
盗墓笔记"盗"致爱奇艺服务器崩溃
爱奇艺会员为什么看不了视频,观众太多导致服务器奔溃,处理不了!
昨天,全民热播剧《盗墓笔记》准时在爱奇艺独家播出,而爱奇艺方面也如约放出了会员服务,只要开通爱奇艺会员就可以不用等每周五播放一集,而是可以全集观看《盗墓笔记》,这对于那些稻粉来说简直就是天大的好消息,对于那些痴迷于小哥、李易峰的粉丝来讲简直是大福利。但是,据悉许多开通了爱奇艺会员的网友并不能看完《盗墓笔记》全集,只是为什么呢?一起来看看原因吧!!
爱奇艺会员服务开放后,并没有什么用,因为爱奇艺的服务器不堪粉丝们的热情,所以直接歇菜了,然后就有一大波的粉丝在评论里留言,过激的语言可以看的出粉丝对此事件的不满,以下为爱奇艺官方通告: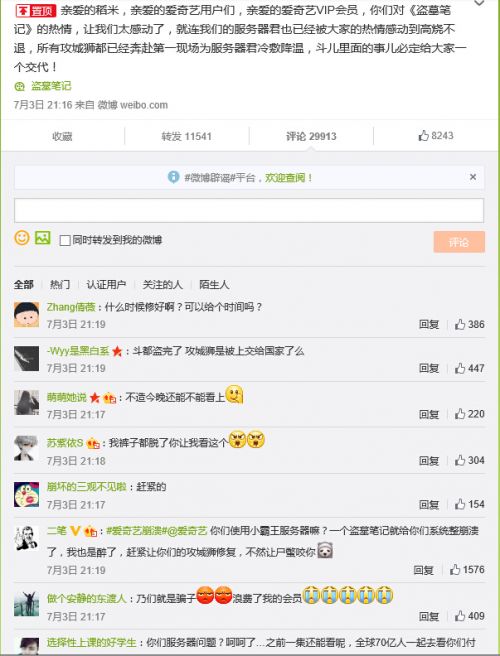

昨天,全民热播剧《盗墓笔记》准时在爱奇艺独家播出,而爱奇艺方面也如约放出了会员服务,只要开通爱奇艺会员就可以不用等每周五播放一集,而是可以全集观看《盗墓笔记》,这对于那些稻粉来说简直就是天大的好消息,对于那些痴迷于小哥、李易峰的粉丝来讲简直是大福利。
爱奇艺会员服务开放后,并没有什么用,因为爱奇艺的服务器不堪粉丝们的热情,所以直接歇菜了,然后就有一大波的粉丝在评论里留言,过激的语言可以看的出粉丝对此事件的不满,爱奇艺已发出解决此事的声明。来看看网友们的反应吧!
用户们的跟帖如下:
卡米妮vip:如果真的感到抱歉,就应该直接免费给大家看,觉得对的赞
527六子:爱奇艺你这是诈骗吗!我可是黄金VIP,为什么看不了!还没开播前,就说只要付钱买黄金VIP就不用等更新,今天又来这一出!而且客服还打不通!你们是卷款外逃了吗?还删我评论!服务器烧了,你还有理了?@爱奇艺VIP会员 @Althea丽亚 @成在为
MKISSHzz:我的电脑和手机都快炸了[doge] 如果你能给我李易峰男朋友的签名我就原谅你 [doge] 害我花了生活费冲会员[doge]还不让我好好的看[doge] 这样我就不能好好的复习
你在偷窥我:[微笑]爱奇艺垃圾。白开会员了。骗钱咯?
李泽彬彬彬彬彬:退钱退钱[怒骂][怒骂][怒骂]艹尼玛的
见鬼BIBABO:已经追完了,么么哒你们。但是我的VIP不知道为什么手机登录不上去了,我的VIP自动续费好像消失了么?我点自动续费显示要开通,可是已经开通了啊,还有啊,你们客服不理我[失望]
智齿恒齿:我真的受不了爱奇艺了 昨晚等到十二点多都看不了 今天早上起来能看了 结果盗墓笔记把第五集下了就又有问题了 又加载不出来了 盗墓笔记看完此生再不用爱奇艺了 绝不!!!!![怒骂][怒骂][怒骂]
喵喵尐怪嘼:你们自己网站出问题,害我输入密码不正确,每次都不正确!害我一次次通过绑定手机找回密码!结果昨日找回三次后还是不可以!今日想重新找回,却被警告禁止该手机接收短信!为什么?![怒][抓狂]我刚买的年会员!

PV、UV、IP概念
PV是网站分析的一个术语,用以衡量网站用户访问的网页的数量。对于广告主,PV值可预期它可以带来多少广告收入。一般来说,PV与来访者的数量成正比,但是PV并不直接决定页面的真实来访者数量,如同一个来访者通过不断的刷新页面,也可以制造出非常高的PV。

1、什么是PV
PV(page view) 即页面浏览量或点击量,是衡量一个网站或网页用户访问量。具体的说,PV值就是所有访问者在24小时(0点到24点)内看了某个网站多少个页面或某个网页多少次。PV是指页面刷新的次数,每一次页面刷新,就算做一次PV流量。
度量方法就是从浏览器发出一个对网络服务器的请求(Request),网络服务器接到这个请求后,会将该请求对应的一个网页(Page)发送给浏览器,从而产生了一个PV。那么在这里只要是这个请求发送给了浏览器,无论这个页面是否完全打开(下载完成),那么都是应当计为1个PV。
2、什么是UV
UV(unique visitor)即独立访客数,指访问某个站点或点击某个网页的不同IP地址的人数。在同一天内,UV只记录第一次进入网站的具有独立IP的访问者,在同一天内再次访问该网站则不计数。UV提供了一定时间内不同观众数量的统计指标,而没有反应出网站的全面活动。通过IP和cookie是判断UV值的两种方式: 用Cookie分析UV值
当客户端第一次访问某个网站服务器的时候,网站服务器会给这个客户端的电脑发出一个Cookie,通常放在这个客户端电脑的C盘当中。在这个Cookie中会分配一个独一无二的编号,这其中会记录一些访问服务器的信息,如访问时间,访问了哪些页面等等。当你下次再访问这个服务器的时候,服务器就可以直接从你的电脑中找到上一次放进去的Cookie文件,并且对其进行一些更新,但那个独一无二的编号是不会变的。
3、IP即独立IP数
IP可以理解为独立IP的访问用户,指1天内使用不同IP地址的用户访问网站的数量,同一IP无论访问了几个页面,独立IP数均为1。但是假如说两台机器访问而使用的是同一个IP,那么只能算是一个IP的访问。
IP和UV之间的数据不会有太大的差异,通常UV量和比IP量高出一点,每个UV相对于每个IP更准确地对应一个实际的浏览者。
4、三者直接的关系
IP和PV之间的关系:
PV是和IP的数量是成正比的,因为页面被刷新一次那么PV就会被记录一次,所以IP越多,说明网站的PV数据也就随之增多。但是需要注意的是PV并不是网站的页面的访问者数量,而是网站被访问的页面数量。因为一个访问者可以多次刷新页面,增加PV数量。
IP和UV之间的关系:
