过Python开发完成的。
知乎: 国内最大的问答社区,通过Python开发(国外Quora)
春雨医生:国内知名的在线医疗网站是用Python开发的
除上面之外,还有搜狐、金山、腾讯、盛大、网易、百度、阿里、淘宝 、土豆、新浪、果壳等公司都在使用Python完成各种各样的任务, 互联网公司广泛使用Python来做的事一般有:自动化运维、自动化测试、大数据分析、爬虫、Web 等。
为什么是Python而不是其他语言呢?
C 和 Python、Java、C#等
C语言: 代码编译得到 机器码 ,机器码在处理器上直接执行,每一条指令控制CPU工作
其他语言: 代码编译得到 字节码 ,虚拟机执行字节码并转换成机器码再后在处理器上执行
Python和C Python这门语言是由C开发而来
对于使用:Python的类库齐全并且使用简洁,如果要实现同样的功能,Python 10行代码可以解决,C可能就需要100行甚至更多.
对于速度:Python的运行速度相较与C,绝逼是慢了
Python 和 Java、C#等
对于使用:Linux原装Python,其他语言没有;以上几门语言都有非常丰富的类库支持
对于速度:Python在速度上可能稍显逊色
Python和PHP相比
Python提供了丰富的数据结构,非常容易和c集成。相比较而言,php集中专注在web上。 php大多只提供了系统api的简单封装,但是python标准包却直接提供了很多实用的工具。python的适用性更为广泛,php在web更加专业,php的简单数据类型,完全是为web量身定做。
所以,Python和其他语言没有什么本质区别,其他区别在于:擅长某领域、人才丰富、先入为主。语言是死的,每个语言的诞生都有它的道理,所以选择你喜欢的,开心的玩起来。
收起阅读 »敏捷为什么要使用Scrum而不是瀑布?
Scrum方法需要改变传统方法的思维方式。中心焦点已经从瀑布方法的范围转变为在Scrum中实现最大的商业价值。
在瀑布中,改变成本和进度以确保达到预期的范围,在Scrum中,可以改变质量和约束以实现获得最大商业价值的主要目标。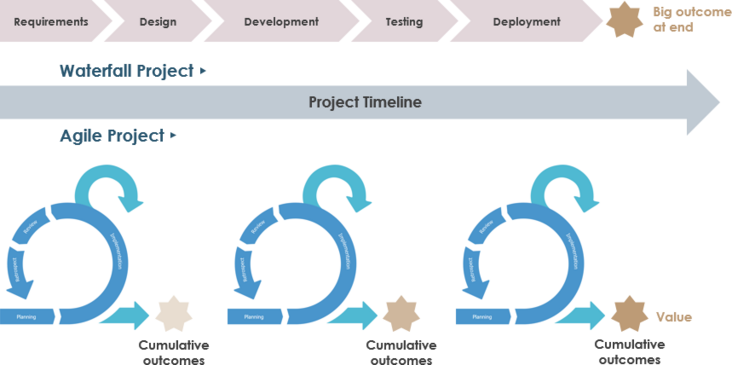
瀑布模型适用于有序和可预测的项目,其中所有要求都明确定义并且可以准确估计,并且在大多数行业中,此类项目正在减少。客户需求的变化导致企业适应和改变其交付方式的压力增大。
Scrum方法在当前市场中更为成功,其特点是不可预测性和波动性。Scrum方法基于inspect-adapt循环,而不是Waterfall方法的命令和控制结构。
Scrum项目以迭代方式完成,其中首先完成具有最高业务价值的功能。各个跨职能团队在Sprint中并行工作,以便在每个Sprint结束时提供潜在的可交付解决方案。
因为每次迭代都会产生可交付的解决方案(这是整个产品的一部分),所以团队必须实现可衡量的目标。这可确保团队正在进行,项目将按时完成。传统方法没有提供这种及时的检查,因此导致团队可能会下班并最终完成大量工作。
当客户定期与团队互动时,定期审查完成的工作; 因此,可以确保进度符合客户的要求。然而,在瀑布中没有这样的交互,因为工作是在筒仓中进行的,并且在项目结束之前没有可用的功能。
在复杂的项目中,客户不清楚他们在最终产品中需要什么,并且功能需求不断变化,迭代模型可以更灵活地确保在项目完成之前可以包含这些更改。
但是,当完成具有明确定义的功能的简单项目,并且当团队具有完成此类项目的先前经验(因此,估计将是准确的)时,瀑布方法可以是成功的。
敏捷 Vs 瀑布
下面是一个表格,可以更好地了解Scrum和瀑布的差异。
敏捷还是瀑布?
Standish Group的最新报告涵盖了他们在2013年至2017年期间研究的项目。在这段时间内,敏捷和瀑布的成功,挑战和失败的整体突破如下所示,敏捷项目成功的可能性大约是后者的2倍,失败的可能性降低1/3。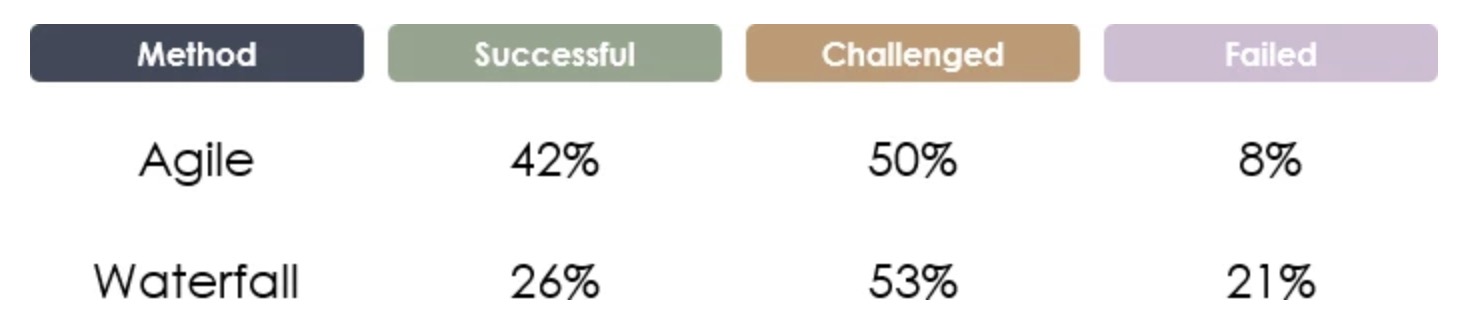
来源:vitalitychicago.com - 比较瀑布和敏捷项目成功率
分享阅读: https://henduan.com/Aynya
收起阅读 »cmake编译程序设置动态链接库加载路径
编译运行的程序需要链接到程序所在路径下的某些个动态库,为方便移植,必须设置链接库的相对路径,比如./lib等等。默认在Linux系统下动态库的搜寻路径如下:
- 使用选项
-Wl,-rpath在编译时指定; - 通过配置
LD_LIBRARY_PATH来指定; - 在
/lib和/usr/lib中查找;
其中第一个在gcc编译选项中添加:-Wl,rpath=xxx会将rpath路径写入到程序中保存起来。
为了方便移植运行一些编译安装的应用程序,在编译的时候需要设置链接库读取的相对路径目录, 比如../lib 或者./lib。
默认在Linux系统下动态库的搜寻路径如下:
- 使用选项
-Wl,-rpath在编译时指定rpath; - 通过配置
LD_LIBRARY_PATH来指定,运行加载; - 在
/lib和/usr/lib等系统默认动态库路径中查找。
其中第一个在gcc编译选项中添加:-Wl,rpath=xxx会将rpath路径写入到程序中保存起来。
以下两种方式都可以用来配置rpath路径。
1、使用gcc编译选项:
add_definitions(-std=c++11)
SET(CMAKE_CXX_FLAGS_DEBUG "$ENV{CXXFLAGS} -O0 -Wall -g -ggdb -Wl,-rpath=./:./lib") #-Wl,-rpath=./
SET(CMAKE_CXX_FLAGS_RELEASE "$ENV{CXXFLAGS} -O3 -Wl,-rpath=./:./lib") #-Wall
2、使用cmake配置
set(CMAKE_SKIP_BUILD_RPATH FALSE)
set(CMAKE_BUILD_WITH_INSTALL_RPATH TRUE)
set(CMAKE_INSTALL_RPATH_USE_LINK_PATH TRUE)
set(CMAKE_INSTALL_RPATH "./lib")
或者
SET(CMAKE_SKIP_BUILD_RPATH FALSE)
SET(CMAKE_BUILD_WITH_INSTALL_RPATH FALSE)
SET(CMAKE_INSTALL_RPATH "${CMAKE_INSTALL_PREFIX}/lib:$ORIGIN/lib")
SET(CMAKE_INSTALL_RPATH_USE_LINK_PATH TRUE)
其中RPATH可以使用"./lib"或"./"配置,有可以使用"$ORIGIN/lib"或"\${ORIGIN}/lib",这里必须加上\符号,否则无法识别。
还可以同时定义多个RPATH,比如:"$ORIGIN:$ORIGIN/lib",中间使用:分割。
参考:https://blog.csdn.net/wh8_2011/article/details/79519293
CMAKE和RPATH:https://blog.csdn.net/zhangzq86/article/details/80718559
CMAKE中RPATH的用法:https://blog.csdn.net/z296671124/article/details/86699720
Linux C编程使用相对路径加载动态库: https://blog.csdn.net/dreamcs/article/details/52138229
每个伟大的产品需要一个伟大的ScrumMaster
摘要
产品负责人和ScrumMaster是两个相互补充的独立敏捷角色。 为了出色地完成工作,产品所有者需要在他们身边强大的ScrumMaster。
