

虚拟化容器
Kubernetes中的容器编排和应用编排
云原生 OS小编 发表了文章 0 个评论 2096 次浏览 2021-11-27 17:06

众所周知,Kubernetes 是一个容器编排平台,它有非常丰富的原始的 API 来支持容器编排,但是对于用户来说更加关心的是一个应用的编排,包含多容器和服务的组合,管理它们之间的依赖关系,以及如何管理存储。
在这个领域,Kubernetes 用 Helm 的来管理和打包应用,但是 Helm 并不是十全十美的,在使用过程中我们发现它并不能完全满足我们的需求,所以在 Helm 的基础上,我们自己研发了一套编排组件……
什么是编排
不知道大家有没仔细思考过编排到底是什么意思? 我查阅了 Wiki 百科,了解到我们常说的编排的英文单词为 “Orchestration”,它常被解释为:
- 本意:为管弦乐中的配器法,主要是研究各种管弦乐器的运用和配合方法,通过各种乐器的不同音色,以便充分表现乐曲的内容和风格。
- 计算机领域:引申为描述复杂计算机系统、中间件 (middleware) 和业务的自动化的安排、协调和管理。
有趣的是 “Orchestration” 的标准翻译应该为“编配”,而“编排”则是另外一个单词 “Choreography”,为了方便大家理解, 符合平时的习惯,我们还是使用编排 (Orchestration) 来描述下面的问题。至于“编配 (Orchestration)” 和 “编排(Choreography)” 之争,这里有一篇文章,有兴趣可以看一下 。http://www.infoq.com/cn/news/2008/09/Orchestration
Kubernetes 容器编排技术
当我们在说容器编排的时候,我们在说什么?
在传统的单体式架构的应用中,我们开发、测试、交付、部署等都是针对单个组件,我们很少听到编排这个概念。而在云的时代,微服务和容器大行其道,除了为我们显示出了它们在敏捷性,可移植性等方面的巨大优势以外,也为我们的交付和运维带来了新的挑战:我们将单体式的架构拆分成越来越多细小的服务,运行在各自的容器中,那么该如何解决它们之间的依赖管理,服务发现,资源管理,高可用等问题呢?
在容器环境中,编排通常涉及到三个方面:
- 资源编排 - 负责资源的分配,如限制 namespace 的可用资源,scheduler 针对资源的不同调度策略;
- 工作负载编排 - 负责在资源之间共享工作负载,如 Kubernetes 通过不同的 controller 将 Pod 调度到合适的 node 上,并且负责管理它们的生命周期;
- 服务编排 - 负责服务发现和高可用等,如 Kubernetes 中可用通过 Service 来对内暴露服务,通过 Ingress 来对外暴露服务。
在 Kubernetes 中有 5 种经常会用到的控制器来帮助我们进行容器编排,分别是 Deployment, StatefulSet, DaemonSet, CronJob, Job。
在这 5 种常见资源中,Deployment 经常被作为无状态实例控制器使用; StatefulSet 是一个有状态实例控制器; DaemonSet 可以指定在选定的 Node 上跑,每个Node 上会跑一个副本,它有一个特点是它的Pod的调度不经过调度器,在Pod 创建的时候就直接绑定NodeName;最后一个是定时任务,它是一个上级控制器,和 Deployment 有些类似,当一个定时任务触发的时候,它会去创建一个 Job,具体的任务实际上是由 Job 来负责执行的。他们之间的关系如下图: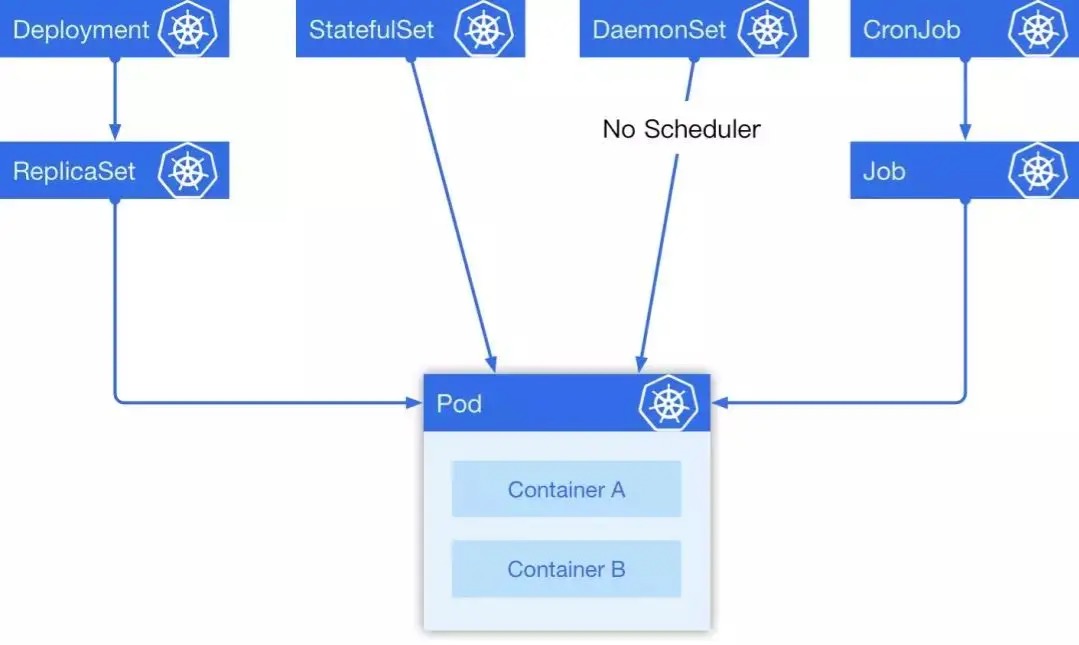
一个简单的例子
我们来考虑这么一个简单的例子,一个需要使用到数据库的 API 服务在 Kubernetes 中应该如何表示:
客户端程序通过 Ingress 来访问到内部的 API Service, API Service 将流量导流到 API Server Deployment 管理的其中一个 Pod 中,这个 Server 还需要访问数据库服务,它通过 DB Service 来访问 DataBase StatefulSet 的有状态副本。由定时任务 CronJob 来定期备份数据库,通过 DaemonSet 的 Logging 来采集日志,Monitoring 来负责收集监控指标。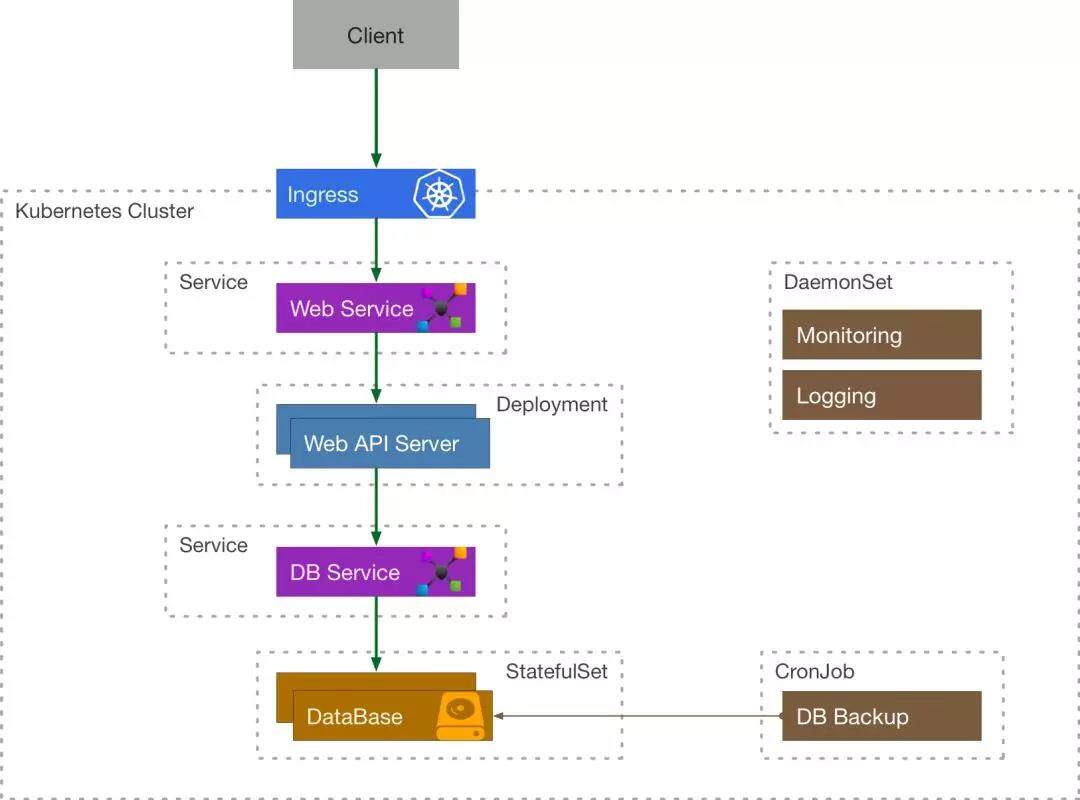
容器编排的困境
Kubernetes 为我们带来了什么?
通过上面的例子,我们发现 Kubernetes 已经为我们对大量常用的基础资源进行了抽象和封装,我们可以非常灵活地组合、使用这些资源来解决问题,同时它还提供了一系列自动化运维的机制:如 HPA, VPA, Rollback, Rolling Update 等帮助我们进行弹性伸缩和滚动更新,而且上述所有的功能都可以用 YAML 声明式进行部署。
困境
但是这些抽象还是在容器层面的,对于一个大型的应用而言,需要组合大量的 Kubernetes 原生资源,需要非常多的 Services, Deployments, StatefulSets 等,这里面用起来就会比较繁琐,而且其中服务之间的依赖关系需要用户自己解决,缺乏统一的依赖管理机制。
应用编排
什么是应用?
一个对外提供服务的应用,首先它需要一个能够与外部通讯的网络,其次还需要能运行这个服务的载体 (Pods),如果这个应用需要存储数据,这还需要配套的存储,所以我们可以认为:
应用单元 = 网络 + 服务载体 +存储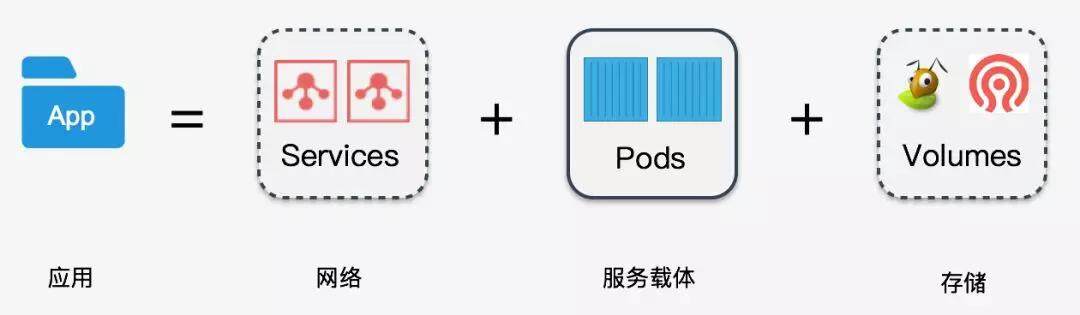