在记录网站流量统计数据时,站长们有时候发现这样一种情况:有时候网站的IP数据大于UV数据,有时候UV的数据也会大于IP数据。
为什么会出现这种现象呢?我们可以用一个例子来说明。比如,用同一个IP去访问我们的SEO网站,但是一个是用的台式的电脑,一个是用的笔记本,那么网站流量统计工具显示的数据就会是2个UV,1个IP。
这时UV的数据就会大于IP的数据。但是,再比如,只是用一个台式电脑访问我们的SEO网站,但是一会拨一个号换一个IP,那么这时候网站流量统计工具显示的数据的UV就为1,但是IP的数据就会高于UV的数据。因此,IP和UV之间的数据并不一定存在比例关系,两者之间的数据也不是此消彼长的关系。SEO童鞋们千万不要弄混淆了。
IP和PV之间的关系:
那么IP和PV的关系如何呢?如果一个IP刷新了网站1000次,网站的PV就为1000,所以从这点看二者之间没有多大关系。但是,我们可以通过IP和PV之间的数据差异,来更加深入的理解网站的流量数据。如果IP和PV的数据悬殊很大,比如,我们在查看网站流量数据时发现网站的PV是1000,IP为100,那么说明这个站点平均一个IP访问了网站内容10次,说明网站内容还是比较受欢迎的,所以访客才愿意在网站中停留那么久的时间,并浏览了那么多的网站页面内容。
但是如果IP和PV的数据很接近,比如,网站的IP为100,PV为110,说明一个IP也就访问了网站内容大约1次,就说明网站内容的可读性太差,客户点击进去之后就离开了,没有有过多的停留。如果网站流量统计这样的数据过多的话,站长就需要对网站内容进行深入思考了,以便更好的提高网站的流量。
以上内容总结:
①UV大于IP :
这种情况就是在网吧、学校、公司等,公用相同IP的场所中不同的用户,或者多种不同浏览器访问您网站,那么UV数会大于IP数。
②UV小于IP :
收起阅读 »
在家庭中大多数电脑使用ADSL拨号上网,所以同一个用户在家里不同时间访问您网站时,IP可能会不同,因为它会根据时间变动IP,即动态的IP地址,但是实际访客数唯一,便会出现UV数小于IP数。
Web服务器Tengine内核参数优化
内核参数的优化,主要是在Linux系统中针对Tengine应用而进行的系统内核参数优化,以下是我的优化例子:
net.ipv4.tcp_max_tw_buckets = 6000参数选项的含义介绍:
net.ipv4.ip_local_port_range = 1024 65000
net.ipv4.tcp_tw_recycle = 1
net.ipv4.tcp_tw_reuse =1
net.ipv4.tcp_syncookies = 1
net.core.somaxconn = 262144
net.core.netdev_max_backlog = 262144
net.ipv4.tcp_max_orphans = 262144
net.ipv4.tcp_max_syn_backlog = 262144
net.ipv4.tcp_synack_retries = 1
net.ipv4.tcp_syn_retries = 1
net.ipv4.tcp_fin_timeout = 1
net.ipv4.tcp_keepalive_time = 30
net.ipv4.tcp_max_tw_buckets 选项用来设定timewait的数量,默认是180 000,这里设置为6000收起阅读 »
net.ipv4.ip_local_port_range 选项用来设定允许系统打开的端口范围
net.ipv4.tcp_tw_recycle 选项用于设置启用timewait的快速回收
net.ipv4.tcp_tw_reuse 选项用于设置开启重用,允许将TIME-WAIT sockets重新用于新的TCP连接
net.ipv4.tcp_syncookies 选项用于设置开启SYN Cookies,当出现SYN等待队列溢出时,启用cookies进行处理
net.core.somaxconn 选项的默认值是128,这个参数用于调节系统同时发起的tcp连接数,在高并发的请求中,默认的值可能会导致链接超时或者重传,因此,需要结合并发请求数来调节此值
net.core.netdev_max_backlog 选项表示当每个网络接口数据包的速率比内核处理这些包的速率快时,允许发送到队列的数据包的最大数目
net.ipv4.tcp_max_orphans 选项用于设定系统中最多有多少个TCP套接字不被关联到任何一个用户文件句柄上。如果超过这个数字,孤立连接将立即被复位炳打印出警告信息。这个限制只是为了防止简单的DOS攻击。不能过分依靠这个限制甚至人为减小这个值,更多的情况下应该增加这个值
net.ipv4.tcp_max_syn_backlog 选项用于记录那些尚未收到客户端确认信息的连接请求的最大值。对于有128MB内存的系统而言,此参数的默认值是1024,对小内存的系统则是128
net.ipv4.tcp_synack_retries 参数的值决定了内核放弃连接之前发送SYN+ACK包的数量
net.ipv4.tcp_syn_retries 选项表示在内核放弃建立连接之前发送SYN包的数量。如果发送端要求关闭套接字,net.ipv4.tcp_fin_timeout选项决定了套接字保持在FIN-WAIT-2状态的时间。接收端可以出错并永远不关闭连接,甚至以外宕机