不幸的是,我发现通常缺少可以支持产品所有者的ScrumMaster。 有时角色之间会混淆,或者根本没有ScrumMaster。
这篇文章解释了这两个角色之间的区别,产品所有者应该从他们的ScrumMaster中获得什么,以及ScrumMasters从他们中可以期待什么。
产品负责人与ScrumMaster
产品负责人和ScrumMaster是相互补充的两个不同角色。 如果其中一个位置不正确,则另一个会受到影响。 作为产品负责人 ,您应对产品的成功负责-创造一种对用户和客户的工作都非常出色并满足其业务目标的产品。 因此,您可以与用户和客户以及内部利益相关者,开发团队和ScrumMaster进行交互,如下图所示。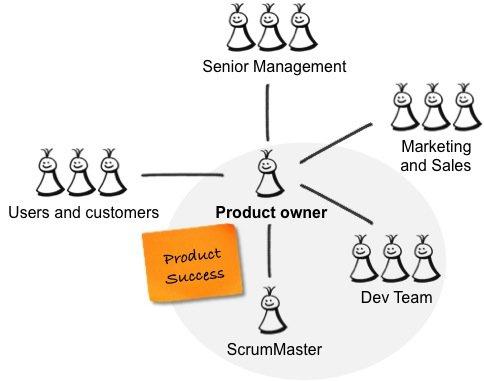
上图中的灰色圆圈描述了由产品所有者,ScrumMaster和跨功能开发团队组成的Scrum团队。
ScrumMaster负责流程的成功 -帮助产品负责人和团队使用正确的流程来创建成功的产品,并促进组织变革和建立敏捷的工作方式。 因此,ScrumMaster与产品所有者和开发团队以及受Scrum影响的高级管理层,人力资源(HR)和业务组合作,如下图所示: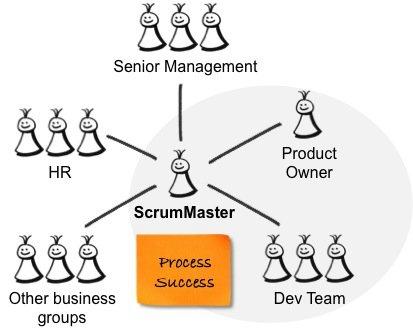
要成功成为产品负责人,需要正确的技能,时间,精力和重点。 扮演ScrumMaster角色也是如此。 将这两个角色(甚至是部分角色)组合在一起不仅非常具有挑战性,而且意味着忽略了某些职责。 如果您是产品所有者,请不要承担ScrumMaster的职责!
产品负责人对ScrumMaster的期望
作为产品所有者,您应该从以下几种方面受益于ScrumMaster的工作。 ScrumMaster应该指导团队,以便团队成员可以构建出色的产品,促进组织变革,以便组织利用Scrum并帮助您完成出色的工作: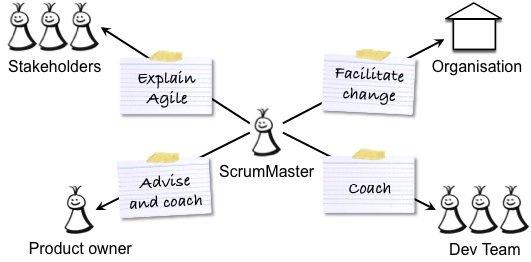
下表详细说明了您应该从ScrumMaster获得的支持:
ScrumMaster支持您作为产品所有者,因此您可以专注于自己的工作-确保创建具有正确用户体验(UX)和正确功能的正确产品。 如果您的ScrumMaster不提供或无法提供此支持,请与个人联系,并找出问题所在。 不要介入并接管ScrumMaster的工作。 如果您没有ScrumMaster,请将上面的列表显示给您的高级管理层赞助商或老板,以解释为什么您需要身边有合格的ScrumMaster。
ScrumMaster应该对产品负责人有什么期望
Tango花了两个时间,ScrumMaster对您作为产品所有者的工作抱有期望,这是公平的。 下图说明了其中的一些:
下表更详细地描述了ScrumMaster的期望:
英文原文: https://henduan.com/1pjvW
收起阅读 »Scrum是一个用于开发和维护复杂产品的框架
Scrum是一个用于开发和维护复杂产品的框架 ,是一个增量的、迭代的开发过程。在这个框架中,整个开发过程由若干个短的迭代周期组成,一个短的迭代周期称为一个Sprint,每个Sprint的建议长度是2到4周(互联网产品研发可以使用1周的Sprint)。
在Scrum中,使用产品Backlog来管理产品的需求,产品backlog是一个按照商业价值排序的需求列表,列表条目的体现形式通常为用户故事。Scrum团队总是先开发对客户具有较高价值的需求。在Sprint中,Scrum团队从产品Backlog中挑选最高优先级的需求进行开发。
挑选的需求在Sprint计划会议上经过讨论、分析和估算得到相应的任务列表,我们称它为Sprint backlog。在每个迭代结束时,Scrum团队将递交潜在可交付的产品增量。 Scrum起源于软件开发项目,但它适用于任何复杂的或是创新性的项目。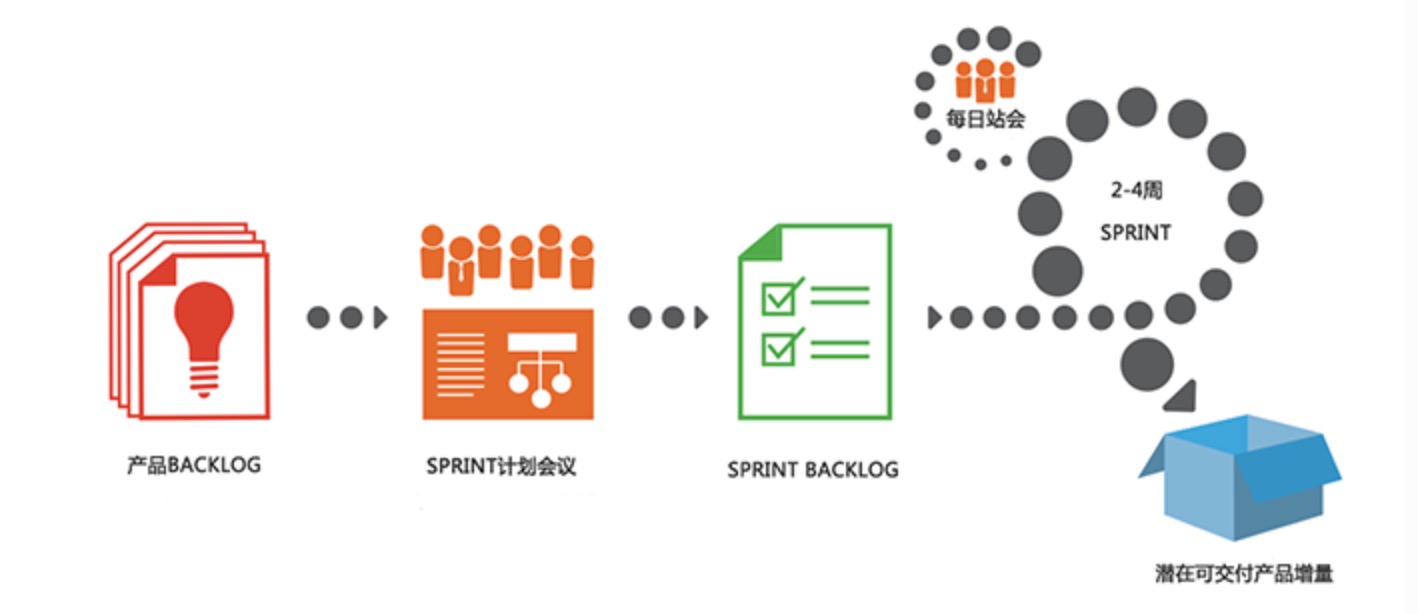
SCRUM框架包括3个角色、3个工件、5个事件、5个价值
3个角色
- 产品负责人(Product Owner)
- Scrum Master
- 开发团队
3个工件
- 产品Backlog(Product Backlog)
- SprintBacklog
- 产品增量(Increment)
5个事件
- Sprint(Sprint本身是一个事件,包括了如下4个事件)
- Sprint计划会议(Sprint Planning Meeting)
- 每日站会(Daily Scrum Meeting)
- Sprint评审会议(Sprint Review Meeting)
- Sprint回顾会议(Sprint Retrospective Meeting)
5个价值
- 承诺 – 愿意对目标做出承诺
- 专注– 把你的心思和能力都用到你承诺的工作上去
- 开放– Scrum 把项目中的一切开放给每个人看
- 尊重– 每个人都有他独特的背景和经验
- 勇气– 有勇气做出承诺,履行承诺,接受别人的尊重
SCRUM理论基础
Scrum以经验性过程控制理论(经验主义)做为理论基础的过程。经验主义主张知识源于经验, 以及基于已知的东西做决定。Scrum 采用迭代、增量的方法来优化可预见性并控制风险。
Scrum 的三大支柱支撑起每个经验性过程控制的实现:透明性、检验和适应。Scrum的三大支柱如下:
第一:透明性(Transparency)
透明度是指,在软件开发过程的各个环节保持高度的可见性,影响交付成果的各个方面对于参与交付的所有人、管理生产结果的人保持透明。管理生产成果的人不仅要能够看到过程的这些方面,而且必须理解他们看到的内容。也就是说,当某个人在检验一个过程,并确信某一个任务已经完成时,这个完成必须等同于他们对完成的定义。
第二:检验(Inspection)
开发过程中的各方面必须做到足够频繁地检验,确保能够及时发现过程中的重大偏差。在确定检验频率时,需要考虑到检验会引起所有过程发生变化。当规定的检验频率超出了过程检验所能容许的程度,那么就会出现问题。幸运的是,软件开发并不会出现这种情况。另一个因素就是检验工作成果人员的技能水平和积极性。
第三:适应(Adaptation)
如果检验人员检验的时候发现过程中的一个或多个方面不满足验收标准,并且最终产品是不合格的,那么便需要对过程或是材料进行调整。调整工作必须尽快实施,以减少进一步的偏差。
Scrum中通过三个活动进行检验和适应:每日例会检验Sprint目标的进展,做出调整,从而优化次日的工作价值;Sprint评审和计划会议检验发布目标的进展,做出调整,从而优化下一个Sprint的工作价值;Sprint回顾会议是用来回顾已经完成的Sprint,并且确定做出什么样的改善可以使接下来的Sprint更加高效、更加令人满意,并且工作更快乐。
全文阅读:https://www.scrumcn.com/agile/scrum-knowledge-library/scrum.html
收起阅读 »Go模块代理大全
1.GoProxy
官网地址: https://www.goproxy.io/zh/
Bash (Linux or macOS):
# 配置 GOPROXY 环境变量
export GOPROXY=https://goproxy.io,direct
# 还可以设置不走 proxy 的私有仓库或组,多个用逗号相隔(可选)
export GOPRIVATE=git.mycompany.com,github.com/my/private
PowerShell (Windows)
# 配置 GOPROXY 环境变量
$env:GOPROXY = "https://goproxy.io,direct"
# 还可以设置不走 proxy 的私有仓库或组,多个用逗号相隔(可选)
$env:GOPRIVATE = "git.mycompany.com,github.com/my/private"