那么我们很容易地可以将 Kubernetes 的资源联系起来,然后将他们划分为 4 种类型的应用:
- 无状态应用 = Services + Volumes + Deployment
- 有状态应用 = Services + Volumes + StatefulSet
- 守护型应用 = Services + Volumes + DaemonSet
- 批处理应用 = Services + Volumes + CronJob/Job
我们来重新审视一下之前的例子: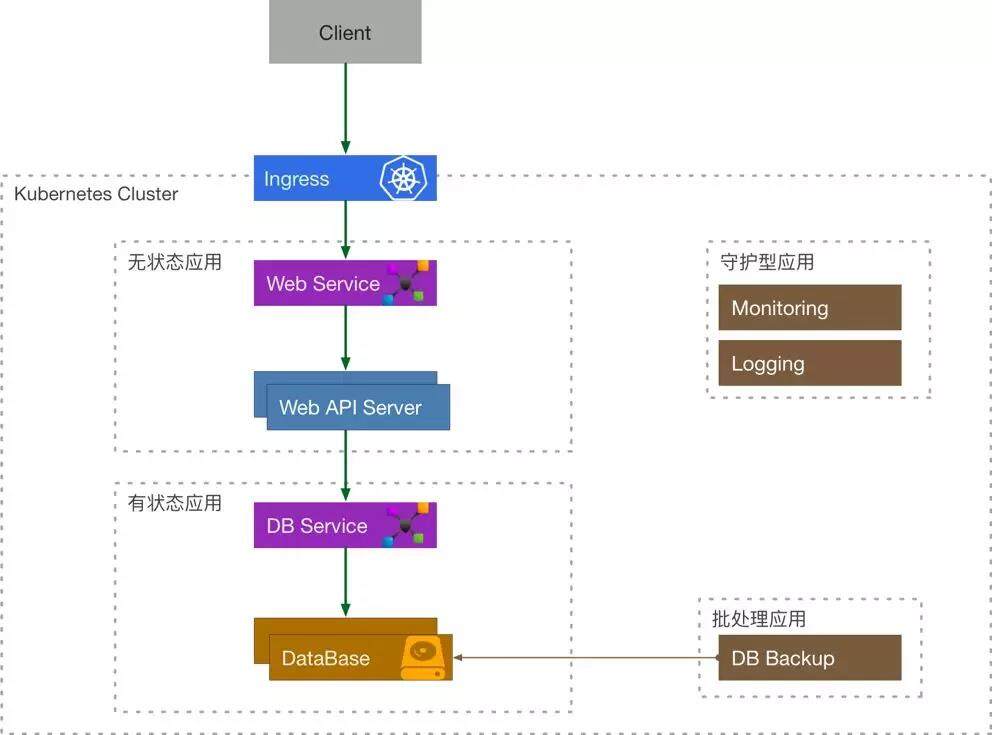
应用层面的四个问题
通过前面的探索,我们可以引出应用层面的四个问题:
- 应用包的定义
- 应用依赖管理
- 包存储
- 运行时管理
在社区中,这四个方面的问题分别由三个组件或者项目来解决:
- Helm Charts: 定义了应用包的结构以及依赖关系;
- Helm Registry: 解决了包存储;
- HelmTiller: 负责将包运行在 Kubernetes 集群中。
Helm Charts
Charts 在本质上是一个 tar 包,包含了一些 yaml 的 template 以及解析 template 需要的 values, 如下图:templates 是 Golang 的 template 模板,values.yaml 里面包含了这个 Charts 需要的值。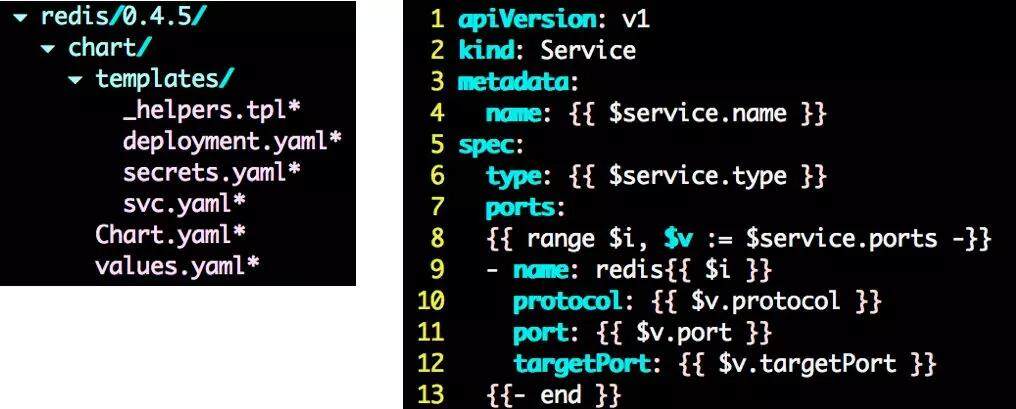
Helm Registry
用来负责存储和管理用户的 Charts, 并提供简单的版本管理,与容器领域的镜像仓库类似这个项目是开源的。( https://github.com/caicloud/helm-registry)
Tiller
- 负责将 Chart 部署到指定的集群当中,并管理生成的 Release (应用);
- 支持对 Release 的更新,删除,回滚操作;
- 支持对 Release 的资源进行增量更新;
- Release 的状态管理;
- Kubernetes下属子项目(https://github.com/kubernetes/helm) 。
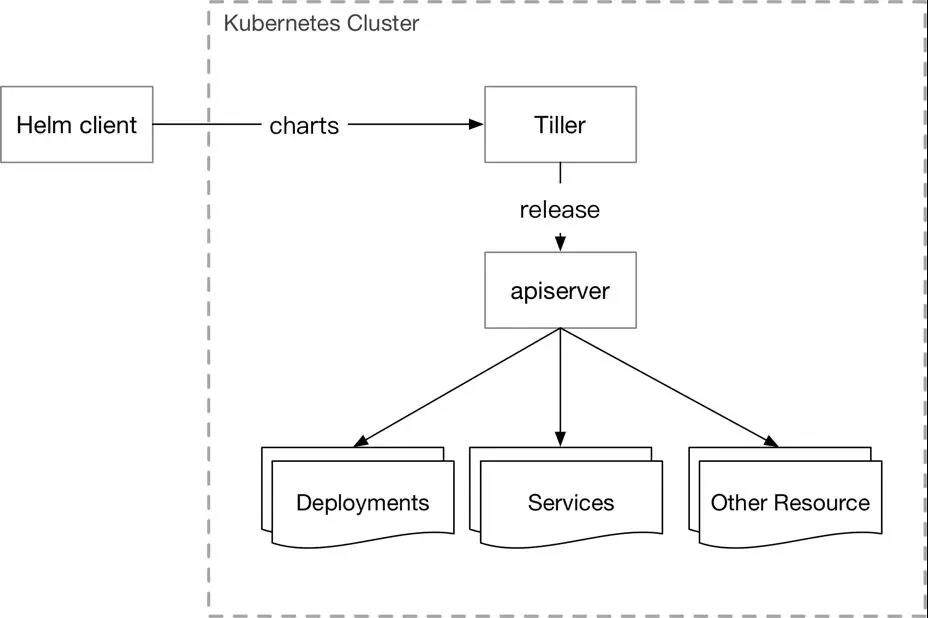
Tiller 的缺陷
- 没有内建的认知授权机制,Tiller 跑在 kube-system 分区下,拥有整个集群的权限;
- Tiller 将 Release 安装到 Kubernetes 集群中后并不会继续追踪他们的状态;
- Helm+Tiller的架构并不符合 Kubernetes 的设计模式,这就导致它的拓展性比较差;
- Tiller 创建的 Release 是全局的并不是在某一个分区下,这就导致多用户/租户下,不能进行隔离;
- Tiller 的回滚机制是基于更新的,每次回滚会使版本号增加,这不符合用户的直觉。
Release Controller
为了解决上述的问题,我们基于 Kubernetes 的 Custom Resource Definition 设计并实现了我们自己的运行时管理系统 – Release Controller, 为此我们设计了两个新的 CRD – Release 和 Release History。
Release 创建
当 Release CRD 被创建出来,controller 为它创建一个新的 Release History, 然后将 Release 中的 Chart 和 Configuration 解析成 Kubernetes 的资源,然后将这些资源在集群中创建出来,同时会监听这些资源的变化,将它们的状态反映在 Release CRD 的 status 中。
Release 更新
当用户更新 Release 的时候,controller 计算出更新后的资源与集群中现有资源的 diff, 然后删除一部分,更新一部分,创建一部分,来使得集群中的资源与 Release 描述的一致,同时为旧的 Release 创建一份 Release History。
Release 回滚和删除
用户希望回滚到某一个版本的 Release, controller 从 Release History 中找到对应的版本,然后将 Release 的 Spec 覆盖,同时去更新集群中对应的资源。当 Release 被删除后,controller 将它关联的 Release History 删除,同时将集群中的其他资源一并删除。
架构图 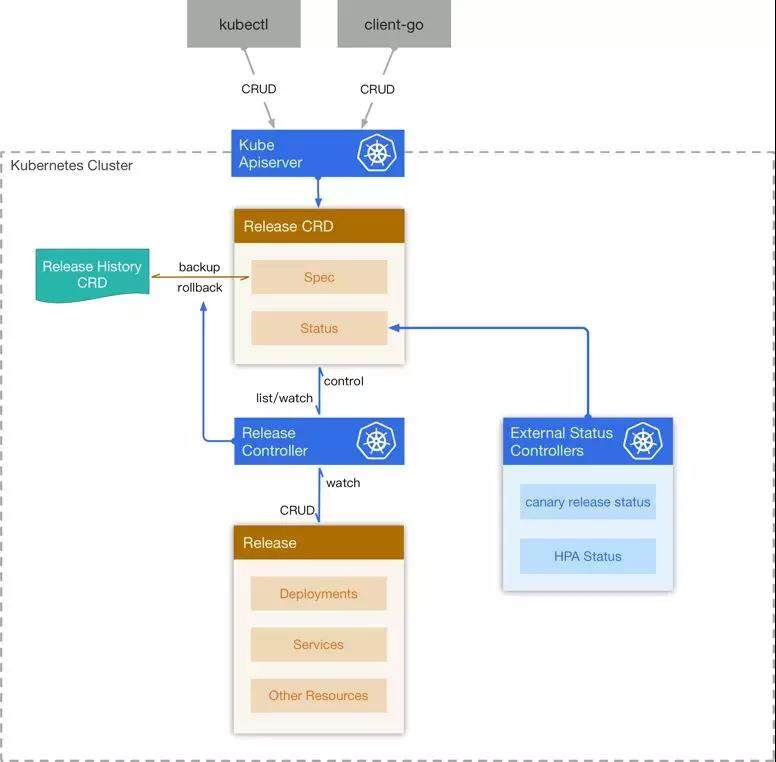
这样的设计有什么好处?
- 隔离性:资源使用 Namespace 隔离,适应多用户/租户;
- 可读性:Release Controller 会追踪每个 Release 的子资源的状态;
- 版本控制:你可以很容易地会退到某一个版本;
- 拓展性:整个架构是遵循 Kubernetes 的 controller pattern,具有良好的可扩展性,可以在上面进行二次开发;
- 安全性:因为所有的操作都是基于 Kubernetes 的 Resource,可以充分利用 Kubernetes 内建的认证鉴权模块,如 ABAC, RBAC 。
总而言之,编排不仅仅是一门技术也是一门艺术!谢谢!
分享阅读原文链接:https://mp.weixin.qq.com/s/zHlS2cQEHzRea_bqKpNA9A
使用kubekey部署kubernetes集群
DevOps Rock 发表了文章 0 个评论 2464 次浏览 2021-10-22 11:52