net.ipv4.tcp_fin_timeout 的默认值是60秒。需要注意的是,即使一个负载很小的Web服务器,也会出现因为大量的死套接字而产生内存溢出的风险。FIN-WAIT-2的危险比FIN-WAIT-1要小,因为它最多只能消耗1.5KB的内存,但是其生存期长些
net.ipv4.tcp_keepalive_time 选项表示当keeplive启用的时候,TCP发送keepalive消息的频度。默认值是2(单位是小时)
高并发linux生产服务器内核参数优化
所谓内核优化,主要是在Linux系统中针对业务服务应用而进行的系统内核参数优化,优化并无特殊的标准,下面以常见生产环境linux的内核优化为例讲解,仅供大家参考,欢迎拍砖。
net.ipv4.tcp_fin_timeout = 2将上面的内核参数值加入/etc/sysctl.conf文件中,然后执行如下命令使之生效:sysctl -p
net.ipv4.tcp_tw_reuse = 1
net.ipv4.tcp_tw_recycle = 1
net.ipv4.tcp_syncookies = 1
net.ipv4.tcp_keepalive_time = 600
net.ipv4.ip_local_port_range = 400065000
net.ipv4.tcp_max_syn_backlog = 16384
net.ipv4.tcp_max_tw_buckets = 36000
net.ipv4.route.gc_timeout = 100
net.ipv4.tcp_syn_retries = 1
net.ipv4.tcp_synack_retries = 1
net.core.somaxconn = 16384
net.core.netdev_max_backlog = 16384
net.ipv4.tcp_max_orphans = 16384
#以下参数是对iptables防火墙的优化,防火墙不开会提示,可以忽略不理。
net.ipv4.ip_conntrack_max = 25000000
net.ipv4.netfilter.ip_conntrack_max=25000000
net.ipv4.netfilter.ip_conntrack_tcp_timeout_established=180
net.ipv4.netfilter.ip_conntrack_tcp_timeout_time_wait=120
net.ipv4.netfilter.ip_conntrack_tcp_timeout_close_wait=60
net.ipv4.netfilter.ip_conntrack_tcp_timeout_fin_wait=120
参数解释参考:http://yangrong.blog.51cto.com/6945369/1321594 收起阅读 »
闰秒:让互联网公司倍感厌烦的一秒
这多出的“1秒”将加在6月30日午夜。由于北京处于东八时区,所以将在7月1日7:59:59后面增加1秒,届时会出现7:59:60的特殊现象。据悉,这是自1972年启用闰秒以来的第26次增加闰秒。离我们最近的一次闰秒,出现在2012年。


受到闰秒影响的网站之一是社交新闻网站Reddit。Reddit通过Twitter发表声明称,闰秒造成利用Java开发的开放源代码数据库Apache Cassandra出现故障,“太平洋标准时间下午5时,我们遭遇与闰秒相关的Java/Cassandra故障,我们在尽力恢复服务”。
Mozilla基金会称,闰秒是利用Java开发的开放源代码Hadoop遭遇故障的罪魁祸首。网站可靠性工程师埃里克·齐根霍恩(Eric Ziegenhorn)在一份报告中称,Java出现故障和闰秒是相关的,因为它们是同步发生的,“运行Hadoop、ElasticSearch等Java应用的服务器不能正常运行。我们认为这与闰秒有关,因为两者是同时发生的”。
我们服务器有台跑着java程序的服务器cpu表现如下: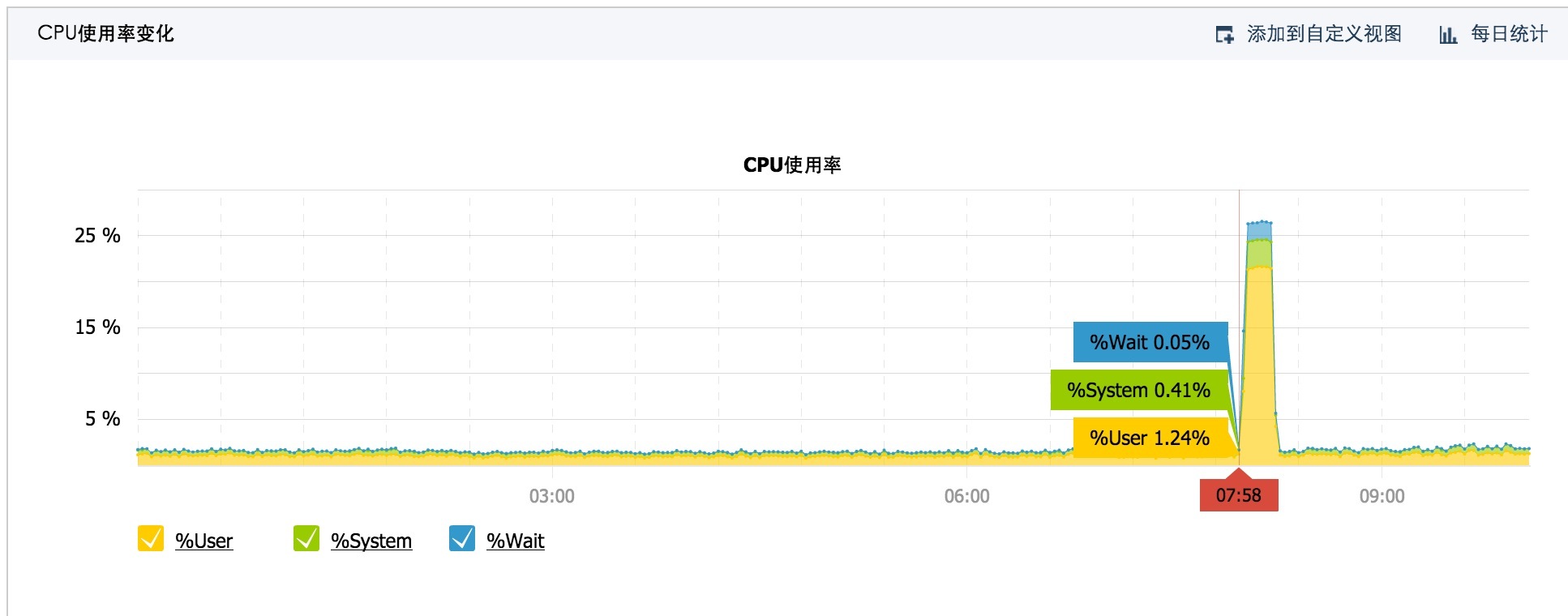
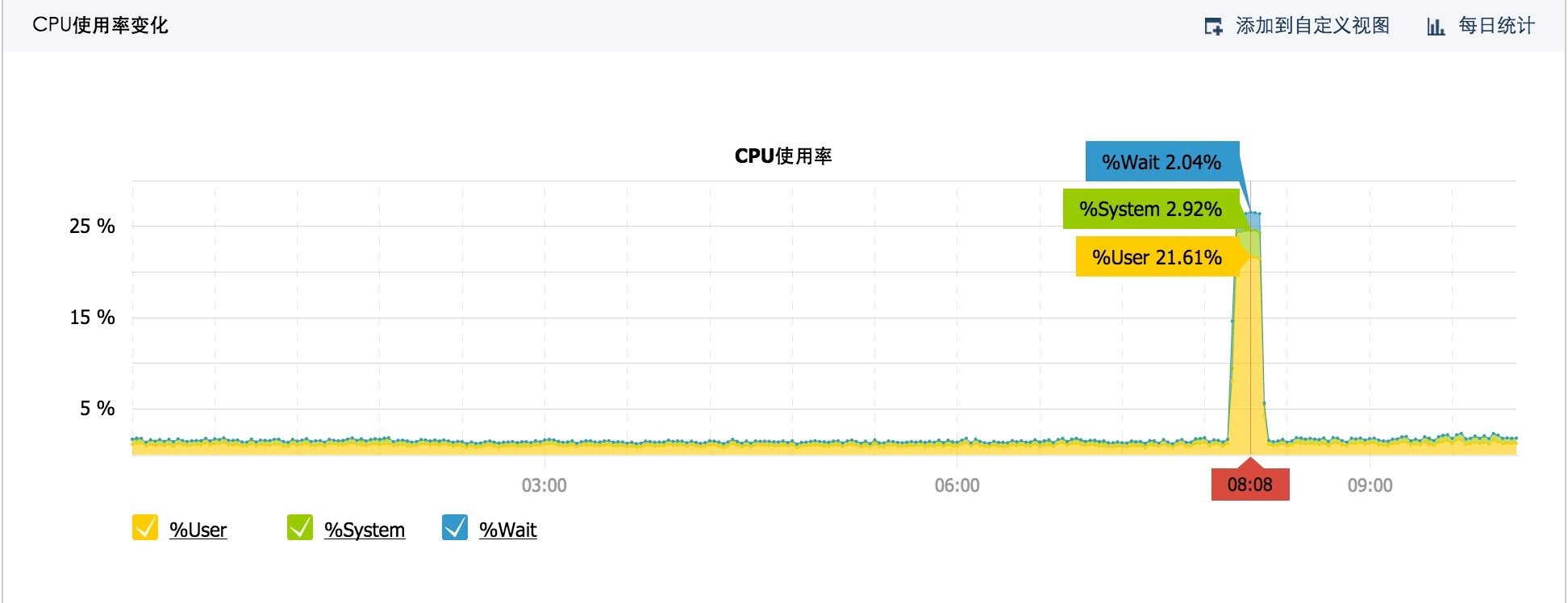
不过还好,对我们服务没有太大影响,小伙伴们,你们遭受到了痛苦吗????
部署使用varnish
节点:192.168.83.46 部署了LAMP+nagios监控系统开发80端口
节点:192.168.83.47 部署varnish做46的缓存
部署varnish
1. 设置好依赖目录
[root:~ Slave] # useradd -s /sbin/nologin varnish
[root:~ Slave] # mkdir /data/varnish/cache
[root:~ Slave] # mkdir /data/varnish/cache
[root:~ Slave] # mkdir /data/varnish/log
[root:~ Slave] # chown -R varnish:varnish /data/varnish/cache
[root:~ Slave] # chown -R varnish:varnish /data/varnish/log
Varnish的官方网址为: http://varnish-cache.org, 可以在这里下载最新版本的软件。在安装Varnish前需要安装PCRE库。如果没有安装该库,在Varnish2以上版本编译时,就会提示找不到PCRE库PCRE库则可以兼容正则表达式,所以必须先安装。下面介绍其安装过程。