设置完上面几个环境变量后,您的 go 命令将从公共代理镜像中快速拉取您所需的依赖代码了。或者,还可以根据文档进行设置使其长期生效。如果您使用的是老版本的 Go(< 1.13), 我们建议您升级为最新稳定版本。
2.七牛GoProxy中国
官网地址:https://goproxy.cn/
Go 1.13 及以上(推荐),打开你的终端并执行
$ go env -w GO111MODULE=on
$ go env -w GOPROXY=https://goproxy.cn,direct
macOS 或 Linux
$ export GO111MODULE=on
$ export GOPROXY=https://goproxy.cn
或者
$ echo "export GO111MODULE=on" >> ~/.profile
$ echo "export GOPROXY=https://goproxy.cn" >> ~/.profile
$ source ~/.profile
Windows, 打开你的 PowerShell 并执行
C:\> $env:GO111MODULE = "on"
C:\> $env:GOPROXY = "https://goproxy.cn"
或者
1. 打开“开始”并搜索“env”
2. 选择“编辑系统环境变量”
3. 点击“环境变量…”按钮
4. 在“<你的用户名> 的用户变量”章节下(上半部分)
5. 点击“新建…”按钮
6. 选择“变量名”输入框并输入“GO111MODULE”
7. 选择“变量值”输入框并输入“on”
8. 点击“确定”按钮
9. 点击“新建…”按钮
10. 选择“变量名”输入框并输入“GOPROXY”
11. 选择“变量值”输入框并输入“https://goproxy.cn”
12. 点击“确定”按钮
3.百度Go Module代理
官网地址: https://goproxy.baidu.com/
简介:go module公共代理仓库,代理并缓存go模块。你可以利用该代理来避免DNS污染导致的模块拉取缓慢或失败的问题,加速你的构建
1.使用go1.11以上版本并开启go module机制
export GOPROXY=https://goproxy.baidu.com/ ## 配置GOPROXY环境变量
2.使用go1.13以上版本
go env -w GONOPROXY=\*\*.baidu.com\*\* ## 配置GONOPROXY环境变量,所有百度内代码,不走代理
go env -w GONOSUMDB=\* ## 配置GONOSUMDB,暂不支持sumdb索引
go env -w GOPROXY=https://goproxy.baidu.com ## 配置GOPROXY,可以下载墙外代码
4.阿里云Go Module代理
官网:http://mirrors.aliyun.com/goproxy/
1.使用go1.11以上版本并开启go module机制
2.导出GOPROXY环境变量
export GOPROXY=https://mirrors.aliyun.com/goproxy/
官网安装包国内下载地址
- Go中文社区:https://studygolang.com/dl
- Gomirrors: https://gomirrors.org/
Go交叉编译的那些事
最近两个月,一直在搞项目的国产化移植,把golang开发好的程序,运行在国产化平台上,操作系统基本都是基于Linux,但是CPU架构除了x86,还有ARM和MIPS,我们平时的Golang都是运行于x86 && x64 架构的CPU上,因此移植过程中遇到了好多坑,记录于此。
Golang交叉编译
交叉编译
在X64上的ubuntu 16.04系统上编译出其他平台的可执行程序, 查看Golang支持的平台和版本:
go tool dist list
此命令会列出所有go语言支持的操作系统和cpu架构
aix/ppc64
android/386
android/amd64
android/arm
android/arm64
darwin/amd64
darwin/arm64
dragonfly/amd64
freebsd/386
freebsd/amd64
freebsd/arm
freebsd/arm64
illumos/amd64
js/wasm
linux/386
linux/amd64
linux/arm
linux/arm64
linux/mips
linux/mips64
linux/mips64le
linux/mipsle
linux/ppc64
linux/ppc64le
linux/riscv64
linux/s390x
netbsd/386
netbsd/amd64
netbsd/arm
netbsd/arm64
openbsd/386
openbsd/amd64
openbsd/arm
openbsd/arm64
plan9/386
plan9/amd64
plan9/arm
solaris/amd64
windows/386
windows/amd64
windows/arm
其实go的交叉编译非常简单,只需要在编译前指定系统和CPU架构,基本不会有任何问题,编译出来将文件拷贝到对应平台就能跑:
GOOS=linux GOARCH=arm64 go build xxx.go
# 有时候需要加上CGO_ENABLE=0
CGO_ENABLE=0 GOOS=linux GOARCH=arm64 go build xxx.go
go语言的交叉编译支持非常好,只要按照上述步骤基本不会出什么问题。坑,主要就坑在cgo, CGO_ENABLED=0 关闭cgo。
采用cgo的交叉编译
使用cgo,就必须指定CGO_ENABLE=1。并且必须指定CC参数为对应架构的gcc的交叉编译器。
假设我们编译64位ARM平台的程序,就要提前下载aarch64版本的c++交叉编译工具
CGO_ENABLED=1 GOOS=linux GOARCH=arm64 CC=./aarch64-unknown-linux-gnueabi-5.4.0-2.23-4.4.6/bin/aarch64-unknown-linux-gnueabi-gcc go build xxx.go
如果调用的CGO调用的C程序中依赖各种库,那么这个编译过程会报错各种依赖的库not found,各种基本的函数未定义。而且都是系统中最基本的库如libglibc、libgstream等。
解决方案是必须在编译时,加上链接库的参数,而链接的库必须是交叉编译出的目标平台的系统库而不是当前系统的。
这个在下载交叉编译工具链的时候,一般都会附带,我这里放到系统根目录下,然后通过C++编译时链接库的语法将库链接进去:
主要是三个参数:-I , -isystem , -L, -l
下面命令是个例子,假设项目中用到了phnono、curl、protobuf等组件:
CGO_ENABLED=1 GOOS=linux GOARCH=arm64 CC=./aarch64-unknown-linux-gnueabi-5.4.0-2.23-4.4.6/bin/aarch64-unknown-linux-gnueabi-gcc -Wall -std=c++11 -Llib -isystem/aarch64/usr/include -L/aarch64/lib -ldl -lpthread -Wl,-rpath-link,/aarch64/lib -L/aarch64/lib/aarch64-linux-gnu -L/aarch64/usr/lib -I/aarch64/usr/include -L/aarch64/usr/lib/aarch64-linux-gnu -ldl -lpthread -Wl,-rpath-link,/aarch64/usr/lib/aarch64-linux-gnu -lphonon -lcurl -lprotobuf go build xxx.go