kubekey简介
kubeykey是KubeSphere基于Go 语言开发的kubernetes集群部署工具,使用 KubeKey,您可以轻松、高效、灵活地单独或整体安装 Kubernetes 和 KubeSphere。
KubeKey可以用于以下三种安装场景:
- 仅安装 Kubernetes集群
- 使用一个命令安装 Kubernetes 和 KubeSphere
- 已有Kubernetes集群,使用ks-installer 在其上部署 KubeSphere
项目地址:https://github.com/kubesphere/kubekey 开源公司:青云
kubekey安装
下载kk二进制部署命令,您可以在任意节点下载该工具,比如准备一个部署节点,或者复用集群中已有节点:
wget https://github.com/kubesphere/kubekey/releases/download/v1.2.0-alpha.2/kubekey-v1.2.0-alpha.2-linux-amd64.tar.gz
tar -zxvf kubekey-v1.2.0-alpha.2-linux-amd64.tar.gz
mv kk /usr/local/bin/
脚本下载安装:
export KKZONE=cn
curl -sfL | VERSION=v1.1.0 sh -
mv kk /usr/local/bin/
查看版本:
kk version
在所有节点上安装相关依赖
yum install -y socat conntrack ebtables ipset
所有节点关闭selinux和firewalld
setenforce 0 && sed -i 's/^SELINUX=enforcing$/SELINUX=disabled/' /etc/selinux/config
systemctl disable --now firewalld
所有节点时间同步
yum install -y chrony
systemctl enable --now chronyd
timedatectl set-timezone Asia/Shanghai
节点无需配置主机名,kubekey会自动纠正主机名。
部署单节点集群
部署单节点kubernetes
kk create cluster
同时部署kubernetes和kubesphere,可指定kubernetes版本或kubesphere版本
kk create cluster --with-kubernetes v1.20.4 --with-kubesphere v3.1.0
当指定安装KubeSphere时,要求集群中有可用的持久化存储。默认使用localVolume,如果需要使用其他持久化存储,请参阅addons配置。
部署多节点集群
准备6个节点,部署高可用kubernetes集群,kubekey的高可用实现目前是基于haproxy的本地负载均衡模式。
创建示例配置文件:
kk create config
根据您的环境修改配置文件config-sample.yaml,以下示例以部署3个master节点和3个node节点为例(不执行kubesphere部署,仅搭建kubernetes集群):
cat > config-sample.yaml <使用配置文件创建集群
export KKZONE=cn
kk create cluster -f config-sample.yaml | tee kk.log
创建完成后查看节点状态
[root@kube-master1 ~]# kubectl get nodes -o wide
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
kube-master1 Ready control-plane,master 4m58s v1.20.6 192.168.93.60 CentOS Linux 7 (Core) 3.10.0-1127.el7.x86_64
kube-master2 Ready control-plane,master 3m58s v1.20.6 192.168.93.61 CentOS Linux 7 (Core) 3.10.0-1127.el7.x86_64
kube-master3 Ready control-plane,master 3m58s v1.20.6 192.168.93.62 CentOS Linux 7 (Core) 3.10.0-1127.el7.x86_64
kube-node1 Ready worker 4m13s v1.20.6 192.168.93.63 CentOS Linux 7 (Core) 3.10.0-1127.el7.x86_64
kube-node2 Ready worker 3m59s v1.20.6 192.168.93.64 CentOS Linux 7 (Core) 3.10.0-1127.el7.x86_64
kube-node3 Ready worker 3m59s v1.20.6 192.168.93.65 CentOS Linux 7 (Core) 3.10.0-1127.el7.x86_64
查看所有pod状态
[root@kube-master1 ~]# kubectl get pods -A
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system calico-kube-controllers-8545b68dd4-rbshc 1/1 Running 2 3m48s
kube-system calico-node-5k7b5 1/1 Running 1 3m48s
kube-system calico-node-6cv8z 1/1 Running 1 3m48s
kube-system calico-node-8rbjs 1/1 Running 0 3m48s
kube-system calico-node-d6wkc 1/1 Running 0 3m48s
kube-system calico-node-q8qp8 1/1 Running 0 3m48s
kube-system calico-node-rvqpj 1/1 Running 0 3m48s
kube-system coredns-7f87749d6c-66wqb 1/1 Running 0 4m58s
kube-system coredns-7f87749d6c-htqww 1/1 Running 0 4m58s
kube-system haproxy-kube-node1 1/1 Running 0 4m3s
kube-system haproxy-kube-node2 1/1 Running 0 4m3s
kube-system haproxy-kube-node3 1/1 Running 0 2m47s
kube-system kube-apiserver-kube-master1 1/1 Running 0 5m13s
kube-system kube-apiserver-kube-master2 1/1 Running 0 4m10s
kube-system kube-apiserver-kube-master3 1/1 Running 0 4m16s
kube-system kube-controller-manager-kube-master1 1/1 Running 0 5m13s
kube-system kube-controller-manager-kube-master2 1/1 Running 0 4m10s
kube-system kube-controller-manager-kube-master3 1/1 Running 0 4m16s
kube-system kube-proxy-2t5l6 1/1 Running 0 3m55s
kube-system kube-proxy-b8q6g 1/1 Running 0 3m56s
kube-system kube-proxy-dsz5g 1/1 Running 0 3m55s
kube-system kube-proxy-g2gxz 1/1 Running 0 3m55s
kube-system kube-proxy-p6gb7 1/1 Running 0 3m57s
kube-system kube-proxy-q44jp 1/1 Running 0 3m56s
kube-system kube-scheduler-kube-master1 1/1 Running 0 5m13s
kube-system kube-scheduler-kube-master2 1/1 Running 0 4m10s
kube-system kube-scheduler-kube-master3 1/1 Running 0 4m16s
kube-system nodelocaldns-l958t 1/1 Running 0 4m19s
kube-system nodelocaldns-n7vkn 1/1 Running 0 4m18s
kube-system nodelocaldns-q6wjc 1/1 Running 0 4m33s
kube-system nodelocaldns-sfmcc 1/1 Running 0 4m58s
kube-system nodelocaldns-tvdbh 1/1 Running 0 4m18s
kube-system nodelocaldns-vg5t7 1/1 Running 0 4m19s
kubekey集群维护
添加节点
kk add nodes -f config-sample.yaml
删除节点
kk delete node -f config-sample.yaml
删除集群
kk delete cluster
kk delete cluster [-f config-sample.yaml]
集群升级
kk upgrade [--with-kubernetes version] [--with-kubesphere version]
kk upgrade [--with-kubernetes version] [--with-kubesphere version] [(-f | --file) path]
Docker容器启动过程
大数据 Something 发表了文章 0 个评论 4020 次浏览 2017-03-09 15:02
docker run -i -t ubuntu /bin/bash输入上面这行命令,启动一个ubuntu容器时,到底发生了什么?
大致过程可以用下图描述:

首先系统要有一个docker daemon的后台进程在运行,当刚才这行命令敲下时,发生了如下动作:
- docker client(即:docker终端命令行)会调用docker daemon请求启动一个容器,
- docker daemon会向host os(即:linux)请求创建容器
- linux会创建一个空的容器(可以简单理解为:一个未安装操作系统的裸机,只有虚拟出来的CPU、内存等硬件资源)
- docker daemon请检查本机是否存在docker镜像文件(可以简单理解为操作系统安装光盘),如果有,则加载到容器中(即:光盘插入裸机,准备安装操作系统)
- 将镜像文件加载到容器中(即:裸机上安装好了操作系统,不再是裸机状态)
最后,我们就得到了一个ubuntu的虚拟机,然后就可以进行各种操作了。
如果在第4步检查本机镜像文件时,发现文件不存在,则会到默认的docker镜像注册机构(即:docker hub网站)去联网下载,下载回来后,再进行装载到容器的动作,即下图所示:

另外官网有一张图也很形象的描述了这个过程:

原文地址:http://www.cnblogs.com/yjmyzz/p/docker-container-start-up-analysis.html
参考文章:
https://www.gitbook.com/book/joshhu/docker_theory_install/details
https://docs.docker.com/engine/introduction/understanding-docker/
OVM-V1.5 版正式发布,新增对ESXI节点的支持
大数据 maoliang 发表了文章 0 个评论 3083 次浏览 2017-02-21 17:13
OVM是国内首款、完全免费、企业级——混合虚拟化管理平台,是从中小企业目前的困境得到启发,完全基于国内企业特点开发,更多的关注国内中小企业用户的产品需求。
OVM-V1.5虚拟化管理平台功能变动清单:
Ø 新增对VMwareEsxi节点的支持
Ø 合并管理平台和计算节点镜像为一个iso
Ø 支持通过USB安装OVM
Ø 修复其他若干bug
详细信息
1、新增对VMwareEsxi节点的支持
OVM-V 1.5版本新增对Esxi节点的支持,支持将现有的VMwareEsxi计算节点直接添加到OVM虚拟化管理平台进行管理,并支持将原有Esxi虚拟机导入到平台进行统一管理。目前OVM混合虚拟化平台已经能够统一管理KVM、ESXI、Docker三种类型的底层虚拟化技术。
2. 管理平台和计算节点 iso镜像合并
OVM-V 1.5版本将管理平台和计算节点原来的两个iso镜像合并到一个iso镜像里面,在安装过程中提供选项来安装不同的服务,此次的合并不仅方便了大家的下载,也提升了OVM的易用性。
3. 支持通过USB方式安装,提高工作效率
OVM1.5版本镜像支持通过USB方式进行安装,极大提高了一线运维人员的工作效率。
获得帮助
下载请访问OVM社区官网:51ovm.com
使用过程中遇到什么问题及获得下载密码,加入OVM社区qq官方交流群:22265939
Docker挂载主机目录出现Permission denied状况分析
大数据 空心菜 发表了文章 0 个评论 8710 次浏览 2017-02-16 23:10