2. pcre编译安装
[root:/opt/varnish Slave] # tar -zxvf pcre-8.00.tar.gz
[root:/opt/varnish Slave] # cd pcre-8.00
[root:/opt/varnish/pcre-8.00 Slave] # ./configure --prefix=/usr/local/pcre/
[root:/opt/varnish/pcre-8.00 Slave] # make && make install
3. varnish编译安装
[root:/opt/varnish Slave] # tar -zxvf varnish-2.0.6.tar.gz
[root:/opt/varnish Slave] # export PKG_CONFIG_PATH=/app/soft/varnish/lib/pkgconfig/ 这一行一定要有,不然在编译的时候会报错。这行用于指定Varnish 查找PCRE库的路径,如果PCRE安装到其他路径下,在这里指定即可,Varnish默认查找PCRE库的路径为usr/local/lib/pkgconfig。
[root:/opt/varnish/varnish-2.0.6 Slave] # ./configure -prefix=/app/soft/varnish -enable-debugging-symbols -enable-developer-warnings -enable-dependency-tracking
[root:/opt/varnish/varnish-2.0.6 Slave] # make
[root:/opt/varnish/varnish-2.0.6 Slave] # make install
[root:/opt/varnish/varnish-2.0.6 Slave] # cp redhat/varnish.initrc /etc/init.d/varnish
[root:/opt/varnish/varnish-2.0.6 Slave] # cp redhat/varnish.sysconfig /etc/sysconfig/varnish
4. 修改配置
进入varnish配置文件进行配置修改
[ root:/app/soft/varnish/etc/varnish Slave] # cd /app/soft/varnish/etc/varnish
[root:/app/soft/varnish/etc/varnish Slave] # vim default.vcl

启动和查看状态
[ root:/opt/varnish/varnish-2.0.6 Slave] # /app/soft/varnish/sbin/varnishd -f /app/soft/varnish/etc/varnish/default.vcl -s malloc,2G -T 127.0.0.1:2000 -a 0.0.0.0:8080
[root:/opt/varnish/varnish-2.0.6 Slave] # ps -ef |grep varnishd
Varnish启动运行信息 :
[root:/app/soft/varnish/bin Slave] # cd /app/soft/varnish/bin
[root:/app/soft/varnish/bin Slave] # /app/soft/varnish/bin/varnishlog
[root:/app/soft/varnish/bin Slave] # /app/soft/varnish/bin/varnishstat
杀掉varnish:
[root:/app/soft/varnish/bin Slave] # killall varnishd
隐藏nginx/tengine、apache、php版本号
一、隐藏nginx or tengine版本号
Nginx和tengine默认情况下是显示版本号的,如下所示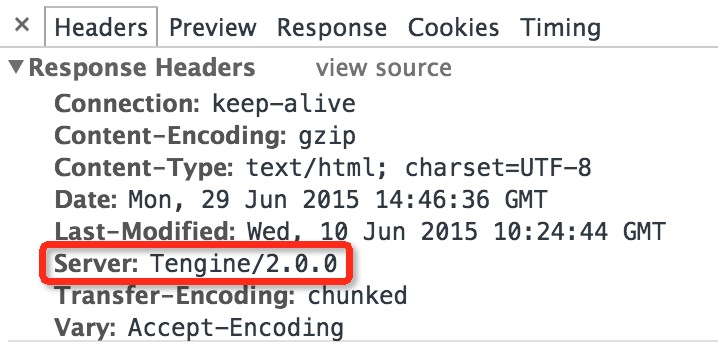
如上图所示可以看出服务器是tegine 2.0.0版本,有时候会暴露哪个Tengine或Nginx版本的漏洞,就是说有些版本有漏洞,而有些版本没有。这样暴露出来的版本号就容易变成攻击者可利用的信息。所以,从安全的角度来说,隐藏版本号会安全很多。
下面我们就来看看怎么设置,可以隐藏Tengine/Ngine的版本号:
1.进入到你Tengine/Nginx的安装目录,然后编辑主配置文件
# vim nginx.conf
在http {......}里加上server_tokens off;如:
http {
.....省略
sendfile on;
tcp_nopush on;
gzip on;
proxy_redirect off;
server_tokens off;
.....省略
}
2.如果后端接了php-fpm,则编辑配置文件fastcgi.conf或fcgi.conf (这个配置文件名也可以自定义的,根据具体文件名修改):
找到:
fastcgi_param SERVER_SOFTWARE nginx/$nginx_version;
改为:
fastcgi_param SERVER_SOFTWARE nginx;
3.重新加载tengine/nginx配置:
./sbin/nginx -s reload
这样就完全对外隐藏了nginx版本号了,就是出现404、501等页面也不会显示nginx版本。
最后验证结果:
如果想把Tengine也隐藏点,需要编辑Tengine源码中的src/core/nginx.h头文件
也可修改成你想要的显示信息,然后重新编译安装。
二、隐藏Apache版本号
一般情况下,软件的漏洞信息和特定版本是相关的,因此,软件的版本号对攻击者来说是很有价值的。
在默认情况下,系统会把Apache版本模块都显示出来(http返回头信息)。如果列举目录的话,会显示域名信息(文件列表正文),如: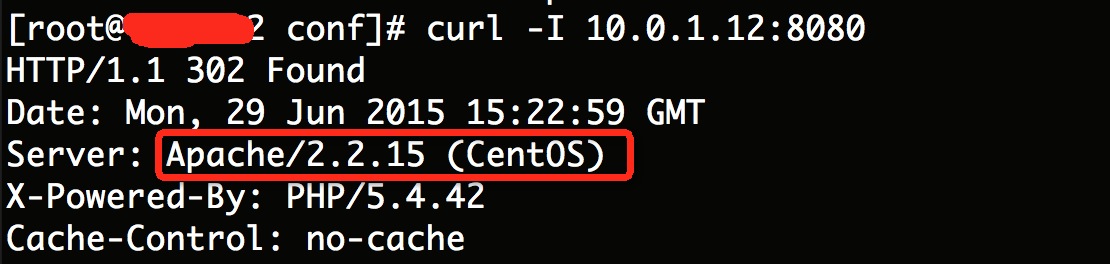
隐藏方法:
1、隐藏Apache版本号的方法是修改Apache的配置文件,如Centos系统Linux默认是:
# vim /etc/httpd/conf/httpd.conf
分别搜索关键字ServerTokens和ServerSignature,修改:
ServerTokens OS 修改为 ServerTokens ProductOnly
ServerSignature On 修改为 ServerSignature Off
2、重启或重新加载Apache就可以了
# /etc/init.d/httpd restart
验证:
版本号与操作系统信息已经隐藏了
3、上面的方法是默认情况下安装的Apache,如果是编译安装的,还可以用修改源码编译的方法:
进入Apache的源码目录下的include目录,然后编辑ap_release.h这个文件,你会看到有如下变量:
#define AP_SERVER_BASEVENDOR “Apache Software Foundation”
#define AP_SERVER_BASEPROJECT “Apache HTTP Server”
#define AP_SERVER_BASEPRODUCT “Apache”
#define AP_SERVER_MAJORVERSION_NUMBER 2
#define AP_SERVER_MINORVERSION_NUMBER 2
#define AP_SERVER_PATCHLEVEL_NUMBER 15
#define AP_SERVER_DEVBUILD_BOOLEAN 0
可以根据自己喜好,修改或隐藏版本号与名字
三、隐藏php版本号
为了安全起见,最好还是将PHP版本隐藏,以避免一些因PHP版本漏洞而引起的攻击。
1、隐藏PHP版本就是隐藏 “X-Powered-By: PHP/5.4.42″ 这个信息:
编辑php.ini配置文件,修改或加入: expose_php = Off 保存后重新启动Nginx或Apache等相应的Web服务器即可。
验证: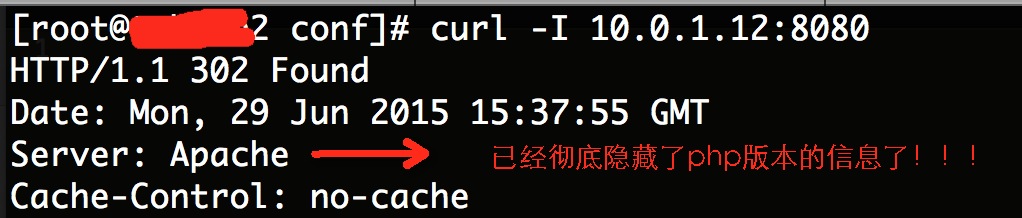
2、其它几个PHP的基本安全设置:
disable_functions = phpinfo,system,exec,shell_exec,passthru,popen,dl,proc_open,popen,curl_exec,curl_multi_exec,parse_ini_file,show_source
#该指令接受一个用逗号分隔的函数名列表,以禁用特定的函数。
display_errors = Off
# 是否将错误信息作为输出的一部分显示。在最终发布的web站点上,强烈建议你关掉这个特性,并使用错误日志代替。打开这个特性可能暴露一些安全信息,例如你的web服务上的文件路径、数据库规划或别的信息。
allow_url_fopen = Off
# 是否允许打开远程文件,建议关闭,如果网站需要采集功能就打开。
safe_mode = On
# 是否启用安全模式。打开时,PHP将检查当前脚本的拥有者是否和被操作的文件的拥有者相同,相同则允许操作,不同则拒绝操作。开启安全模式的前提是你的目录文件权限已完全分配正确。
open_basedir = /var/www/html/devopsh:/var/www/html/zhouuupc
# 目录权限控制,devopsh目录中的php程序就无法访问zhouuupc目录中的内容。反过来也不行。在Linux/UNIX系统中用冒号分隔目录,Windows中用分号分隔目录。
ansible安装过程中常遇到的错误
Traceback (most recent call last):解决方法:
File "/usr/bin/ansible", line 197, in
(runner, results) = cli.run(options, args)
File "/usr/bin/ansible", line 163, in run
extra_vars=extra_vars,
File "/usr/lib/python2.6/site-packages/ansible/runner/__init__.py", line 233, in __init__
cmd = subprocess.Popen(['ssh','-o','ControlPersist'], stdout=subprocess.PIPE, stderr=subprocess.PIPE)
File "/usr/lib64/python2.6/subprocess.py", line 639, in __init__
errread, errwrite)