到这一步,就基本解决了无法编译的坑。
平台差异的问题
在编译ARM版本的代码时,报错好几个系统调用找不到:
- undefined: syscall.Dup2
- undefined: syscall.SYS_FORK
解决方案:对比golang源码实现:go/src/syscall/zsyscall_linux_amd64.go和go/src/syscall/zsyscall_linux_arm64.go,发现arm平台未实现Dup2但是提供了Dup3,参数略有差异,解决办法是修改调用的地方:
// - syscall.Dup2(oldfd, newfd) 修改为:
syscall.Dup3(oldfd,newfd,0)
而SYS_FORK的调用,查找之下发现golang的ARM实现根本没有实现fork的系统调用,没有SYS_FORK这个宏或替代品。
无奈只能修改项目代码,将fork的系统调用改为别的方式实现。
MIPS的大小端问题
报错:go.o: compiled for a big endian system and target is little endian
主要体现在大小端字节序的问题,这是我在交叉编译Mips版本发现的一个问题,仔细查看了我的编译命令发现:
CGO_ENABLED=1 GOOS=linux GOARCH=mips64 CC=./mips64el-unknown-linux-gnu-5.4.0-2.12-2.6.32/bin/mips64el-unknown-linux-gnu-gcc go build xxx.go
这里的命令中:CC指定的是mips64el的编译器,el代表小端字节序,而GOARCH=mips64这是大端字节序,前后不一致导致编译的报错,
解决方案:go和gcc保持统一、以目标平台为准(龙芯是小端字节序)
- 将GOARCH指定为mips64le(注意是le不是el)
- 最好加上LDFLAG=-EL
CGO_ENABLED=1 GOOS=linux GOARCH=mips64le CC=./mips64el-unknown-linux-gnu-5.4.0-2.12-2.6.32/bin/mips64el-unknown-linux-gnu-gcc LDFLAGS=-EL go build xxx.go
总结经验:
1. golang程序开发少用原生的系统调用syscall
2. 能用go解决的,尽可能不要用cgo
3. 如果有模块必须通过C/C++调用,推荐C++和golang分离,C++和Golang程序间使用socket等方式进行进程间通信
分享阅读原文:https://henduan.com/wNyCI
收起阅读 »Go进阶笔记-并发编程
goroutine
Go 语言层面支持的 go 关键字,可以快速的让一个函数创建为 goroutine,我们可以认为 main 函数就是作为 goroutine 执行的。操作系统调度线程在可用处理器上运行,Go运行时调度 goroutines 在绑定到单个操作系统线程的逻辑处理器中运行(P)。即使使用这个单一的逻辑处理器和操作系统线程,也可以调度数十万 goroutine 以惊人的效率和性能并发运行。
并发不是并行。并行是指两个或多个线程同时在不同的处理器执行代码。如果将运行时配置为使用多个逻辑处理器,则调度程序将在这些逻辑处理器之间分配 goroutine,这将导致 goroutine 在不同的操作系统线程上运行。但是,要获得真正的并行性,您需要在具有多个物理处理器的计算机上运行程序。否则,goroutines 将针对单个物理处理器并发运行,即使 Go 运行时使用多个逻辑处理器。
虽然go 开启一个goroutine很方便,但是这并意味着我们可以不过脑子的随便go,我们每次go开启一个goroutine都要思考如下问题:
- 它什么时候会退出?
- 如何能够让它结束?
- 把并发交给调用者!
初学者写go代码的时候经常可能是如下例子:
package main
import (
"fmt"
"net/http"
)
func main() {
mux := http.NewServeMux()
mux.HandleFunc("/", func(rw http.ResponseWriter, r *http.Request) {
fmt.Println(rw, "Hello Golang")
})
go http.ListenAndServe("127.0.0.1:8080", http.DefaultServeMux)
http.ListenAndServe("127.0.0.1:9090", mux)
}
这里很明显我们对go开启的goroutine 是不能能知道它什么时候会退出的,并且我们也没有一个好的办法让它退出,优雅的代码应该如下:
package main
import (
"context"
"fmt"
"net/http"
)
func serverApp(stop <-chan struct{}) error {
mux := http.NewServeMux()
mux.HandleFunc("/", func(rw http.ResponseWriter, r *http.Request) {
fmt.Println(rw, "Hello Golang")
})
s := http.Server{
Addr: "0.0.0.0:8080",
Handler: mux,
}
go func() {
<-stop
s.Shutdown(context.Background())
}()
return s.ListenAndServe()
}
func serverDebug(stop <-chan struct{}) error {
s := http.Server{
Addr: "0.0.0.0:9090",
Handler: http.DefaultServeMux,
}
go func() {
<-stop
s.Shutdown(context.Background())
}()
return s.ListenAndServe()
}
func main() {
done := make(chan error, 2)
stop := make(chan struct{})
go func() {
done <- serverApp(stop)
}()
go func() {
done <- serverDebug(stop)
}()
var stoped bool
for i := 0; i < cap(done); i++ {
if err := <-done; err != nil {
fmt.Printf("error:%v\n", err)
}
if !stoped {
stoped = true
close(stop)
}
}
}
我们再看一个例子:
type Tracker struct{}
func (t *Tracker) Event(data string) {
time.Sleep(time.Microsecond)
log.Println(data)
}
type App struct {
track Tracker
}
func (a *App) Handle(w http.ResponseWriter, r *http.Request) {
// do some work
w.WriteHeader(http.StatusCreated)
// 这个地方其实是有问题的
go a.track.Event("test event")
}
还是同样的,重要的事情先思考如下问题:
- 它什么时候会退出?
- 如何能够让它结束?
- 把并发交给调用者!