今天用脚本部署一个Docker私有化环境,挂载宿主机目录出现Permission denied的情况,导致服务启动失败,具体情况如下:


问题原因及解决办法:
原因是CentOS7中的安全模块selinux把权限禁掉了,至少有以下三种方式解决挂载的目录没有权限的问题:
1、在运行容器的时候,给容器加特权,及加上 --privileged=true 参数
docker run -i -t -v /data/mysql/data:/data/var-3306 --privileged=true b0387b8279d4 /bin/bash -c "/opt/start_db.sh"2、临时关闭selinux
setenforce 03、添加selinux规则,改变要挂载的目录的安全性文本:
# 更改安全性文本的格式如下在主机中修改/data/mysql/data目录的安全性文档
chcon [-R] [-t type] [-u user] [-r role] 文件或者目录
选顷不参数:
-R :连同该目录下癿次目录也同时修改;
-t :后面接安全性本文的类型字段!例如 httpd_sys_content_t ;
-u :后面接身份识别,例如 system_u;
-r :后面街觇色,例如 system_r
[root@localhost Desktop]# chcon --help
Usage: chcon [OPTION]... CONTEXT FILE...
or: chcon [OPTION]... [-u USER] [-r ROLE] [-l RANGE] [-t TYPE] FILE...
or: chcon [OPTION]... --reference=RFILE FILE...
Change the SELinux security context of each FILE to CONTEXT.
With --reference, change the security context of each FILE to that of RFILE.
Mandatory arguments to long options are mandatory for short options too.
--dereference affect the referent of each symbolic link (this is
the default), rather than the symbolic link itself
-h, --no-dereference affect symbolic links instead of any referenced file
-u, --user=USER set user USER in the target security context
-r, --role=ROLE set role ROLE in the target security context
-t, --type=TYPE set type TYPE in the target security context
-l, --range=RANGE set range RANGE in the target security context
--no-preserve-root do not treat '/' specially (the default)
--preserve-root fail to operate recursively on '/'
--reference=RFILE use RFILE's security context rather than specifying
a CONTEXT value
-R, --recursive operate on files and directories recursively
-v, --verbose output a diagnostic for every file processed
The following options modify how a hierarchy is traversed when the -R
option is also specified. If more than one is specified, only the final
one takes effect.
-H if a command line argument is a symbolic link
to a directory, traverse it
-L traverse every symbolic link to a directory
encountered
-P do not traverse any symbolic links (default)
--help display this help and exit
--version output version information and exit
GNU coreutils online help:
For complete documentation, run: info coreutils 'chcon invocation'
[root@localhost Desktop]# chcon -Rt svirt_sandbox_file_t /data/mysql/data在docker中就可以正常访问该目录下的相关资源了。卷权限参考:https://yq.aliyun.com/articles/53990
OVM混合虚拟化设计目标及设计思路
大数据 maoliang 发表了文章 0 个评论 3111 次浏览 2016-09-29 09:42
OVM是要实现混合虚拟化,做一个大一统的资源管理和交付平台,纵观虚拟化市场,现在当属开源的KVM和Docker最火,我们工作过去有vmware,现在大量使用kvm,未来一定会考虑docker,但现有市场上的产品要么架构太大,开发难度高,易用性不够强,要么就是单纯的虚拟化,类似vmware等。
新形式下,我们需要的产品要同时具备如下目标:
跨平台,支持KVM、Esxi和Docker容器
因为我们单位过去采用虚拟化技术混杂,上面又遗留很多虚拟机,这就要求我们新开发产品能够兼容不同hypervior,同时还能识别并管理原有hypervior上的虚拟机,能够识别并导入原数据库技术并不难,难的是导入后还能纳入新平台管理,这部分我们又研发了自动捕获技术,而不同混合虚拟化管理技术可以摆脱对底层Hypervisor的依赖,专心于资源的统一管理。
单独的用户自助服务门户
过去采用传统虚拟化时,解决了安装部署的麻烦,但资源的申请和扩容、准备资源和切割资源仍然没有变,还是要让我们做,占据了日常运维工作的大部分工作量,每天确实烦人,所以我们想而这部分工作是可以放给相关的部门Leader或者专员,来减少运维的工作量,所以我们希望新设计的OVM允许用户通过一个单独的Web门户来直接访问自己的资源(云主机、云硬盘、网络等),而且对自己的资源进行管理,而不需要知道资源的具体位置,同时用户的所有云主机都建立在高可用环境之上,也不必担心实际物理硬件故障引起服务瘫痪。
Opscode Chef自动化运维集成
实行自助服务后,有一个问题,就是软件不同版本部署不兼容,这就需要设计能够把操作系统、中间件、数据库、web能统一打包部署,减少自助用户哭天喊地甚至骂我们,我们通过对chef的集成,可以一键更新所有的虚拟机,在指定的虚拟机上安装指定的软件。有了chef工具,为虚拟机打补丁、安装软件,只需要几个简单的命令即可搞定。
可持续性
做运维不要故障处理办法是不行,而且还要自动化的,同时我们有vmware和kvm,就需要新平台能在esxi上(不要vcenter,要付钱的)和kvm同时实现ha功能
可运维性
一个平台再强大,技术再厉害,如果不可运维,那结果可想而知。因此我们希望OVM可以给用户带来一个稳定、可控、安全的生产环境
弹性伸缩
自助服务部门拿到资源后,通过对各项目资源的限额,以及对各虚拟机和容器性能指标的实时监控,可以实现弹性的资源伸缩,达到合理分配利用资源。
资源池化
将数据中心的计算、存储、网络资源全部池化,然后通过OVM虚拟化平台统一对外提供IaaS服务。
2、OVM设计思路
OVM架构选型一
我们觉得架构就是一个产品的灵魂所在,决定着产品日后的发展。
我们团队在产品选型初期,分别调研了目前比较热门的openstack,以及前几年的明星产品convirt、ovirt,这几个产品可谓是典型的代表。
Openstack偏重于公有云,架构设计的很不错,其分布式、插件式的模块化架构,可以有效避免单点故障的发生,从发布之初便备受推崇,但是其存在的问题也同样令人头疼目前使用Openstack的大多是一些有实力的IDC、大型的互联网公司在用。而对于一般的企业来说,没有强大的开发和维护团队,并不敢大规模的采用openstack,初期使用一段时间后我们放弃了OS。
而前几年的convirt,在当时也掀起了一股使用热潮,其简单化的使用体验,足以满足小企业的虚拟化需求,但是他的问题是架构采用了集中式的架构,而且对于上了规模之后,也会带来性能方面的瓶颈,除非是把数据库等一些组件松藕合,解决起来也比较麻烦,所以到了后期也是不温不火,官方也停止了社区的更新和维护。
OVM架构选型二
通过对以上产品的优劣势分析,我们决定采用用分布式、松耦合的模块化插件架构,分布式使其可以规避单点故障,达到业务持续高可用,松耦合的模块化特点让产品在后期的扩展性方面不受任何限制,使其向下可以兼容数据中心所有硬件(通过OVM标准的Rest API接口),向上可以实现插件式的我们即将需要的工作流引擎、计费引擎、报表引擎、桌面云引擎和自动化运维引擎。
而目前阶段我们则专心于实现虚拟化的全部功能,发掘内部对虚拟化的需求,打造一款真正简单、易用、稳定、可运维的一款虚拟化管理软件,并预留向上、向下的接口留作后期发展。(架构图大家可以查看刚才上面发的图片)
虚拟化技术选择
Docker当下很火,其轻量级、灵活、高密度部署是优点,但是大规模使用还未成熟。许多场景还是需要依赖传统的虚拟化技术。所以我们选择传统虚拟化技术KVM+Docker,确保线上业务稳定性、连续性的同时,开发、测试环境又可以利用到Docker的轻量级、高密度和灵活。
另外很多用户的生产环境存在不止一种虚拟化技术,例如KVM+Esxi组合、KVM+XenServer组合、KVM+Hyper-V组合,而目前的虚拟化管理平台,大多都是只支持一种Hypervisor的管理,用户想要维护不同的虚拟化技术的虚拟机,就要反复的在不同环境之间切换。
基于此考虑,我和团队内部和外部一些同行选择兼容(兼容KVM、Esxi,Docker),并自主打造新一代虚拟化管理平台——混合虚拟化。
网络
网络方面,我们对所有Hypervisor的虚拟机使用统一的网络管理(包括Docker容器),这样做的一个好处就是可以减少运维工作量,降低网络复杂性。初期我们只实现2层的虚拟网络管理,为虚拟机和容器提供Vlan隔离、DHCP分配网络,当然也可以手工为虚拟机挑选一个网络,这个可以满足一般的虚拟化需求,后期我们会在此基础上增加虚拟网络防火墙、负载均衡。
存储
存储上面我们采用本地存储+NFS两种方式,对于一般中小企业来说,不希望购买高昂的商业存储,直接使用本地存储虚拟机的性能是最好的,而且我们也提供了存储快照、存储热迁移、虚拟机的无共享热迁移来提升业务安全。此外NFS作为辅助,可以为一些高风险业务提供HA。后期存储方面我们会考虑集成Ceph和GlusterFS存储来提升存储管理。
镜像中心
顾名思义,镜像中心就是用来存放镜像的。传统虚拟化我们使用NFS来作为镜像中心,所有宿主机共享一个镜像中心,这样可以更方便的来统一管理镜像,而针对Docker容器则保留了使用Docker自己的私有仓库,但是我们在WEB UI的镜像中心增加了从Docker私有仓库下载模板这么一个功能,实现了在同一个镜像中心的管理,后期我们会着重打造传统虚拟化镜像与Docker镜像的相互转换,实现两者内容的统一。
HA
OVM 主机HA依然坚持全兼容策略,支持对可管理的所有Hypervisor的HA。
在启用HA的资源池,当检测到一个Hypervisor故障,创建和运行在该Hypervisor共享存储上的虚拟机将在相同资源池下的另外一个主机上重启。
具体工作流程为:
第一次检测到故障会将该故障主机标记;
第二次检测依然故障将启动迁移任务;
迁移任务启动后将在该故障主机所在的资源池寻找合适的主机;
确定合适主机后,会将故障主机上所有的虚拟机自动迁移到合适的主机上面并重新启动;
VM分配策略
负载均衡
PERFORMANCE(性能): 这条策略分配虚拟机到不同的主机上。它挑选一组中可用资源最多的主机来部署虚拟机。如果有多个主机都有相同的资源可用,它使用一个循环算法,每个虚拟机分配到一个不同的主机上。
PROGRESSIVE(逐行扫描): 这条策略意味着,所有虚拟机将被分配在同一个主机上,直到它的资源被用尽。此项策略将一个主机资源使用完,然后再切换到另一个主机。
负载均衡级别
所有资源池: 如果选定此选项,则负载均衡级别策略将适用于所选定数据中心的所有资源池中的主机。
所有主机: 该策略将适用于所选数据中心单个资源池的所有主机。
特定主机: 该策略仅适用于所选的特定主机。
VM设计一
VM是整个虚拟化平台的核心,我们开发了一个单独的模块来负责虚拟机的相关操作。其采用异步通信和独立的并行操作,提升了虚拟机性能、稳定性和扩展性。
可扩展性:独立、并发
可追溯性:错误信息和log、监控控制台、性能
非阻塞操作:稳定性、改进重新配置、改进回滚、标准、统一的hypervisor通信、自动化测试
VM设计二
我们设计基于vApp来部署虚拟机,一个vApp可包含N个虚拟机:
N 个虚拟机配置
N个开机请求
我们希望并行运行N个配置(要求资源允许),并在配置后每个虚拟机请求一个开机。这些操作都是并发和独立的。
平台设计
OVM产品目前由三大组件、七大模块组成。其中三大组件分别为OVM UI、OVM API和OVM数据中心组件。
OVM UI提供WEB自服务界面,OVM API负责UI和数据中心组件之间的交互,OVM数据中心组件分别提供不同的功能。七大模块分别负责不同的功能实现,和三大组件之间分别交互。
VDC资源限额
管理员可以为每个VDC设置资源限额,防止资源的过度浪费。
账户管理
OVM提供存储SDK、备份SDK,以及虚拟防火墙SDK,轻松与第三方实现集成
获得帮助
下载请访问OVM社区官网:51ovm.com
使用过程中遇到什么问题及获得下载密码,加入OVM社区qq官方交流群:22265939
“ 实践是检验真理唯一标准“,OVM社区视您为社区的发展动力,此刻,诚邀您参与我们的调查,共同做出一款真正解决问题、放心的产品,一起推动国内虚拟化的进步和发展。
填写调查问卷!只需1分钟喔!
docker web化管理
开源项目 Something 发表了文章 4 个评论 8330 次浏览 2016-01-05 18:03
背景
目前很多公司都在使用docker,docker也是一种趋势,我们公司也在使用docker,所以我也跟着学习使用docker,根据基本需求,结合api做了一个web程序
实验环境
本次试验使用两台实体机做模拟docker集群,一台虚拟机做docker镜像服务器,一台虚拟机做web管理机原理图:
系统软件环境及版本:
selinux disabled
iptables -F
三台docker机器系统使用centos7.1,两台模拟机群docker机软件docker+pipework+openswitch+etcd+dhcp,docker镜像服务器跑了一个registry容器提供镜像服务
Web管理机使用ubuntu,python+django+uwsgi