File "/usr/lib64/python2.6/subprocess.py", line 1228, in _execute_child
raise child_exception
OSError: [Errno 2] No such file or directory
# yum install openssh-clients2.出现Error: ansible requires a json module, none found!
SSH password:解决方法:
10.0.1.110 | FAILED >> {
"failed": true,
"msg": "Error: ansible requires a json module, nonefound!",
"parsed": false
}
python版本过低,要不升级python要不就升级安装python-simplejson。3.安装完成后连接客户端服务器报错
FAILED => Using a SSH password insteadof a key is not possible because Host Key checking is enabled and sshpass doesnot support this. Please add this host'sfingerprint to your known_hosts file to manage this host.解决方法:
在ansible 服务器上使用ssh 登陆下/etc/ansible/hosts 里面配置的服务器。然后再次使用ansible 去管理就不会报上面的错误了!但这样大批量登陆就麻烦来。因为默认ansible是使用key验证的,如果使用密码登陆的服务器,使用ansible的话,要不修改ansible.cfg配置文件的ask_pass = True给取消注释,要不就在运行命令时候加上-k,这个意思是-k, --ask-pass ask for SSH password。再修改:host_key_checking= False即可4.如果客户端不在know_hosts里将会报错
paramiko: The authenticity of host '192.168.24.15'can't be established.
The ssh-rsa key fingerprint is397c139fd4b0d763fcffaee346a4bf6b.
Are you sure you want to continueconnecting (yes/no)?
解决方法:
需要修改ansible.cfg的#host_key_checking= False取消注释5.出现FAILED => FAILED: not a valid DSA private key file
解决方法:
需要你在最后添加参数-k6.openssh升级后无法登录报错
PAM unable todlopen(/lib64/security/pam_stack.so): /lib64/security/pam_stack.so: cannot openshared object解决方法:
file: No such file or directory
sshrpm 升级后会修改/etc/pam.d/sshd 文件。需要升级前备份此文件最后还原即可登录。7.第一次系统初始化运行生成本机ansible用户key时报错
failed: [127.0.0.1] =>{"checksum": "f5f2f20fc0774be961fffb951a50023e31abe920","failed": true}解决方法:
msg: Aborting, target uses selinux but pythonbindings (libselinux-python) aren't installed!
FATAL: all hosts have already failed –aborting
# yum install libselinux-python -y收起阅读 »
mysql索引详解
什么是索引
索引用来快速地寻找那些具有特定值的记录,所有MySQL索引都以B-树的形式保存。如果没有索引,执行查询时MySQL必须从第一个记录开始扫描整个表的所有记录,直至找到符合要求的记录。表里面的记录数量越多,这个操作的代价就越高。
如果作为搜索条件的列上已经创建了索引,MySQL无需扫描任何记录即可迅速得到目标记录所在的位置。如果表有1000个记录,通过索引查找记录至少要比顺序扫描记录快100倍。
假设我们创建了一个名为people的表:
CREATE TABLE people ( peopleid SMALLINT NOT NULL, name CHAR(50) NOT NULL );
然后,我们完全随机把1000个不同name值插入到people表。下图显示了people表所在数据文件的一小部分:
可以看到,在数据文件中name列没有任何明确的次序。如果我们创建了name列的索引,MySQL将在索引中排序name列:
对于索引中的每一项,MySQL在内部为它保存一个数据文件中实际记录所在位置的“指针”。因此,如果我们要查找name等于“Mike”记录的peopleid(SQL命令为SELECT peopleid FROM people WHERE name='Mike';),MySQL能够在name的索引中查找“Mike”值,然后直接转到数据文件中相应的行,准确地返回该行的peopleid(999)。
在这个过程中,MySQL只需处理一个行就可以返回结果。如果没有“name”列的索引,MySQL要扫描数据文件中的所有记录,即1000个记录!显然,需要MySQL处理的记录数量越少,则它完成任务的速度就越快。
索引的类型
MySQL提供多种索引类型供选择,下面详解每种索引。
普通索引
这是最基本的索引类型,而且它没有唯一性之类的限制。普通索引可以通过以下几种方式创建:
- 创建索引,例如CREATE INDEX <索引的名字> ON tablename (列的列表);
- 修改表,例如ALTER TABLE tablename ADD INDEX [索引的名字] (列的列表);
- 创建表的时候指定索引,例如CREATE TABLE tablename ( […], INDEX [索引的名字] (列的列表) );
唯一性索引
这种索引和前面的“普通索引”基本相同,但有一个区别:索引列的所有值都只能出现一次,即必须唯一。唯一性索引可以用以下几种方式创建:
- 创建索引,例如CREATE UNIQUE INDEX <索引的名字> ON tablename (列的列表);
- 修改表,例如ALTER TABLE tablename ADD UNIQUE [索引的名字] (列的列表);
- 创建表的时候指定索引,例如CREATE TABLE tablename ( […], UNIQUE [索引的名字] (列的列表) );
主键
主键是一种唯一性索引,但它必须指定为PRIMARY KEY。如果你曾经用过AUTO_INCREMENT类型的列,你可能已经熟悉主键之类的概念了。
主键一般在创建表的时候指定,例如CREATE TABLE tablename ( [...], PRIMARY KEY (列的列表) );。但是,我们也可以通过修改表的方式加入主键,例如ALTER TABLE tablename ADD PRIMARY KEY (列的列表);。每个表只能有一个主键。
全文索引
MySQL从3.23.23版开始支持全文索引和全文检索。在MySQL中,全文索引的索引类型为FULLTEXT。全文索引可以在VARCHAR或者TEXT类型的列上创建。它可以通过CREATE TABLE命令创建,也可以通过ALTER TABLE或CREATE INDEX命令创建。对于大规模的数据集,通过ALTER TABLE(或者CREATE INDEX)命令创建全文索引要比把记录插入带有全文索引的空表更快。本文下面的讨论不再涉及全文索引,要了解更多信息,请参见MySQL documentation 。
单列索引与多列索引
索引可以是单列索引,也可以是多列索引。下面我们通过具体的例子来说明这两种索引的区别。假设有这样一个people表:
CREATE TABLE people (