显然上面的代码是不满足的,更改之后如下:
package main
import (
"context"
"fmt"
"time"
)
func main() {
tr := NewTracker()
go tr.Run()
_ = tr.Event(context.Background(), "test1")
_ = tr.Event(context.Background(), "test2")
_ = tr.Event(context.Background(), "test3")
_ = tr.Event(context.Background(), "test4")
_ = tr.Event(context.Background(), "test5")
_ = tr.Event(context.Background(), "test6")
ctx, cancel := context.WithDeadline(context.Background(), time.Now().Add(3*time.Second))
defer cancel()
tr.Shutdown(ctx)
}
type Tracker struct {
ch chan string
stop chan struct{}
}
func NewTracker() *Tracker {
return &Tracker{
ch: make(chan string, 10),
}
}
func (t *Tracker) Event(ctx context.Context, data string) error {
select {
case t.ch <- data:
return nil
case <-ctx.Done():
return ctx.Err()
}
}
func (t *Tracker) Run() {
for data := range t.ch {
time.Sleep(1 * time.Second)
fmt.Println(data)
}
t.stop <- struct{}{}
}
func (t *Tracker) Shutdown(ctx context.Context) {
close(t.ch)
select {
case <-t.stop:
case <-ctx.Done():
}
}
sync
Go 的并发原语 goroutines 和 channels 为构造并发软件提供了一种优雅而独特的方法。
在Go中如果我们写完代码想要对代码是否存在数据竞争进行检查,可以通过go build -race 对程序进行编译
package main
import (
"fmt"
"sync"
)
var Wait sync.WaitGroup
var Counter int = 0
func main() {
for routine := 1; routine <= 2; routine++ {
Wait.Add(1)
go Routine()
}
Wait.Wait()
fmt.Printf("Final Counter:%d\n", Counter)
}
func Routine() {
Counter++
Wait.Done()
}
go build -race 编译后的程序,运行可以很方便看到代码中存在的问题
==================
WARNING: DATA RACE
Read at 0x000001277ce0 by goroutine 8:
main.Routine()
/Users/zhaofan/open_source_study/test_code/202012/race/main.go:21 +0x3e
Previous write at 0x000001277ce0 by goroutine 7:
main.Routine()
/Users/zhaofan/open_source_study/test_code/202012/race/main.go:21 +0x5a
Goroutine 8 (running) created at:
main.main()
/Users/zhaofan/open_source_study/test_code/202012/race/main.go:14 +0x6b
Goroutine 7 (finished) created at:
main.main()
/Users/zhaofan/open_source_study/test_code/202012/race/main.go:14 +0x6b
==================
Final Counter:2
Found 1 data race(s)
对于锁的使用: 最晚加锁,最早释放。
对于下面这段代码,这是模拟一个读多写少的情况,正常情况下,每次读到cfg中的数字都应该是依次递增加1的,但是如果运行代码,则会发现,会出现意外的情况。
package main
import (
"fmt"
"sync"
)
var wg sync.WaitGroup
type Config struct {
a []int
}
func main() {
cfg := &Config{}
// 这里模拟数据的变化
go func() {
i := 0
for {
i++
cfg.a = []int{i, i + 1, i + 2, i + 3, i + 4, i + 5}
}
}()
// 这里模拟去获取数据
var wg sync.WaitGroup
for n := 0; n < 4; n++ {
wg.Add(1)
go func() {
for n := 0; n < 20; n++ {
fmt.Printf("%v\n", cfg)
}
wg.Done()
}()
}
wg.Wait()
}
对于上面这个代码的解决办法有很多
- Mutex
- RWMutext
- Atomic
对于这种读多写少的情况,使用RWMutext或Atomic 都可以解决,这里只写写一个两者的对比,通过测试也很容易看到两者的性能差别:
package main
import (
"sync"
"sync/atomic"
"testing"
)
type Config struct {
a []int
}
func (c *Config) T() {
}
func BenchmarkAtomic(b *testing.B) {
var v atomic.Value
v.Store(&Config{})
go func() {
i := 0
for {
i++
cfg := &Config{a: []int{i, i + 1, i + 2, i + 3, i + 4, i + 5}}
v.Store(cfg)
}
}()
var wg sync.WaitGroup
for n := 0; n < 4; n++ {
wg.Add(1)
go func() {
for n := 0; n < b.N; n++ {
cfg := v.Load().(*Config)
cfg.T()
// fmt.Printf("%v\n", cfg)
}
wg.Done()
}()
}
wg.Wait()
}
func BenchmarkMutex(b *testing.B) {
var l sync.RWMutex
var cfg *Config
go func() {
i := 0
for {
i++
l.RLock()
cfg = &Config{a: []int{i, i + 1, i + 2, i + 3, i + 4, i + 5}}
cfg.T()
l.RUnlock()
}
}()
var wg sync.WaitGroup
for n := 0; n < 4; n++ {
wg.Add(1)
go func() {
for n := 0; n < b.N; n++ {
l.RLock()
cfg.T()
l.RUnlock()
}
wg.Done()
}()
}
wg.Wait()
}
从结果来看性能差别还是非常明显的:
zhaofan@zhaofandeMBP ~/open_source_study/test_code/202012/atomic_ex2 go test -bench=. config_test.go
goos: darwin
goarch: amd64
BenchmarkAtomic-4 310045898 3.91 ns/op
BenchmarkMutex-4 11382775 101 ns/op
PASS
ok command-line-arguments 3.931s
zhaofan@zhaofandeMBP ~/open_source_study/test_code/202012/atomic_ex2
Mutext锁的实现有一下几种模式:
- Barging, 这种模式是为了提高吞吐量,当锁释放时,它会唤醒第一个等待者,然后把锁给第一个等待者或者第一个请求锁的人。注意这个时候释放锁的那个goroutine 是不会保证下一个人一定能拿到锁,可以理解为只是告诉等待的那个人,我已经释放锁了,快去抢吧。
- Handsoff,当释放锁的时候,锁会一直持有直到第一个等待者准备好获取锁,它降低了吞吐量,因为锁被持有,即使另外一个goroutine准备获取它。相对Barging,这种在释放锁的时候回问下一个要获取锁的,你准备好了么,准备好了我就把锁给你了。
- Spinning,自旋在等待队列为空或者应用程序重度使用锁时效果不错,parking和unparking goroutines 有不低的性能成本开销,相比自旋来说要慢的多。
Go 1.8 使用了Bargin和Spinning的结合实现。当试图获取已经被持有的锁时,如果本地队列为空并且P的数量大于1,goroutine 将自旋几次(用一个P旋转会阻塞程序),自旋后,goroutine park 在程序高频使用锁的情况下,它充当了一个快速路径。
Go1.9 通过添加一个新的饥饿模式来解决出现锁饥饿的情况,该模式将会在释放的时候触发handsoff, 所有等待锁超过一毫秒的goroutine(也被称为有界等待)将被诊断为饥饿,当被标记为饥饿状态时,unlock方法会handsoff把锁直接扔给第一个等待者。
在饥饿模式下,自旋也会被停用,因为传入的goroutines将没有机会获取为下一个等待者保留的锁。
errgroup
https://pkg.go.dev/golang.org/x/sync/errgroup
使用场景,如果我们有一个复杂的任务,需要拆分为三个任务goroutine 去执行,errgroup 是一个非常不错的选择。
下面是官网的一个例子:
package main
import (
"fmt"
"golang.org/x/sync/errgroup"
"net/http"
)
func main() {
g := new(errgroup.Group)
var urls = []string{
"http://www.golang.org/",
"http://www.google.com/",
"http://www.somestupidname.com/",
}
for _, url := range urls {
// Launch a goroutine to fetch the URL.
url := url // https://golang.org/doc/faq#closures_and_goroutines
g.Go(func() error {
// Fetch the URL.
resp, err := http.Get(url)
if err == nil {
resp.Body.Close()
}
return err
})
}
// Wait for all HTTP fetches to complete.
if err := g.Wait(); err == nil {
fmt.Println("Successfully fetched all URLs.")
}
}
Sync.Poll
sync.poll的场景是用来保存和复用临时对象,减少内存分配,降低GC压力, Request-Drive 特别适合
Get 返回Pool中的任意一个对象,如果Pool 为空,则调用New返回一个新创建的对象
放进pool中的对象,不确定什么时候就会被回收掉,如果实现Put进去100个对象,下次Get的时候发现Pool是空的也是有可能的。所以sync.Pool中是不能放连接型的对象。所以sync.Pool中应该放的是任意时刻都可以被回收的对象。
sync.Pool中的这个清理过程是在每次垃圾回收之前做的,之前每次GC是都会清空pool, 而在1.13版本中引入了victim cache, 会将pool内数据拷贝一份,避免GC将其清空,即使没有引用的内容也可以保留最多两轮GC。
Context
在Go 服务中,每个传入的请求都在自己的goroutine中处理,请求处理程序通常启动额外的goroutine 来访问其他后端,如数据库和RPC服务,处理请求的goroutine通常需要访问特定于请求(request-specific context)的值,例如最终用户的身份,授权令牌和请求的截止日期。*当一个请求被取消或者超时时,处理该请求的所有goroutine都应该快速推出,这样系统就可以回收他们正在使用的任何资源。
如何将context 集成到API中?