程序流程图:

原理
通过web界面创建删除容器和镜像,web服务器通过api操作三台docker机器,创建容器时通过dhcp获取ip,pipework给容器附上获取的ip,并把容器信息写入etcd库中,由于容器重启后ip消失,我通过监控脚本给启动没有ip的容器重新附上ip。容器支持ssh,有好处也有风险。
网络这块我是用交换机提供的网段,容器使用的ip和实体机在同一valn,你也可以一个集群使用一个valn,这里我是用同一valn。容器ip可以从交换机dhcp获取,不懂交换机,我直接用一台docker实体机起了dhcp服务,为该段提供dhcp服务。
安装
1.1 docker集群节点
两台机器软件一样,我就以AB区别,软件基本一样,A多了一个dhcp,没有使用交换机提供dhcp1.2 安装openswitch:
如果后期不想在docker集群中划分vlan,可以使用系统自带的brctl命令创建桥接网卡,下面创建桥接网卡的脚本相应的变一下,ovs-vsctl改为brctl1.3 下载pipework:
yum install gcc make python-devel openssl-devel kernel-devel graphviz kernel-debug-devel autoconf automake rpm-build redhat-rpm-config libtool
wget http://openvswitch.org/releases/openvswitch-2.3.1.tar.gz
tar zxvf openvswitch-2.3.1.tar.gz
mkdir -p ~/rpmbuild/SOURCES
cp openvswitch-2.3.1.tar.gz ~/rpmbuild/SOURCES/
sed 's/openvswitch-kmod, //g' openvswitch-2.3.1/rhel/openvswitch.spec > openvswitch-2.3.1/rhel/openvswitch_no_kmod.spec
rpmbuild -bb --without check openvswitch-2.3.1/rhel/openvswitch_no_kmod.spec
#之后会在~/rpmbuild/RPMS/x86_64/里有2个文件
-rw-rw-r-- 1 ovswitch ovswitch 2013688 Jan 15 03:20 openvswitch-2.3.1-1.x86_64.rpm
-rw-rw-r-- 1 ovswitch ovswitch 7712168 Jan 15 03:20 openvswitch-debuginfo-2.3.1-1.x86_64.rpm
yum localinstall ~/rpmbuild/RPMS/x86_64/openvswitch-2.3.1-1.x86_64.rpm
systemctl enable openvswitch
systemctl start openvswitch
git clone https://github.com/jpetazzo/pipework.git1.4 网卡配置
chmod +x pipework
cp pipework /usr/bin/pipework
脚本下载地址
在节点机器上1.5 安装docker
pwd
/root
check_modify_container.py create_docker_container_use_dhcp_ip.sh openvswitch_docker.sh
#openvswitch_docker.sh 是网卡初始化脚本
#create_docker_container_use_dhcp_ip.sh 是创建容器时会调用的脚本
#check_modify_container.py 容器ip监控脚本
crontab -e
[i]/5 [/i] [i] [/i] * python /root/check_modify_container.py #监控脚本每五分钟执行一次
em1 为管理网段ip
Ovs1桥接在em2上,为docker内网网段ip
配置网卡,这里使用桥接
cat openvswitch_docker.sh
#!/bin/bash
#删除docker测试机
#docker rm `docker stop $(docker ps -a -q)`
#删除已有的openvswitch交换机
ovs-vsctl list-br|xargs -I {} ovs-vsctl del-br {}
#创建交换机
ovs-vsctl add-br ovs1
#把物理网卡加入ovs1
ovs-vsctl add-port ovs1 em2
ip link set ovs1 up
ifconfig em2 0
ifconfig ovs1 192.168.157.21 netmask 255.255.255.0
chmod +x openvswitch_docker.sh
sh openvswitch_docker.sh
也可以写到配置文件中
我的em1为管理网卡10.0.0.21
A机器中安装dhcp,集群中一台机器配置dhcp就可以了,网段根据你的环境改变
yum install -y dhcp
vim /etc/dhcp/dhcpd.conf
log-facility local7;
ddns-update-style none;
subnet 192.168.157.0 netmask 255.255.255.0 {
range 192.168.157.100 192.168.157.200;
option domain-name-servers 202.106.0.20;
option routers 192.168.157.1;
option broadcast-address 192.168.157.255;
default-lease-time 80000;
max-lease-time 80000;
}
systemctl enable dhcpd
systemctl start dhcpd
yum install -y docker1.6 Etcd安装
vim /etc/sysconfig/docker
OPTIONS='--selinux-enabled --insecure-registry 192.168.46.130:5000 -b=none -H tcp://0.0.0.0:2375 -H unix:///var/run/docker.sock'
#指定镜像服务器为192.168.46.130,net使用none模式,监听2375端口,这个端口提供api访问的
systemctl start docker.service
systemctl enable docker.service
yum install libffi libffi-devel python-devel2.1 docker镜像服务器
yum -y install epel-release
yum -y install python-pip
yum install etcd -y
vim /etc/etcd/etcd.conf
ETCD_NAME=default
ETCD_DATA_DIR="/var/lib/etcd/default.etcd"
ETCD_LISTEN_CLIENT_URLS="http://localhost:2379"
ETCD_ADVERTISE_CLIENT_URLS="http://localhost:2379"
[size=16]#这里etcd我没有做成集群,每台docker机的数据就保存在本机的etcd库中,不与其他节点同步,也不需要提供其他节点访问,这里设置监听本机[/size]
systemctl enable etcd
systemctl start etcd
镜像服务器在安装配置完docker后,从官网pull下来一个registry镜像,启动创建一个镜像服务器容器
docker search registry
docker pull docker.io/registry
docker run --restart always -d -p 5000:5000 -v /opt/data/registry:/tmp/registry docker.io/registry
安装docker请重复1.53.1 web服务器
Django web程序下载地址
Web服务器系统我用的ubuntu,主要是安装软件简单,源及软件更新比较快
[quote]>> import django
>>> django.VERSION
(1, 7, 1, 'final', 0)这是我的django版本
apt-get install mysql-server mysql-client
apt-get install python-pip
pip install Django==1.7.1 #你也可以安装最新版本,不确定我写的程序能否正常运行
apt-get install python-mysqldb
pip install docker-py #要调用docker api,所以要安装相关python包
apt-get install curl
apt-get install mysql-server
apt-get isntall mysql-client
sudo apt-get install libmysqlclient-dev
apt-get install python-paramiko #web程序中也会用到curl和paramiko
git clone https://github.com/SomethingCM/Web-for-docker.git 到本地
cd Web-for-docker/docker_demo
vim docker_demo/settings.py
#修改数据库配置
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.mysql',
'NAME': 'docker', #docker 库名
'USER': 'root', #mysql登陆用户
'PASSWORD': 'dockerchen',#密码,如果mysql设置了用户名密码可以填写,没有则为空
'HOST':'',
'PORT':'',
}
}
#修改完以后创建表
./manage.py syncdb
#执行的时候会让你设置后台root用户密码,两次输入密码创建表成功
./manage.py runserver 0.0.0.0:80
初始化设置
在浏览器中输入 IP:port/admin 设置后台 IP为web服务器的ip登陆后台admin初始化设置


添加仓库节点

添加节点



前台登陆



编写dockerfile创建镜像


把现有容器打包成镜像

创建容器

关于怎么用django+uwsgi发布网站这里就不叙述了
由于各种原因项目中途GAMEOVE了,没有具体的需求,不知道如何往下写了,有兴趣的朋友可以参考一下[/quote]
浅谈docker文件系统分层与隔离
大数据 空心菜 发表了文章 0 个评论 4907 次浏览 2015-08-28 01:27