peopleid SMALLINT NOT NULL AUTO_INCREMENT,
firstname CHAR(50) NOT NULL,
lastname CHAR(50) NOT NULL,
age SMALLINT NOT NULL,
townid SMALLINT NOT NULL,
PRIMARY KEY (peopleid) );
下面是我们插入到这个people表的数据:
这个数据片段中有四个名字为Mikes的人(其中两个姓Sullivans,两个姓McConnells),有两个年龄为17岁的人,还有一个名字与众不同的Joe Smith。
这个表的主要用途是根据指定的用户姓、名以及年龄返回相应的peopleid。例如,我们可能需要查找姓名为Mike Sullivan、年龄17岁用户的peopleid(SQL命令为SELECT peopleid FROM people WHERE firstname='Mike' AND lastname='Sullivan' AND age=17;)。由于我们不想让MySQL每次执行查询就去扫描整个表,这里需要考虑运用索引。
首先,我们可以考虑在单个列上创建索引,比如firstname、lastname或者age列。如果我们创建firstname列的索引(ALTER TABLE people ADD INDEX firstname (firstname);),MySQL将通过这个索引迅速把搜索范围限制到那些firstname='Mike'的记录,然后再在这个中间结果集上进行其他条件的搜索:它首先排除那些lastname不等于Sullivan的记录,然后排除那些age不等于17的记录。当记录满足所有搜索条件之后,MySQL就返回最终的搜索结果。
由于建立了firstname列的索引,与执行表的完全扫描相比,MySQL的效率提高了很多,但我们要求MySQL扫描的记录数量仍旧远远超过了实际所需要的。虽然我们可以删除firstname列上的索引,再创建lastname或者age列的索引,但总地看来,不论在哪个列上创建索引搜索效率仍旧相似。
为了提高搜索效率,我们需要考虑运用多列索引。如果为firstname、lastname和age这三个列创建一个多列索引,MySQL只需一次检索就能够找出正确的结果!下面是创建这个多列索引的SQL命令:
ALTER TABLE people ADD INDEX fname_lname_age (firstname,lastname,age);
由于索引文件以B-Tree格式保存,MySQL能够立即转到合适的firstname,然后再转到合适的lastname,最后转到合适的age。在没有扫描数据文件任何一个记录的情况下,MySQL就正确地找出了搜索的目标记录!
那么,如果在firstname、lastname、age这三个列上分别创建单列索引,效果是否和创建一个firstname、lastname、age的多列索引一样呢?答案是否定的,两者完全不同。当我们执行查询的时候,MySQL只能使用一个索引。如果你有三个单列的索引,MySQL会试图选择一个限制最严格的索引。但是,即使是限制最严格的单列索引,它的限制能力也肯定远远低于firstname、lastname、age这三个列上的多列索引。
最左前缀
多列索引还有另外一个优点,它通过称为最左前缀(Leftmost Prefixing)的概念体现出来。继续考虑前面的例子,现在我们有一个firstname、lastname、age列上的多列索引,我们称这个索引为fname_lname_age。当搜索条件是以下各种列的组合时,MySQL将使用fname_lname_age索引:
firstname,lastname,age
firstname,lastname
firstname
从另一方面理解,它相当于我们创建了(firstname,lastname,age)、(firstname,lastname)以及(firstname)这些列组合上的索引。下面这些查询都能够使用这个fname_lname_age索引:
SELECT peopleid FROM people WHERE firstname='Mike' AND lastname='Sullivan' AND age='17';
SELECT peopleid FROM people WHERE firstname='Mike' AND lastname='Sullivan';
SELECT peopleid FROM people WHERE firstname='Mike';
The following queries cannot use the index at all:
SELECT peopleid FROM people WHERE lastname='Sullivan';
SELECT peopleid FROM people WHERE age='17';
SELECT peopleid FROM people WHERE lastname='Sullivan' AND age='17';
选择索引列
在性能优化过程中,选择在哪些列上创建索引是最重要的步骤之一。可以考虑使用索引的主要有两种类型的列:在WHERE子句中出现的列,在join子句中出现的列。请看下面这个查询:
SELECT age # 不使用索引
FROM people WHERE firstname='Mike' # 考虑使用索引
AND lastname='Sullivan' # 考虑使用索引
这个查询与前面的查询略有不同,但仍属于简单查询。由于age是在SELECT部分被引用,MySQL不会用它来限制列选择操作。因此,对于这个查询来说,创建age列的索引没有什么必要。下面是一个更复杂的例子:
SELECT people.age, #不使用索引
town.name #不使用索引
FROM people LEFT JOIN town ON
people.townid=town.townid #考虑使用索引
WHERE firstname='Mike' #考虑使用索引
AND lastname='Sullivan' #考虑使用索引
与前面的例子一样,由于firstname和lastname出现在WHERE子句中,因此这两个列仍旧有创建索引的必要。除此之外,由于town表的townid列出现在join子句中,因此我们需要考虑创建该列的索引。
那么,我们是否可以简单地认为应该索引WHERE子句和join子句中出现的每一个列呢?差不多如此,但并不完全。我们还必须考虑到对列进行比较的操作符类型。MySQL只有对以下操作符才使用索引:<,<=,=,>,>=,BETWEEN,IN,以及某些时候的LIKE。可以在LIKE操作中使用索引的情形是指另一个操作数不是以通配符(%或者_)开头的情形。例如,SELECT peopleid FROM people WHERE firstname LIKE 'Mich%';这个查询将使用索引,但SELECT peopleid FROM people WHERE firstname LIKE '%ike';这个查询不会使用索引。
分析索引效率
现在我们已经知道了一些如何选择索引列的知识,但还无法判断哪一个最有效。MySQL提供了一个内建的SQL命令帮助我们完成这个任务,这就是EXPLAIN命令。EXPLAIN命令的一般语法是:EXPLAIN 。你可以在MySQL文档找到有关该命令的更多说明。下面是一个例子:
EXPLAIN SELECT peopleid FROM people WHERE firstname='Mike' AND lastname='Sullivan' AND age='17';
这个命令将返回下面这种分析结果:
下面我们就来看看这个EXPLAIN分析结果的含义:
table:这是表的名字。
type:连接操作的类型。下面是MySQL文档关于ref连接类型的说明:
对于每一种与另一个表中记录的组合,MySQL将从当前的表读取所有带有匹配索引值的记录。如果连接操作只使用键的最左前缀,或者如果键不是UNIQUE或PRIMARY KEY类型(换句话说,如果连接操作不能根据键值选择出唯一行),则MySQL使用ref连接类型。如果连接操作所用的键只匹配少量的记录,则ref是一种好的连接类型。
在本例中,由于索引不是UNIQUE类型,ref是我们能够得到的最好连接类型。