- 首参数传递context对象
- 在第一个request对象中携带一个可选的context对象
注意:尽量把context 放到函数的首选参数,而不要把context 放到一个结构体中。
context.WithValue
为了实现不断WithValue, 构建新的context,内部在查找key时候,使用递归方式不断寻找匹配的key,知道root context(Backgrond和TODO value的函数会返回nil)
context.WithValue 方法允许上下文携带请求范围的数据,这些数据必须是安全的,以便多个goroutine同时使用。这里的数据,更多是面向请求的元数据,而不应该作为函数的可选参数来使用(比如context里挂了一个sql.Tx对象,传递到Dao层使用),因为元数据相对函数参数更多是隐含的,面向请求的。而参数更多是显示的。
同一个context对象可以传递给在不同的goroutine中运行的函数;上下文对于多个goroutine同时使用是安全的。对于值类型最容易犯错的地方,在于context value 应该是不可修改的,每次重新赋值应该是新的context,即: context.WithValue(ctx, oldvalue),所以这里就是一个麻烦的地方,如果有多个key/value ,就需要多次调用context.WithValue, 为了解决这个问题,https://pkg.go.dev/google.golang.org/grpc/metadata 在grpc源码中使用了一个metadata.
func FromIncomingContext(ctx context.Context) (md MD, ok bool) 这里的md 就是一个map type MD map[string][]string 这样对于多个key/value的时候就可以用这个MD 一次把多个对象挂进去,不过这里需要注意:如果一个groutine从ctx中读出这个map对象是不能直接修改的。因为如果这个时候ctx被传递给了多个gouroutine, 如果直接修改就会导致data race, 因此需要使用copy-on-write的思路,解决跨多个goroutine使用数据,修改数据的场景。
比如如下场景:
新建一个context.Background() 的ctx1, 携带了一个map 的数据, map中包含了k1:v1 的键值对,ctx1 作为参数传递给了两个goroutine,其中一个goroutine从ctx1中获取map1,构建一个新的map对象map2,复制所有map1的数据,同时追加新的数据k2:v2 键值对,使用context.WithValue 创建新的ctx2,ctx2 会继续传递到其他groutine中。 这样各自读取的副本都是自己的数据,写行为追加的数据在ctx2中也能完整的读取到,同时不会污染ctx1中的数据,这种处理方式就是典型的COW(COPY ON Write)
context cancel
当一个context被取消时, 从它派生的所有context也将被取消。WithCancel(ctx)参数认为是parent ctx, 在内部会进行一个传播关系链的关联。Done() 返回一个chan,当我们取消某个parent context, 实际上会递归层层cancel掉自己的chaild context 的done chan 从而让整个调用链中所有监听cancel的goroutine退出
下面是官网的例子,稍微调整了一下代码:
package main
import (
"context"
"fmt"
)
func main() {
// gen generates integers in a separate goroutine and
// sends them to the returned channel.
// The callers of gen need to cancel the context once
// they are done consuming generated integers not to leak
// the internal goroutine started by gen.
gen := func(ctx context.Context) <-chan int {
dst := make(chan int)
n := 1
go func() {
for {
select {
case <-ctx.Done():
return // returning not to leak the goroutine
case dst <- n:
n++
}
}
}()
return dst
}
ctx, cancel := context.WithCancel(context.Background())
for n := range gen(ctx) {
fmt.Println(n)
if n == 5 {
cancel()
}
}
}
如果实现一个超时控制,通过上面的context的parent/child 机制, 其实只需要启动一个定时器,然后再超时的时候,直接将当前的context给cancel掉,就可以实现监听在当前和下层的context.Done()和goroutine的退出。
package main
import (
"context"
"fmt"
"time"
)
const shortDuration = 1 * time.Millisecond
func main() {
d := time.Now().Add(shortDuration)
ctx, cancel := context.WithDeadline(context.Background(), d)
// Even though ctx will be expired, it is good practice to call its
// cancellation function in any case. Failure to do so may keep the
// context and its parent alive longer than necessary.
defer cancel()
select {
case <-time.After(1 * time.Second):
fmt.Println("overslept")
case <-ctx.Done():
fmt.Println(ctx.Err())
}
}
关于context 使用的规则总结:
- Incoming requests to a server should create a Context.
- Outgoing calls to servers should accept a Context.
- Do not store Contexts inside a struct type; instead, pass a Context explicitly to each function that needs it.
- The chain of function calls between them must propagate the Context.
- Replace a Context using WithCancel, WithDeadline, WithTimeout, or WithValue.
- When a Context is canceled, all Contexts derived from it are also canceled.
- The same Context may be passed to functions running in different goroutines; Contexts are safe for simultaneous use by multiple goroutines.
- Do not pass a nil Context, even if a function permits it. Pass a TODO context if you are unsure about which Context to use.
- Use context values only for request-scoped data that transits processes and APIs, not for passing optional parameters to functions.
- All blocking/long operations should be cancelable.
- Context.Value obscures your program’s flow.
- Context.Value should inform, not control.
- Try not to use context.Value.
Channel
channels 是一种类型安全的消息队列,充当两个 goroutine 之间的管道,将通过它同步的进行任意资源的交换。channel 控制 goroutines 交互的能力从而创建了 Go 同步机制。当创建的 channel 没有容量时,称为无缓冲通道。反过来,使用容量创建的 channel 称为缓冲通道。
无缓冲 chan 没有容量,因此进行任何交换前需要两个 goroutine 同时准备好。当 goroutine 试图将一个资源发送到一个无缓冲的通道并且没有goroutine 等待接收该资源时,该通道将锁住发送 goroutine 并使其等待。当 goroutine 尝试从无缓冲通道接收,并且没有 goroutine 等待发送资源时,该通道将锁住接收 goroutine 并使其等待。
- Receive 先于Send发生
- 好处:100%保证能收到
- 代价:延迟时间未知
buffered channel 具有容量,因此其行为可能有点不同。当 goroutine 试图将资源发送到缓冲通道,而该通道已满时,该通道将锁住 goroutine并使其等待缓冲区可用。如果通道中有空间,发送可以立即进行,goroutine 可以继续。当goroutine 试图从缓冲通道接收数据,而缓冲通道为空时,该通道将锁住 goroutine 并使其等待资源被发送。
- Send先于Receive发生
- 好处:延迟更小
- 代价:不保证数据到达,越大的 buffer,越小的保障到达。buffer = 1 时,给你延迟一个消息的保障。
注意:
- channel的大小不代表性能和吞吐。吞吐是需要靠多线程,即多个消费的goroutine消费
- 注意:关于channel的close一定是发送者来操作。
Go进阶笔记-关于error
很多人对于Go的error比较吐槽,说代码中总是会有大量的如下代码:
if err != nil {
...
}
其实很多时候是使用的姿势不对,或者说,对于error的用法没有完全理解,这里整理一下关于Go中的error 。
关于源码中的error
先看一下go源码中go/src/builtin/builtin.go对于error的定义:
// The error built-in interface type is the conventional interface for
// representing an error condition, with the nil value representing no error.
type error interface {
Error() string
}
我们使用的时候经常会通过errors.New() 来返回一个error对象,这里可以看一下我们调用errors.New()的这段源码文件go/src/errors/errors.go,可以看到errorString实现了error解接口,而errors.New()其实返回的是一个 &errorString{text} 即errorString对象的指针。
package errors
// New returns an error that formats as the given text.