Docker 的很多特性都表现在它所使用的文件系统上,比如大家都知道docker的文件系统是分层的,所以它可以快速迭代,可以回滚。下面就聊一下我对docker文件系统的理解
Docker 使用的支持的文件系统有以下几种: aufs、devicemapper、btrfs Vfs 我们先来介绍一下aufs
一、 Aufs(advanced multi layered unification filesystem)
Aufs直译过来就是高级分层统一文件系统。做为一种Union FS 它支持将不同的目录挂载到同一个虚拟文件系统下. 这个怎么理解呢。通过一条命令我们来看一下吧。
mount -t aufs -o br=/tmp/dir1=ro:/tmp/dir2=rw none /tmp/newfs
- []-o 指定mount传递给文件系统的参数[/][]br 指定需要挂载的文件夹,这里包括dir1和dir2[/][]ro/rw 指定文件的权限只读和可读写[/][]none 这里没有设备,用none表示[/]
这个结果是什么样子的呢。 就是把/tmp/dir1 t和/tmp/dir2 合并之后挂载到/tmp/newfs ,如果这时在/tmp/dir1 下创建一个文件a /tmp/dir2下创建一个文件b 则 在/tmp/newfs 会看到a,b 这两个文件,并且a 是只读的, 如果有相同的文件则以先挂载的为准,后面挂载的操作会被忽略掉
通过对Aufs的理解,大家可以想像一下docker所谓的“layer”的概念。还是实际的例子说明一下。
一个镜像通过docker save 保存之后 会被打成一个tar 包,我们来看下这个tar包里都有些什么?
docker save cloud_jiankongbao:01.tar cloud_jiankongbao:01通过上面的语句我们把镜像保存出下来。可以看到,保存下来的是tar 包。 不是.iso文件^_^,镜像解压之后是什么呢?
ls .出现了四个目录文件,再通过
a005304e4e74c1541988d3d1abb170e338c1d45daee7151f8e82f8460634d329
d9bde94c518a16a886514758b6b4431200145ecd58e30c5633ac3c0256544d77
f1b10cd842498c23d206ee0cbeaa9de8d2ae09ff3c7af2723a9e337a6965d639
fb9cc58bde0c0a8fe53e6fdd23898e45041783f2d7869d939d7364f5777fde6f
repositories
docker images --tree大家可以看到,4个目录其实分别是4个ID(注每次使用docker commit 提供对docker的修改之后就会产生一个新的id,就是通过这个ID可以实现对镜像的回滚)。每个目录下有json layer.tar VERSION 这三个文件。我们再看一下layer.tar
└─f1b10cd84249 Virtual Size: 0 B
└─fb9cc58bde0c Virtual Size: 203.1 MB
└─a005304e4e74 Virtual Size: 203.1 MB
└─d9bde94c518a Virtual Size: 1.957 GB Tags: cloud_jiankongbao:01
cd fb9cc58bde0c0a8fe53e6fdd23898e45041783f2d7869d939d7364f5777fde6f;tar -xf layer.tar;ls这里存放的系统文件。
ls fb9cc58bde0c0a8fe53e6fdd23898e45041783f2d7869d939d7364f5777fde6f/
bin etc json lib lost+found mnt proc sbin srv tmp var
dev home layer.tar lib64 media opt root selinux sys usr VERSION
我们再看一下镜像的4个不同ID的系统。
f1b10cd84249 这个镜像是初始镜像,大小为0, fb9cc58bde0c 这个镜像是在f1b10cd84249基础上创建新的镜像,a005304e4e74是以fb9cc58bde0c为基础创建新的镜像。是树状继承的关系。我们再看下bin目录下的文件
ls a005304e4e74c1541988d3d1abb170e338c1d45daee7151f8e82f8460634d329/bin/
gtar tar
ls fb9cc58bde0c0a8fe53e6fdd23898e45041783f2d7869d939d7364f5777fde6f/bin/a005304e4e74 只有两个文件 fb9cc58bde0c包括了大部分bin下的文件,这就是Aufs,理解起来感觉有点像增量备份。
arch cpio egrep gunzip logger mountpoint raw sleep true
awk cut env gzip login mv readlink sort umount
basename date ex hostname ls netstat rm stty uname
bash dd false ipcalc lsblk nice rmdir su unlink
cat df fgrep iptables-xml mkdir nisdomainname rpm sync usleep
chgrp dmesg find iptables-xml-1.4.7 mknod ping rvi taskset vi
chmod dnsdomainname findmnt kill mktemp ping6 rview touch view
chown domainname gawk link more ps sed tracepath ypdomainname
cp echo grep ln mount pwd sh tracepath6 zcat
二、简单的说一下devicemapper
devicemapper是利用了Snapshot 和Thinly-Provisioned Snapshot两种原理。将多个快照挂在同一个卷下从而实现文件系统的分层。不过使用devicemapper 的话一个container的大小最大只能是10G。
在启动docker daemon时用参数-s 指定: docker -d -s devicemapper
关于隔离是怎么实现的呢,当容器基于镜像启动之后,每个容器都会获得自己的写读可写的文件系统层。原镜像的那部分文件系统是只读的,从而实现每个容器的在文件系统上的离隔。
平时大家都在说dokcer 是弱隔离的,为什么呢?因为他没有隔离的很彻底,比如内核,内核是跟大家共用的,跟宿主机共用同一个内核,SELinux、 Cgroups以及/sys、/proc/sys、/dev/sd*等目录下的资源是与宿主机共用的。
如果要隔离的彻底那就是VM了,而且如果dockers要想实现这些隔离就必然要牺牲一下现在轻量级的特性。那还不如直接用虚拟机好了!
文章转载出处
Docker入门学习
DevOps Ansible 发表了文章 2 个评论 4090 次浏览 2015-06-23 02:05