如果EXPLAIN显示连接类型是“ALL”,而且你并不想从表里面选择出大多数记录,那么MySQL的操作效率将非常低,因为它要扫描整个表。你可以加入更多的索引来解决这个问题。预知更多信息,请参见MySQL的手册说明。
possible_keys: 可能可以利用的索引的名字。这里的索引名字是创建索引时指定的索引昵称;如果索引没有昵称,则默认显示的是索引中第一个列的名字(在本例中,它是firstname)。默认索引名字的含义往往不是很明显。
Key: 它显示了MySQL实际使用的索引的名字。如果它为空(或NULL),则MySQL不使用索引。
key_len: 索引中被使用部分的长度,以字节计。在本例中,key_len是102,其中firstname占50字节,lastname占50字节,age占2字节。如果MySQL只使用索引中的firstname部分,则key_len将是50。
ref: 它显示的是列的名字(或单词const),MySQL将根据这些列来选择行。在本例中,MySQL根据三个常量选择行。
rows:MySQL所认为的它在找到正确的结果之前必须扫描的记录数。显然,这里最理想的数字就是1。
Extra: 这里可能出现许多不同的选项,其中大多数将对查询产生负面影响。在本例中,MySQL只是提醒我们它将用WHERE子句限制搜索结果集。
索引的缺点
到目前为止,我们讨论的都是索引的优点,事实上,索引也是有缺点的,如下:
首先,索引要占用磁盘空间。通常情况下,这个问题不是很突出。但是,如果你创建每一种可能列组合的索引,索引文件体积的增长速度将远远超过数据文件。如果你有一个很大的表,索引文件的大小可能达到操作系统允许的最大文件限制。
第二,对于需要写入数据的操作,比如DELETE、UPDATE以及INSERT操作,索引会降低它们的速度。这是因为MySQL不仅要把改动数据写入数据文件,而且它还要把这些改动写入索引文件。
总结
在大型数据库中,索引是提高速度的一个关键因素。不管表的结构是多么简单,一次500000行的表扫描操作无论如何不会快。如果你的网站上也有这种大规模的表,那么你确实应该花些时间去分析可以采用哪些索引,并考虑是否可以改写查询以优化应用。要了解更多信息,请参见MySQL manual。
收起阅读 »mysql创建和删除表
简单的方式:
CREATE TABLE person (或者是
number INT(11),
name VARCHAR(255),
birthday DATE
);
CREATE TABLE IF NOT EXISTS person (
number INT(11),
name VARCHAR(255),
birthday DATE
);
查看mysql创建表:
> SHOW CREATE table person;
CREATE TABLE `person` (
`number` int(11) DEFAULT NULL,
`name` varchar(255) DEFAULT NULL,
`birthday` date DEFAULT NULL
) ENGINE=MyISAM DEFAULT CHARSET=utf8;
查看表所有的列:
> SHOW FULL COLUMNS from person;
+----------+--------------+-----------------+------+-----+---------+-------+---------------------------------+---------+
| Field | Type | Collation | Null | Key | Default | Extra | Privileges | Comment |
+----------+--------------+-----------------+------+-----+---------+-------+---------------------------------+---------+
| number | int(11) | NULL | YES | | NULL | | select,insert,update,references | |
| name | varchar(255) | utf8_general_ci | YES | | NULL | | select,insert,update,references | |
| birthday | date | NULL | YES | | NULL | | select,insert,update,references | |
+----------+--------------+-----------------+------+-----+---------+-------+---------------------------------+---------+
创建临时表
CREATE TEMPORARY TABLE temp_person (
number INT(11),
name VARCHAR(255),
birthday DATE
);
在创建表格时,您可以使用TEMPORARY关键词。只有在当前连接情况下,TEMPORARY表才是可见的。当连接关闭时,TEMPORARY表被自动取消。这意味着两个不同的连接可以使用相同的临时表名称,同时两个临时表不会互相冲突,也不与原有的同名的非临时表冲突。(原有的表被隐藏,直到临时表被取消时为止。)您必须拥有CREATE TEMPORARY TABLES权限,才能创建临时表。
如果表已存在,则使用关键词IF NOT EXISTS可以防止发生错误。
CREATE TABLE IF NOT EXISTS person2 (
number INT(11),
name VARCHAR(255),
birthday DATE
);
注意,原有表的结构与CREATE TABLE语句中表示的表的结构是否相同,这一点没有验证。注释:如果您在CREATE TABLE...SELECT语句中使用IF NOT EXISTS,则不论表是否已存在,由SELECT部分选择的记录都会被插入
在CREATE TABLE语句的末尾添加一个SELECT语句,在一个表的基础上创建表
CREATE TABLE new_tbl SELECT [i] FROM orig_tbl;注意,用SELECT语句创建的列附在表的右侧,而不是覆盖在表上mysql> SELECT [/i] FROM foo;也可以明确地为一个已生成的列指定类型
+---+
| n |
+---+
| 1 |
+---+
mysql> CREATE TABLE bar (m INT) SELECT n FROM foo;
mysql> SELECT * FROM bar;
+------+---+
| m | n |
+------+---+
| NULL | 1 |
+------+---+
CREATE TABLE foo (a TINYINT NOT NULL) SELECT b+1 AS a FROM bar;根据其它表的定义(包括在原表中定义的所有的列属性和索引),使用LIKE创建一个空表:
CREATE TABLE new_tbl LIKE orig_tbl;创建一个有主键,唯一索引,普通索引的表:
CREATE TABLE `people` (其中peopleid是主键,以firstname和lastname两列建立了一个唯一索引,以firstname,lastname,age三列建立了一个普通索引
`peopleid` smallint(6) NOT NULL AUTO_INCREMENT,
`firstname` char(50) NOT NULL,
`lastname` char(50) NOT NULL,
`age` smallint(6) NOT NULL,
`townid` smallint(6) NOT NULL,
PRIMARY KEY (`peopleid`),
UNIQUE KEY `unique_fname_lname`(`firstname`,`lastname`),
KEY `fname_lname_age` (`firstname`,`lastname`,`age`)
) ;
删除表
DROP TABLE tbl_name;
或者是
DROP TABLE IF EXISTS tbl_name;
清空表数据收起阅读 »
TRUNCATE TABLE table_name