// Each call to New returns a distinct error value even if the text is identical.
func New(text string) error {
return &errorString{text}
}
// errorString is a trivial implementation of error.
type errorString struct {
s string
}
func (e *errorString) Error() string {
return e.s
}
如果之前看过一些优秀源码或者go源码的,会发现代码中通常会定义很多自定义的error,并且都是包级别的变量,即变量名首字母大写:
// https://golang.org/pkg/bufio
var (
ErrInvalidUnreadByte = errors.New("bufio: invalid use of UnreadByte")
ErrInvalidUnreadRune = errors.New("bufio: invalid use of UnreadRune")
ErrBufferFull = errors.New("bufio: buffer full")
ErrNegativeCount = errors.New("bufio: negative count")
)
注意:自己之后在代码中关于这种自定义错误的定义,也要参照这种格式规范定义。
“当前的包名:错误信息”
package main
import (
"errors"
"fmt"
)
type errorString string
// 实现 error 接口
func (e errorString) Error() string {
return string(e)
}
func New(text string) error {
return errorString(text)
}
var errNamedType = New("EOF")
var ErrStructType = errors.New("EOF")
func main() {
// 这里其实就是两个结构体值的比较
if errNamedType == New("EOF") {
fmt.Println("Named Type Error") // 这行打印会输出
}
// 标准库中errors.New() 返回的是一个地址,每次调用都会返回一个新的内存地址
// 标准库这样设计也是为了避免碰巧如果两个结构体值相同了,而引发一些不期望的问题
if ErrStructType == errors.New("EOF") {
fmt.Println("Struct Type Error") // 这行打印不会输出
}
}
关于结构体值的比较:
如果两个结构体值的类型均为可比较类型,则它们仅在它们的类型相同或者它们的底层类型相同(要考虑字段标签)并且其中至少有一个结构体值的类型为非定义类型时才可以互相比较。
如果两个结构体值可以相互比较,则它们的比较结果等同于逐个比较它们的相应字段。
注意:关于Go中函数支持多参数返回,如果函数有error的通常把返回值的最后一个参数作为error
如果一个函数返回(value, error)这个时候必须先判定error
Go中的panic 意味着程序挂了不能继续运行了,不能假设调用者来解决panic。
对于刚学习go的时候经常用如下代码开启一个goroutine执行任务:
go func() {
...
}
这种情况也叫野生goroutine,并且这个时候recover是不能解决的。
可以定义一个包,通过调用该包中的Go() 方法来开goroutine,来避免野生goroutine。
package sync
func Go(x func()) {
if err := recover(); err != nil {
....
}
go x()
}
关于代码的panic 通常在代码中是很少使用的,只有在极少情况下,我们需要panic,如我们项目的初始化地方连接数据库连接不上,并且这个时候,数据库是我们程序的强依赖,那么这个时候是可以panic。
下面通过一个例子来演示error的使用姿势:
package main
import (
"errors"
"fmt"
)
// 判断正负数
func Positivie(n int) (bool, error) {
if n == 0 {
return false, errors.New("undefined")
}
return true, nil
}
func Check(n int) {
pos, err := Positivie(n)
if err != nil {
fmt.Println(n, err)
return
}
if pos {
fmt.Println(n, "is positive")
} else {
fmt.Println(n, "is negative")
}
}
func main() {
Check(1)
Check(0)
Check(-1)
}
上面是一种非常正确的姿势,我们通过返回(value, error) 这种方式来解决,也是非常go 的一种写法,只有err!=nil 的时候我们的value才有意义
那么在实际中可能有很多各种姿势来解决上述的问题,如下:
package main
import "fmt"
func Positive(n int) *bool {
if n == 0 {
return nil
}
r := n > -1
return &r
}
func Check(n int) {
pos := Positive(n)
if pos == nil {
fmt.Println(n, "is neither")
return
}
if *pos {
fmt.Println(n, "is positive")
} else {
fmt.Println(n, "is negative")
}
}
func main() {
Check(1)
Check(0)
Check(-1)
}
另外一种姿势:
package main
import "fmt"
func Positive(n int) bool {
if n == 0 {
panic("undefined")
}
return n > -1
}
func Check(n int) {
defer func() {
if recover() != nil {
fmt.Println("is neither")
}
}()
if Positive(n) {
fmt.Println(n, "is positive")
} else {
fmt.Println(n, "is negative")
}
}
func main() {
Check(1)
Check(0)
Check(-1)
}
上面这两种姿势虽然也可以实现这个功能,但是非常的不好,也不推荐使用。在代码中尽可能还是使用(value, error) 这种返回值来解决error的情况。
对于真正意外的情况,那些不可恢复的程序错误,例如索引越界,不可恢复的环境问题,栈溢出等才会使用panic,对于其他的情况我们应该还是期望使用error来进行判定。
error 处理套路
Sentinel Error 预定义error
通常我们把代码包中如下的这种error叫预定义error.
// https://golang.org/pkg/bufio
var (
ErrInvalidUnreadByte = errors.New("bufio: invalid use of UnreadByte")
ErrInvalidUnreadRune = errors.New("bufio: invalid use of UnreadRune")
ErrBufferFull = errors.New("bufio: buffer full")
ErrNegativeCount = errors.New("bufio: negative count")
)
这种姿势的缺点:
对于这种错误,在实际中的使用中我们通常会使用
if err == ErrSomething {....}这种姿势来进行判断。但是也不得不说,这种姿势是最不灵活的错误处理策略,并且不能对于错误提供有用的上下文。
Sentinel errors 成为API的公共部分。如果你的公共函数或方法返回一个特定值的错误,那么该错误就必须是公共的,当然要有文档记录,这最终会增加API的表面积。
Sentinel errors 在两个包之间创建了依赖。对于使用者不得不导入这些错误,这样就在两个包之间建立了依赖关系,当项目中有许多类似的导出错误值时,存在耦合,项目中的其他包必须导入这些错误值才能检查特定的错误条件。
Error types
Error type 是实现了error接口的自定义类型,例如MyError类型记录了文件和行号以展示发生了什么
type MyError struct {
Msg string
File string
Line int
}
func (e *MyError) Error() string {
return fmt.Sprintf("%s:%d:%s", e.File,e.Line, e.Msg)
}
func test() error {
return &MyError("something happened", "server.go", 11)
}
func main() {
err := test()
switch err := err.(type){
case nil:
// ....
case *MyError:
fmt.Println("error occurred on line:", err.Line)
default:
// ....
}
}
这种方式其实在标准库中也有使用如os.PathError
// https://golang.org/pkg/os/#PathError
type PathError struct {
Op string
Path string
Err error
}
调用者要使用类型断言和类型switch,就要让自定义的error变成public,这种模型会导致和调用者产生强耦合,从而导致API变得脆弱。
Opaque errors
这种方式也称为不透明处理,这也是相对来说比较优雅的处理方式,如下
func fn() error {
x, err := bar.Foo()
if err != nil {
return err
}
// use x
}
这种不透明的实现方式,一种比较好的用法,这里以net库的代码来看:
// https://golang.org/pkg/net/#Error
type Error interface {
error
Timeout() bool // Is the error a timeout?
Temporary() bool // Is the error temporary?