Docker是什么
Docker是一种容器技术,它可以将应用和环境等进行打包,形成一个独立的,类似于iOS的APP形式的“应用”,这个应用可以直接被分发到任意一个支持Docker的环境中,通过简单的命令即可启动运行。Docker是一种最流行的容器化实现方案。和虚拟化技术类似,它极大的方便了应用服务的部署;又与虚拟化技术不同,它以一种更轻量的方式实现了应用服务的打包。使用Docker可以让每个应用彼此相互隔离,在同一台机器上同时运行多个应用,不过他们彼此之间共享同一个操作系统。Docker的优势在于,它可以在更细的粒度上进行资源的管理,也比虚拟化技术更加节约资源。
上图:虚拟化和Docker架构对比,来自Docker官网
基本概念
开始试验Docker之前,我们先来了解一下Docker的几个基本概念:
镜像:我们可以理解为一个预配置的系统光盘,这个光盘插入电脑后就可以启动一个操作系统。当然由于是光盘,所以你无法修改它或者保存数据,每次重启都是一个原样全新的系统。Docker里面镜像基本上和这个差不多。
容器:同样一个镜像,我们可以同时启动运行多个,运行期间的产生的这个实例就是容器。把容器内的操作和启动它的镜像进行合并,就可以产生一个新的镜像。
开始
Docker基于LXC技术实现,依赖于Linux内核,所以Docker目前只能在Linux以原生方式运行。目前主要的Linux发行版在他们的软件仓库中内置了Docker:
Ubuntu: Ubuntu Trusty 14.04 (LTS) Ubuntu Precise 12.04 (LTS) Ubuntu Saucy 13.10
CentOS: Centos7
Docker要求64位环境,这些操作系统下可以直接通过命令安装Docker,老一些操作系统Docker官方也提供了安装方案。下面的实验基于CentOS 7进行。关于其他版本操作系统上Docker的安装,请参考官方文档:https://docs.docker.com/installation/ 。
在CentOS 7上安装Docker
使用yum从软件仓库安装Docker:
yum install docker
首先启动Docker的守护进程:
service docker start
如果想要Docker在系统启动时运行,执行:
chkconfig docker on
Docker在CentOS上好像和防火墙有冲突,应用防火墙规则后可能导致Docker无法联网,重启Docker可以解决。
Docker仓库
Docker使用类似git的方式管理镜像。通过基本的镜像可以定制创建出来不同种应用的Docker镜像。Docker Hub是Docker官方提供的镜像中心。在这里可以很方便地找到各类应用、环境的镜像。
由于Docker使用联合文件系统,所以镜像就像是夹心饼干一样一层层构成,相同底层的镜像可以共享。所以Docker还是相当节约磁盘空间的。要使用一 个镜像,需要先从远程的镜像注册中心拉取,这点非常类似git。
docker pull ubuntu
我们很容易就能从Docker Hub镜像注册中心下载一个最新版本的ubuntu镜像到本地。国内网络可能会稍慢,DAOCLOUD提供了Docker Hub的国内加速服务,可以尝试配置使用。
运行一个容器
使用Docker最关键的一步就是从镜像创建容器。有两种方式可以创建一个容器:使用docker create命令创建容器,或者使用docker run命令运行一个新容器。两个命令并没有太大差别,只是前者创建后并不会立即启动容器。
以ubuntu为例,我们启动一个新容器,并将ubuntu的Shell作为入口:
docker run -i -t ubuntu /bin/bash
这时候我们成功创建了一个Ubuntu的容器,并将当前终端连接为这个Ubuntu的bash shell。这时候就可以愉快地使用Ubuntu的相关命令了~可以快速体验一下。
参数-i表示这是一个交互容器,会把当前标准输入重定向到容器的标准输入中,而不是终止程序运行。-t指为这个容器分配一个终端。
好了,按Ctrl+D可以退出这个容器了。
在容器运行期间,我们可以通过docker ps命令看到所有当前正在运行的容器。添加-a参数可以看到所有创建的容器:
[root@localhost ~]# docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
cb2b06c83a50 ubuntu:latest "sh -c /bin/bash" 7 minutes ago Exited (0) 7 seconds ago trusting_morse
每个容器都有一个唯一的ID标识,通过ID可以对这个容器进行管理和操作。在创建容器时,我们可以通过–name参数指定一个容器名称,如果没有指定系统将会分配一个,就像这里的“trusting_morse”(什么鬼TAT)。
当我们按Ctrl+D退出容器时,命令执行完了,所以容器也就退出了。要重新启动这个容器,可以使用docker start命令:
docker start -i trusting_morse
同样,-i参数表示需要交互式支持。
注意: 每次执行docker run命令都会创建新的容器,建议一次创建后,使用docker start/stop来启动和停用容器。
存储
在Docker容器运行期间,对文件系统的所有修改都会以增量的方式反映在容器使用的联合文件系统中,并不是真正的对只读层数据信息修改。每次运行容器对它的修改,都可以理解成对夹心饼干又添加了一层奶油。这层奶油仅供当前容器使用。当删除Docker容器,或通过该镜像重新启动时,之前的更改将会丢失。这样做并不便于我们持久化和共享数据。Docker的数据卷这个东西可以帮到我们。
在创建容器时,通过-v参数可以指定将容器内的某个目录作为数据卷加载:
docker run -i -t -v /home/www ubuntu:latest sh -c '/bin/bash'
在容器中会多一个/home/www挂载点,在这个挂载点存储数据会绕过联合文件系统。我们可以通过下面的命令来找到这个数据卷在主机上真正的存储位置:
docker inspect -f {{.Volumes}} trusting_morse
你会看到输出了一个指向到/var/lib/docker/vfs/dir/...的目录。cd进入后你会发现在容器中对/home/www的读写创建,都会反映到这儿。事实上,/home/www就是挂载自这个位置。
有时候,我们需要将本地的文件目录挂载到容器内的位置,同样是使用数据卷这一个特性,-v参数格式为:
docker run -it -v [host_dir]:[container_dir]
host_dir是主机的目录,container_dir是容器的目录.
容器和容器之间是可以共享数据卷的,我们可以单独创建一些容器,存放如数据库持久化存储、配置文件一类的东西,然而这些容器并不需要运行。
docker run --name dbdata ubuntu echo "Data container."
在需要使用这个数据容器的容器创建时–volumes-from [容器名]的方式来使用这个数据共享容器。
网络
Docker容器内的系统工作起来就像是一个虚拟机,容器内开放的端口并不会真正开放在主机上。可以使我们的容器更加安全,而且不会产生容器间端口的争用。想要将Docker容器的端口开放到主机上,可以使用类似端口映射的方式。
在Docker容器创建时,通过指定-p参数可以暴露容器的端口在主机上:
docker run -it -p 22 ubuntu sh -c '/bin/bash'
现在我们就将容器的22端口开放在了主机上,注意主机上对应端口是自动分配的。如果想要指定某个端口,可以通过-p [主机端口]:[容器端口]参数指定。
容器和容器之间想要网络通讯,可以直接使用–link参数将两个容器连接起来。例如WordPress容器对some-mysql的连接:
docker run --name some-wordpress --link some-mysql:mysql -p 8080:80 -d wordpress
环境变量
通过Docker打包的应用,对外就像是一个密闭的exe可执行文件。有时候我们希望Docker能够使用一些外部的参数来使用容器,这时候参数可以通过环境变量传递进去,通常情况下用来传递比如MySQL数据库连接这种的东西。环境变量通过-e参数向容器传递:
docker run --name some-wordpress -e WORDPRESS_DB_HOST=10.1.2.3:3306 \
-e WORDPRESS_DB_USER=... -e WORDPRESS_DB_PASSWORD=... -d wordpress
关于Docker到现在就有了一个基本的认识了。接下来我会给大家介绍如何创建镜像。
创建镜像
Docker强大的威力在于可以把自己开发的应用随同各种依赖环境一起打包、分发、运行。要创建一个新的Docker镜像,通常基于一个已有的Docker镜像来创建。Docker提供了两种方式来创建镜像:把容器创建为一个新的镜像、使用Dockerfile创建镜像。
将容器创建为镜像
为了创建一个新的镜像,我们先创建一个新的容器作为基底:
docker run -it ubuntu:latest sh -c '/bin/bash'
现在我们可以对这个容器进行修改了,例如我们可以配置PHP环境、将我们的项目代码部署在里面等:
apt-get install php
# some other opreations ...
当执行完操作之后,我们按Ctrl+D退出容器,接下来使用docker ps -a来查找我们刚刚创建的容器ID:
docker ps -a
可以看到我们最后操作的那个ubuntu容器。这时候只需要使用docker commit即可把这个容器变为一个镜像了:
docker commit 8d93082a9ce1 ubuntu:myubuntu
这时候docker容器会被创建为一个新的Ubuntu镜像,版本名称为myubuntu。以后我们可以随时使用这个镜像来创建容器了,新的容器将自动包含上面对容器的操作。
如果我们要在另外一台机器上使用这个镜像,可以将一个镜像导出:
docker save -o myubuntu.tar.gz ubuntu:myubuntu
现在我们可以把刚才创建的镜像打包为一个文件分发和迁移了。要在一台机器上导入镜像,只需要:
docker import myubuntu.tar.gz
这样在新机器上就拥有了这个镜像。
注意:通过导入导出的方式分发镜像并不是Docker的最佳实践,因为我们有Docker Hub。
Docker Hub提供了类似GitHub的镜像存管服务。一个镜像发布到Docker Hub不仅可以供更多人使用,而且便于镜像的版本管理。关于Docker Hub的使用,之后我会单独写一篇文章展开介绍。另外,在一个企业内部可以通过自建docker-registry的方式来统一管理和发布镜像。将Docker Registry集成到版本管理和上线发布的工作流之中,还有许多工作要做,在我整理出最佳实践后会第一时间分享。
使用Dockerfile创建镜像
使用命令行的方式创建Docker镜像通常难以自动化操作。在更多的时候,我们使用Dockerfile来创建Docker镜像。Dockerfile是一个纯文本文件,它记载了从一个镜像创建另一个新镜像的步骤。撰写好Dockerfile文件之后,我们就可以轻而易举的使用docker build命令来创建镜像了.
Dockerfile非常简单,仅有以下命令在Dockerfile中常被使用:
下面是一个Dockerfile的例子:
# This is a comment
FROM ubuntu:14.04
MAINTAINER Kate Smith <ksmith@example.com>
RUN apt-get update && apt-get install -y ruby ruby-dev
RUN gem install sinatra
这里其他命令都比较好理解,唯独CMD和ENTRYPOINT我需要特殊说明一下。CMD命令可用指定Docker容器启动时默认的命令,例如我们上面例子提到的docker run -it ubuntu:latest sh -c '/bin/bash'。其中sh -c '/bin/bash'就是通过手工指定传入的CMD。如果我们不加这个参数,那么容器将会默认使用CMD指定的命令启动。ENTRYPOINT是什么呢?从字面看是进入点。没错,它就是进入点。ENTRYPOINT用来指定特定的可执行文件、Shell脚本,并把启动参数或CMD指定的默认值,当作附加参数传递给ENTRYPOINT。
不好理解是吧?我们举一个例子:
ENTRYPOINT ['/usr/bin/mysql']
CMD ['-h 192.168.100.128', '-p']
假设这个镜像内已经准备好了mysql-client,那么通过这个镜像,不加任何额外参数启动容器,将会给我们一个mysql的控制台,默认连接到192.168.100.128这个主机。然而我们也可以通过指定参数,来连接别的主机。但是不管无论如何,我们都无法启动一个除了mysql客户端以外的程序。因为这个容器的ENTRYPOINT就限定了我们只能在mysql这个客户端内做事情。这下是不是明白了。
因此,我们在使用Dockerfile创建文件的时候,可以创建一个entrypoint.sh脚本,作为系统入口。在这个文件里面,我们可以进行一些基础性的自举操作,比如检查环境变量,根据需要初始化数据库等等。下面两个文件是我在SimpleOA项目中添加的Dockerfile和entrypoint.sh,仅供参考:
https://github.com/starlight36/SimpleOA/blob/master/Dockerfile https://github.com/starlight36/SimpleOA/blob/master/docker-entrypoint.sh
在准备好Dockerfile之后,我们就可以创建镜像了:
docker build -t starlight36/simpleoa .
关于Dockerfile的更详细说明,请参考 https://docs.docker.com/reference/builder/
杂项和最佳实践
在产品构建的生命周期里使用Docker,最佳实践是把Docker集成到现有的构建发布流程里面。这个过程并不复杂,可以在持续集成系统构建测试完成后,将打包的步骤改为docker build,持续集成服务将会自动将构建相应的Docker镜像。打包完成后,可以由持续集成系统自动将镜像推送到Docker Registry中。生产服务器可以直接Pull最新版本的镜像,更新容器即可很快地实现更新上线。目前Atlassian Bamboo已经支持Docker的构建了。
由于Docker使用联合文件系统,所以并不用担心多次发布的版本会占用更多的磁盘资源,相同的镜像只存储一份。所以最佳实践是在不同层次上构建Docker镜像。比如应用服务器依赖于PHP+Nginx环境,那么可以把定制好的这个PHP环境作为一个镜像,应用服务器从这个镜像构建镜像。这样做的好处是,如果PHP环境要升级,更新了这个镜像后,重新构建应用镜像即可完成升级,而不需要每个应用项目分别升级PHP环境。
新手经常会有疑问的是关于Docker打包的粒度,比如MySQL要不要放在镜像中?最佳实践是根据应用的规模和可预见的扩展性来确定Docker打包的粒度。例如某小型项目管理系统使用LAMP环境,由于团队规模和使用人数并不会有太大的变化(可预计的团队规模范围是几人到几千人),数据库也不会承受无法承载的记录数(生命周期内可能一个表最多会有数十万条记录),并且客户最关心的是快速部署使用。那么这时候把MySQL作为依赖放在镜像里是一种不错的选择。当然如果你在为一个互联网产品打包,那最好就是把MySQL独立出来,因为MySQL很可能会单独做优化做集群等。
使用公有云构建发布运行Docker也是个不错的选择。DaoCloud提供了从构建到发布到运行的全生命周期服务。特别适合像微擎这种微信公众平台、或者中小型企业CRM系统。上线周期更短,比使用IAAS、PAAS的云服务更具有优势。
参考资料:
深入理解Docker Volume
WordPress https://registry.hub.docker.com/_/wordpress/
Docker学习—镜像导出 http://www.sxt.cn/u/756/blog/5339
Dockerfile Reference https://docs.docker.com/reference/builder/
关于Dockerfile http://blog.tankywoo.com/docker/2014/05/08/docker-2-dockerfile.html
Docker 安全:通过 Docker 提升权限
大数据 Ansible 发表了文章 0 个评论 5512 次浏览 2015-06-22 14:37