}
这里是定义了一个Error接口,而让其他需要用到error的来实现这个接口,如net中的下面这个错误
// https://golang.org/pkg/net/#DNSConfigError
type DNSConfigError
func (e *DNSConfigError) Error() string
func (e *DNSConfigError) Temporary() bool
func (e *DNSConfigError) Timeout() bool
func (e *DNSConfigError) Unwrap() error
按照这个方式实现我们使用net时的异常处理可能就是如下情况:
if neerr, ok := err.(net.err); ok && nerr.Temporary() {
time.Sleep(time.Second * 10)
continue
}
if err != nil {
log.Fatal(err)
}
其实这样还是不够优雅,好的方式是我们卡一定义temporary的接口,然后取实现这个接口,这样整体代码就看着非常简洁清楚,对外我们就只需要暴露IsTemporary方法即可,而不用外部再进行断言。
Type temporary interface {
Temporary() bool
}
func IsTemporary(err error) bool {
te, ok := err.(temporary)
return ok && te.Temporary()
}
以上这几种姿势,其实各有各的用处,不同的场景,选择可能也不同,需要根据实际场景实际分析。
一个error 技巧使用例子
先看一段代码,相信这段代码如果很多人实现的时候也都是这个样子:
type Header struct {
Key, Value string
}
type Status struct {
Code int
Reason string
}
func WriteResponse(w io.Writer, st Status, headers []Header, body io.Reader) error {
_, err := fmt.Fprintf(w, "HTTP/1.1 %d %s\r\n", st.Code, st.Reason)
if err != nil {
return err
}
for _, h := range headers {
_, err := fmt.Fprintf(w, "%s:%s\r\n", h.Key, h.Value)
if err != nil {
return err
}
}
if _, err := fmt.Fprint(w, "\r\n"); err != nil {
return err
}
_, err = io.Copy(w, body)
return err
}
看这段代码时候估计很多就开始吐嘈go的error的处理,感觉代码中会存在很多err的判断处理,其实这里是可以写的更优雅一点的,上面的姿势不对,来换个姿势:
type errWriter struct {
io.Writer
err error
}
func(e *errWriter) Write(buf []byte) (int, error) {
if e.err != nil {
return 0, e.err
}
var n int
n, e.err = e.Writer.Write(buf)
return n,nil
}
func WriteResponse(w io.Writer, st Status, headers []Header, body io.Reader) error {
ew :=&errWriter{Writer:w}
fmt.Fprintf(ew, "HTTP/1.1 %d %s\r\n", st.Code, st.Reason)
for _, h := range headers {
fmt.Fprintf(ew, "%s:%s\r\n", h.Key, h.Value)
}
fmt.Fprint(w, "\r\n")
io.Copy(w, body)
return ew.err
}
对比之下这种代码看起来是不是就非常简洁,所有很多时候可能是自己写代码的姿势不对,而不是go的error设计的不好。
Wrap errors
就像下面这段代码一样,这样的使用方式,我自己在工程代码中也经常看到,这样就会导致生成的错误没有file:line信息,没有导致错误的调用堆栈信息,如果出现异常就非常不方便排查到底是哪里导致的问题,其次因为这里通过fmt.Errorf对错误进行了包装,也就破坏了原始错误。
func AuthenticateReuest(r *Request) error {
err := authenticate(r.User)
if err != nil {
return fmt.Errorf("authenticate failed:%v", err)
}
return nil
}
关于error的处理中还有一个非常重要的地方就是是否是每次出现err!=nil的时候,我们都需要打印日志? 如果这样做了,你会发现到处在打印日志,还有很多地方可能打印的是相同的日志。
func WriteAll(w io.Writer, buf[]byte) error {
_, err := w.Write(buf)
if err != nil {
log.Println("unalbe to write:",err) //这里记录了日志
return err //将日志进行上抛给调用者
}
return nil
}
func WriteConfig(w io.Writer, conf *Config) error {
buf, err := json.Marshal(conf)
if err != nil {
log.Printf("cound not marshal config:%v", err)
return err
}
if err := WriteAll(w, buf); err != nil {
log.Println("cound not write config:%v",err)
return err
}
return nil
}
在上面这个例子中, 这个错误逐层返回给调用者,如果处理不好,可能就像上面这个例子,每次都打印日志,一直到程序的顶部
所以:error应该只被处理一次。
Go中错误的处理契约规定:在出现错误的情况下,不能对其他返回值的内容做任何假设,如下代码中,由于json序列化失败,buf的内容是未知的,这个时候把损坏的buf传给后续处理逻辑,这样就会导致一些未知的错误发生。
func WriteConfig(w io.Writer, conf *Config) error {
buf, err := json.Marshal(conf)
if err != nil {
log.Printf("cound not marshal config:%v", err)
// 忘记return
}
if err := WriteAll(w, buf); err != nil {
log.Println("cound not write config:%v",err)
return err
}
return nil
}
关于错误日志处理的规则:
- 错误要被日志记录
- 应用程序处理错误,保证100%的完整性
- 之后不再报告当前错误
github.com/pkg/errors 这个error处理包非常受欢迎,看一下这个包对错误的处理例子:
package main
import (
"fmt"
"io/ioutil"
"os"
"path/filepath"
"github.com/pkg/errors"
)
func ReadFile(path string) ([]byte, error) {
f, err := os.Open(path)
if err != nil {
return nil, errors.Wrap(err, "open failed")
}
defer f.Close()
buf, err := ioutil.ReadAll(f)
if err != nil {
return nil, errors.Wrap(err, "read failed")
}
return buf, nil
}
func ReadConfig() ([]byte, error) {
home := os.Getenv("HOME")
config, err := ReadFile(filepath.Join(home, ".settings.xml"))
return config, errors.WithMessage(err, "cound not read config")
}
func main() {
_, err := ReadConfig()
if err != nil {
fmt.Printf("original err:%T %v\n", errors.Cause(err), errors.Cause(err))
fmt.Printf("stack trace:\n %+v\n",err) // %+v 可以在打印的时候打印完整的堆栈信息
os.Exit(1)
}
}
执行结果如下:
original err:*os.PathError open /Users/zhaofan/.settings.xml: no such file or directory
stack trace:
open /Users/zhaofan/.settings.xml: no such file or directory
open failed
main.ReadFile
/Users/zhaofan/open_source_study/test_code/202012/wrap_errors/main.go:15
main.ReadConfig
/Users/zhaofan/open_source_study/test_code/202012/wrap_errors/main.go:27
main.main
/Users/zhaofan/open_source_study/test_code/202012/wrap_errors/main.go:32
runtime.main
/Users/zhaofan/app/go/src/runtime/proc.go:204
runtime.goexit
/Users/zhaofan/app/go/src/runtime/asm_amd64.s:1374
cound not read config
exit status 1
从代码上也非常简洁,处理的非常优雅,最终不管是错误信息还是堆栈信息,还可以添加自定义的上下文,同时也完全满足上面提出的关于错误日志处理的规则。
关于代码中的Wrap源码如下:
// Wrap returns an error annotating err with a stack trace
// at the point Wrap is called, and the supplied message.
// If err is nil, Wrap returns nil.
func Wrap(err error, message string) error {
if err == nil {
return nil
}
err = &withMessage{
cause: err,
msg: message,
}
return &withStack{
err,
callers(),
}
}
可以看到我们每次调用errors.Wrap方法的时候都是把我们的错误信息err存入到withMessage结构体的cause字段,同时又把包装的withMessage 作为err存到withStack结构体中,同时withStack包含了调用堆栈的信息
type withMessage struct {
cause error
msg string
}
关于github.com/pkg/errors使用姿势
- 在你自己的应用程序中,使用errors.New或者errors.Errorf返回错误
- 如果调用其他包内的函数或者你当前项目里的其他函数,通常简单的直接返回,即直接
return err - 如果你使用第三方库如github库,公司的基础库,或者go的基础库,这个时候应该使用
errors.Wrap或者errors.Wrapf保存堆栈信息,同时添加自定义的上下文信息 - 直接返回错误,而不是每个错误产生的地方打日志
- 在程序的顶部或者工作的
goroutine顶部(请求入口)使用%+v把堆栈详情记录 - 使用
errors.Cause获取root error即根因,在进行和sentinel error进行等值判定 - 一旦错误被处理,包括你打印日志,或者降级处理等,这个时候你就不应该再向上抛出err,而应该return nil.
go1.13 中的errors
go 1.13 为errors和fmt标准库引入了新的特性,以简化处理包含其他错误的错误。其中最重要的就是:包含一个错误的error可以实现返回底层错误的Unwrap 方法。如果e1.Unwrap() 返回e2, 那么e1就包装了e2,就可以展开e1以获取e2
在Go的1.13 中fmt.Errorf支持新的%w ,这样就在错误信息中带入原始的信息,这样既保证了人阅读的方便,也方便了机器处理,如:
if err != nil {
return fmt.Errorf("access denied %w", ErrrPermission)
}
把之前的例子进行调整如下:
package main
import (
"fmt"
"io/ioutil"
"os"
"path/filepath"
"errors"
)
func ReadFile(path string) ([]byte, error) {
f, err := os.Open(path)
if err != nil {
return nil, fmt.Errorf("open failed: %w", err)
}
defer f.Close()
buf, err := ioutil.ReadAll(f)
if err != nil {
return nil, fmt.Errorf("read failed: %w", err)
}
return buf, nil
}
func ReadConfig() ([]byte, error) {
home := os.Getenv("HOME")
config, err := ReadFile(filepath.Join(home, ".settings.xml"))
return config, fmt.Errorf("cound not read config: %w", err)
}
func main() {
_, err := ReadConfig()
if err != nil {
// errors.Is会一层一层的展开,找最内层的err
fmt.Println(errors.Is(err, os.ErrNotExist))
os.Exit(1)
}
}
但是1.13的errors有个非常大的问题就是不支持携带堆栈信息,所以最好的办法就是把标准库中的errors和github.com/pkg/errors
package main
import (
"errors"
"fmt"
xerrors "github.com/pkg/errors"
)
var errMy = errors.New("My Error")
func test0() error {
return xerrors.Wrapf(errMy, "test0 failed")
}
func test1() error {
return test0()
}
func test2() error {
return test1()
}
func main() {
err := test2()
fmt.Printf("main: %+v\n", err)
fmt.Println(errors.Is(err, errMy))
}
其实原则就是我们底层的错误还是通过 github.com/pkg/errors 中Wrapf 进行包装。并且这个时候也完全兼容标准库中的errors,可以使用errors.Is 和 errors.As方法做判断处理。