如果你对 Docker 不熟悉的话,简单来说,Docker 是一个轻量级的应用容器。和常见的虚拟机类似,但是和虚拟机相比,资源消耗更低。并且,使用和 GitHub 类似的被 commit 的容器,非常容易就能实现容器内指定运行环境中的应用打包和部署。
问题
如果你有服务器上一个普通用户的账号,如果这个用户被加入了 docker 用户组,那么你很容易就能获得宿主机的 root 权限。
黑魔法:docker run -v /:/hostOS -i -t chrisfosterelli/rootplease
输出如下:
johndoe@testmachine:~$ docker run -v /:/hostOS -i -t chrisfosterelli/rootplease
[...]
You should now have a root shell on the host OS
Press Ctrl-D to exit the docker instance / shell
# whoami
root #此处是容器内部,但是容器已经 chroot /hostOS,所以相当于直接获取了宿主机的 root 权限。
译者一直以为是 Ctrl-D 之后,宿主机的 shell 变成 root,实际上不是。
咨询了作者 Chris Foster 得知,是在容器内获得宿主机的 root 权限。
是不是想起了以前译者在 Docker 安全 中提到的容器内部的 UID=0 对容器外部某个不明程序执行了 chmod +s?
解释
当然,所有的解释汇成一句话,应该就是:docker 组内用户执行命令的时候会自动在所有命令前添加 sudo。因为设计或者其他的原因,Docker 给予所有 docker 组的用户相当大的权力(虽然权力只体现在能访问 /var/run/docker.sock 上面)。
默认情况下,Docker 软件包是会默认添加一个 docker 用户组的。Docker 守护进程会允许 root 用户和 docker 组用户访问 Docker。给用户提供 Docker 权限和给用户无需认证便可以随便获取的 root 权限差别不大。
解决方案
对于 Docker 来说可能很难修复,因为涉及到他们的架构问题,所以需要重写非常多的关键代码才能避免这个问题。我个人的建议是不要使用 docker 用户组。当然,Docker 官方文档中最好也很清楚地写明这一点。不要让新人不懂得“和 root 权限差别不大”是什么意思。
Docker 官方也意识到了这个问题,尽管他们并没有很明显地表明想去修复它。在他们的安全文档中,他们也的确表示 docker 用户组的权限和 root 权限差别不大,并且敬告用户慎重使用。
漏洞详情
上面那条命令 docker run -v /:/hostOS -i -t chrisfosterelli/rootplease,主要的作用是:从 Docker Hub 上面下载我的镜像,然后运行。参数-v将容器外部的目录/挂载到容器内部 /hostOS,并且使用 -i 和 -t 参数进入容器的 shell。
这个容器的启动脚本是 exploit.sh,主要内容是:chroot 到容器的 /hostOS (也就是宿主机的 /),然后获取到宿主机的 root 权限。
当然可以从这个衍生出非常多的提权方法,但是这个方法是最直接的。
本文中所提到的代码托管在 Github(https://github.com/chrisfosterelli/dockerrootplease),镜像在 Docker Hub(https://registry.hub.docker.com/u/chrisfosterelli/rootplease/)。
翻译原文链接:https://henduan.com/xXoHn
OVM混合虚拟化设计目标及设计思路
大数据 maoliang 发表了文章 0 个评论 3111 次浏览 2016-09-29 09:42
OVM是要实现混合虚拟化,做一个大一统的资源管理和交付平台,纵观虚拟化市场,现在当属开源的KVM和Docker最火,我们工作过去有vmware,现在大量使用kvm,未来一定会考虑docker,但现有市场上的产品要么架构太大,开发难度高,易用性不够强,要么就是单纯的虚拟化,类似vmware等。
新形式下,我们需要的产品要同时具备如下目标:
跨平台,支持KVM、Esxi和Docker容器
因为我们单位过去采用虚拟化技术混杂,上面又遗留很多虚拟机,这就要求我们新开发产品能够兼容不同hypervior,同时还能识别并管理原有hypervior上的虚拟机,能够识别并导入原数据库技术并不难,难的是导入后还能纳入新平台管理,这部分我们又研发了自动捕获技术,而不同混合虚拟化管理技术可以摆脱对底层Hypervisor的依赖,专心于资源的统一管理。
单独的用户自助服务门户
过去采用传统虚拟化时,解决了安装部署的麻烦,但资源的申请和扩容、准备资源和切割资源仍然没有变,还是要让我们做,占据了日常运维工作的大部分工作量,每天确实烦人,所以我们想而这部分工作是可以放给相关的部门Leader或者专员,来减少运维的工作量,所以我们希望新设计的OVM允许用户通过一个单独的Web门户来直接访问自己的资源(云主机、云硬盘、网络等),而且对自己的资源进行管理,而不需要知道资源的具体位置,同时用户的所有云主机都建立在高可用环境之上,也不必担心实际物理硬件故障引起服务瘫痪。
Opscode Chef自动化运维集成
实行自助服务后,有一个问题,就是软件不同版本部署不兼容,这就需要设计能够把操作系统、中间件、数据库、web能统一打包部署,减少自助用户哭天喊地甚至骂我们,我们通过对chef的集成,可以一键更新所有的虚拟机,在指定的虚拟机上安装指定的软件。有了chef工具,为虚拟机打补丁、安装软件,只需要几个简单的命令即可搞定。
可持续性
做运维不要故障处理办法是不行,而且还要自动化的,同时我们有vmware和kvm,就需要新平台能在esxi上(不要vcenter,要付钱的)和kvm同时实现ha功能
可运维性
一个平台再强大,技术再厉害,如果不可运维,那结果可想而知。因此我们希望OVM可以给用户带来一个稳定、可控、安全的生产环境
弹性伸缩
自助服务部门拿到资源后,通过对各项目资源的限额,以及对各虚拟机和容器性能指标的实时监控,可以实现弹性的资源伸缩,达到合理分配利用资源。
资源池化
将数据中心的计算、存储、网络资源全部池化,然后通过OVM虚拟化平台统一对外提供IaaS服务。
2、OVM设计思路
OVM架构选型一
我们觉得架构就是一个产品的灵魂所在,决定着产品日后的发展。
我们团队在产品选型初期,分别调研了目前比较热门的openstack,以及前几年的明星产品convirt、ovirt,这几个产品可谓是典型的代表。
Openstack偏重于公有云,架构设计的很不错,其分布式、插件式的模块化架构,可以有效避免单点故障的发生,从发布之初便备受推崇,但是其存在的问题也同样令人头疼目前使用Openstack的大多是一些有实力的IDC、大型的互联网公司在用。而对于一般的企业来说,没有强大的开发和维护团队,并不敢大规模的采用openstack,初期使用一段时间后我们放弃了OS。
而前几年的convirt,在当时也掀起了一股使用热潮,其简单化的使用体验,足以满足小企业的虚拟化需求,但是他的问题是架构采用了集中式的架构,而且对于上了规模之后,也会带来性能方面的瓶颈,除非是把数据库等一些组件松藕合,解决起来也比较麻烦,所以到了后期也是不温不火,官方也停止了社区的更新和维护。
OVM架构选型二
通过对以上产品的优劣势分析,我们决定采用用分布式、松耦合的模块化插件架构,分布式使其可以规避单点故障,达到业务持续高可用,松耦合的模块化特点让产品在后期的扩展性方面不受任何限制,使其向下可以兼容数据中心所有硬件(通过OVM标准的Rest API接口),向上可以实现插件式的我们即将需要的工作流引擎、计费引擎、报表引擎、桌面云引擎和自动化运维引擎。
而目前阶段我们则专心于实现虚拟化的全部功能,发掘内部对虚拟化的需求,打造一款真正简单、易用、稳定、可运维的一款虚拟化管理软件,并预留向上、向下的接口留作后期发展。(架构图大家可以查看刚才上面发的图片)
虚拟化技术选择
Docker当下很火,其轻量级、灵活、高密度部署是优点,但是大规模使用还未成熟。许多场景还是需要依赖传统的虚拟化技术。所以我们选择传统虚拟化技术KVM+Docker,确保线上业务稳定性、连续性的同时,开发、测试环境又可以利用到Docker的轻量级、高密度和灵活。
另外很多用户的生产环境存在不止一种虚拟化技术,例如KVM+Esxi组合、KVM+XenServer组合、KVM+Hyper-V组合,而目前的虚拟化管理平台,大多都是只支持一种Hypervisor的管理,用户想要维护不同的虚拟化技术的虚拟机,就要反复的在不同环境之间切换。
基于此考虑,我和团队内部和外部一些同行选择兼容(兼容KVM、Esxi,Docker),并自主打造新一代虚拟化管理平台——混合虚拟化。
网络
网络方面,我们对所有Hypervisor的虚拟机使用统一的网络管理(包括Docker容器),这样做的一个好处就是可以减少运维工作量,降低网络复杂性。初期我们只实现2层的虚拟网络管理,为虚拟机和容器提供Vlan隔离、DHCP分配网络,当然也可以手工为虚拟机挑选一个网络,这个可以满足一般的虚拟化需求,后期我们会在此基础上增加虚拟网络防火墙、负载均衡。
存储
存储上面我们采用本地存储+NFS两种方式,对于一般中小企业来说,不希望购买高昂的商业存储,直接使用本地存储虚拟机的性能是最好的,而且我们也提供了存储快照、存储热迁移、虚拟机的无共享热迁移来提升业务安全。此外NFS作为辅助,可以为一些高风险业务提供HA。后期存储方面我们会考虑集成Ceph和GlusterFS存储来提升存储管理。
镜像中心
顾名思义,镜像中心就是用来存放镜像的。传统虚拟化我们使用NFS来作为镜像中心,所有宿主机共享一个镜像中心,这样可以更方便的来统一管理镜像,而针对Docker容器则保留了使用Docker自己的私有仓库,但是我们在WEB UI的镜像中心增加了从Docker私有仓库下载模板这么一个功能,实现了在同一个镜像中心的管理,后期我们会着重打造传统虚拟化镜像与Docker镜像的相互转换,实现两者内容的统一。
HA
OVM 主机HA依然坚持全兼容策略,支持对可管理的所有Hypervisor的HA。
在启用HA的资源池,当检测到一个Hypervisor故障,创建和运行在该Hypervisor共享存储上的虚拟机将在相同资源池下的另外一个主机上重启。
具体工作流程为:
第一次检测到故障会将该故障主机标记;
第二次检测依然故障将启动迁移任务;
迁移任务启动后将在该故障主机所在的资源池寻找合适的主机;
确定合适主机后,会将故障主机上所有的虚拟机自动迁移到合适的主机上面并重新启动;
VM分配策略
负载均衡
PERFORMANCE(性能): 这条策略分配虚拟机到不同的主机上。它挑选一组中可用资源最多的主机来部署虚拟机。如果有多个主机都有相同的资源可用,它使用一个循环算法,每个虚拟机分配到一个不同的主机上。
PROGRESSIVE(逐行扫描): 这条策略意味着,所有虚拟机将被分配在同一个主机上,直到它的资源被用尽。此项策略将一个主机资源使用完,然后再切换到另一个主机。
负载均衡级别
所有资源池: 如果选定此选项,则负载均衡级别策略将适用于所选定数据中心的所有资源池中的主机。
所有主机: 该策略将适用于所选数据中心单个资源池的所有主机。
特定主机: 该策略仅适用于所选的特定主机。
VM设计一
VM是整个虚拟化平台的核心,我们开发了一个单独的模块来负责虚拟机的相关操作。其采用异步通信和独立的并行操作,提升了虚拟机性能、稳定性和扩展性。
可扩展性:独立、并发
可追溯性:错误信息和log、监控控制台、性能
非阻塞操作:稳定性、改进重新配置、改进回滚、标准、统一的hypervisor通信、自动化测试
VM设计二
我们设计基于vApp来部署虚拟机,一个vApp可包含N个虚拟机:
N 个虚拟机配置
N个开机请求
我们希望并行运行N个配置(要求资源允许),并在配置后每个虚拟机请求一个开机。这些操作都是并发和独立的。
平台设计
OVM产品目前由三大组件、七大模块组成。其中三大组件分别为OVM UI、OVM API和OVM数据中心组件。
OVM UI提供WEB自服务界面,OVM API负责UI和数据中心组件之间的交互,OVM数据中心组件分别提供不同的功能。七大模块分别负责不同的功能实现,和三大组件之间分别交互。
VDC资源限额
管理员可以为每个VDC设置资源限额,防止资源的过度浪费。
账户管理
OVM提供存储SDK、备份SDK,以及虚拟防火墙SDK,轻松与第三方实现集成
获得帮助
下载请访问OVM社区官网:51ovm.com
使用过程中遇到什么问题及获得下载密码,加入OVM社区qq官方交流群:22265939
“ 实践是检验真理唯一标准“,OVM社区视您为社区的发展动力,此刻,诚邀您参与我们的调查,共同做出一款真正解决问题、放心的产品,一起推动国内虚拟化的进步和发展。
填写调查问卷!只需1分钟喔!

