
通知设置 新通知
MySQL的三种复制模式
数据库 koyo 发表了文章 0 个评论 4430 次浏览 2021-12-10 00:04

MySQL支持的三种复制模式分别为:
- asynchronous 异步复制
- fully synchronous 全同步复制
- semi synchronous 半同步复制
异步复制 (asynchronous replication)
原理:在异步复制中,master写数据到binlog且sync,slave request binlog后写入relay-log并flush disk
优点:复制的性能最好
缺点: master挂掉后,slave可能会丢失事务
代表:MySQL原生的复制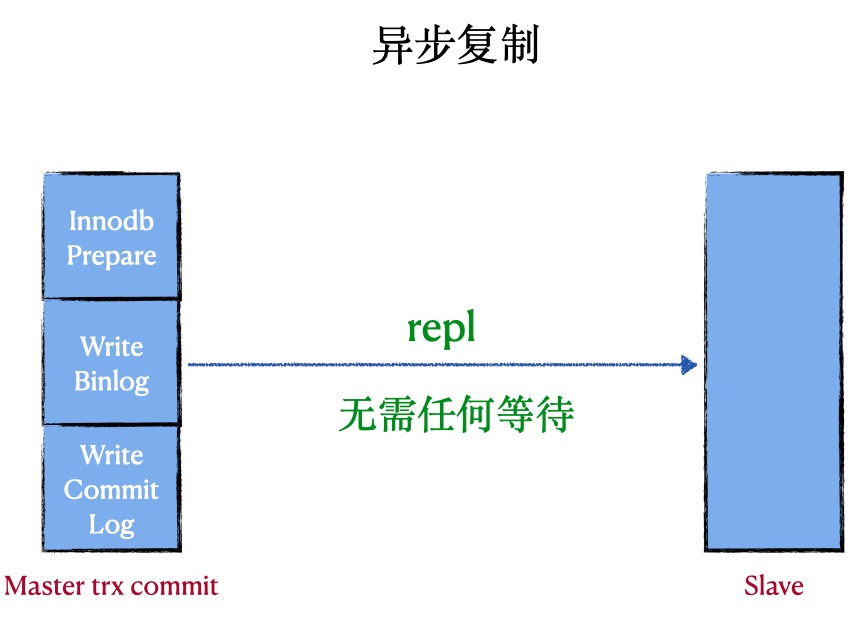
全同步复制 (fully synchronous replication)
原理:在全同步复制中,master写数据到binlog且sync,所有slave request binlog后写入relay-log并flush disk,并且回放完日志且commit
优点:数据不会丢失
缺点:会阻塞master session,性能太差,非常依赖网络
代表:MySQL Cluster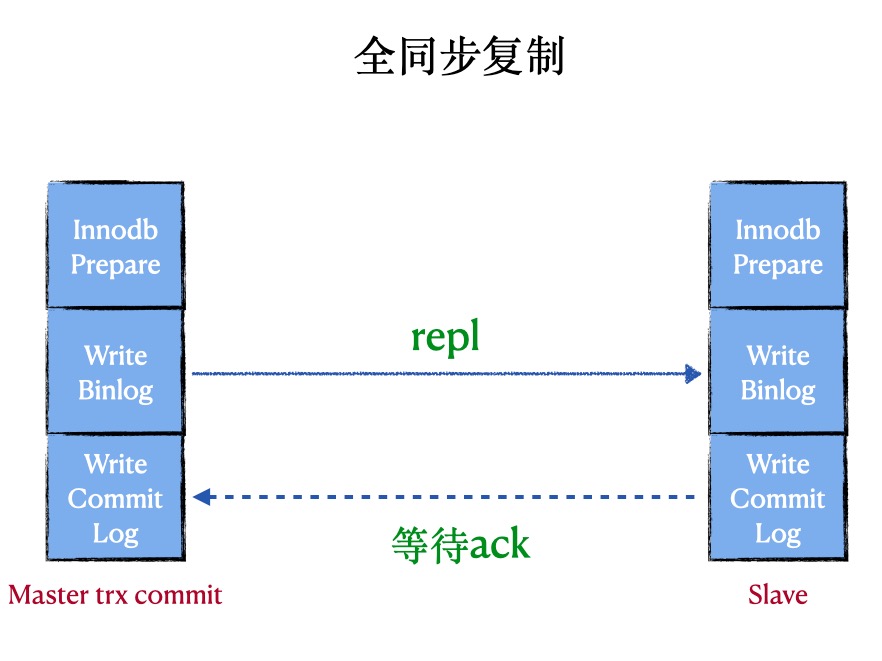
半同步复制 (semi synchronous replication)
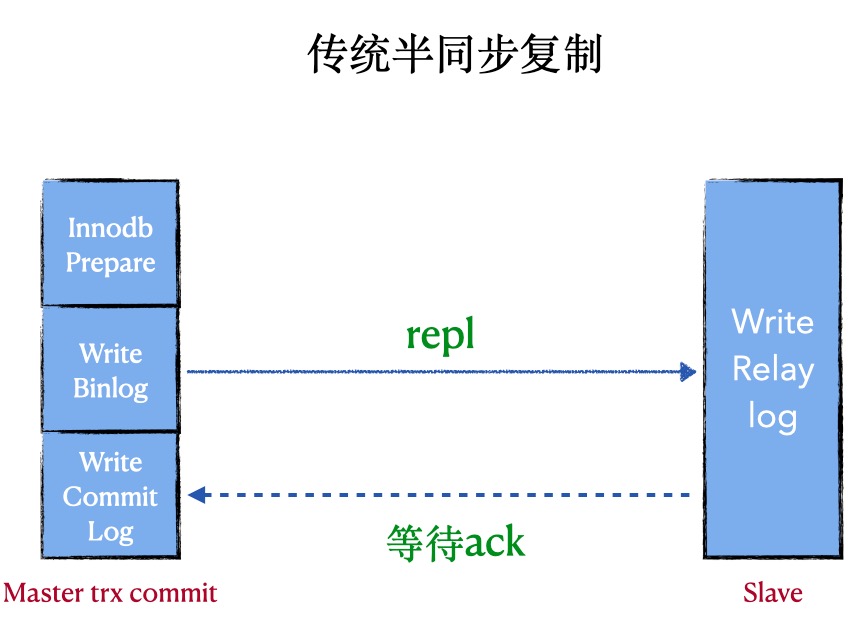
1. 普通的半同步复制
原理: 在半同步复制中,master写数据到binlog且sync,且commit,然后一直等待ACK。当至少一个slave request bilog后写入到relay-log并flush disk,就返回ack(不需要回放完日志)
优点:会有数据丢失风险(低)
缺点:会阻塞master session,性能差,非常依赖网络,
代表:after commit, 原生的半同步
重点:由于master是在三段提交的最后commit阶段完成后才等待,所以master的其他session是可以看到这个提交事务的,所以这时候master上的数据和slave不一致,master crash后,slave数据丢失
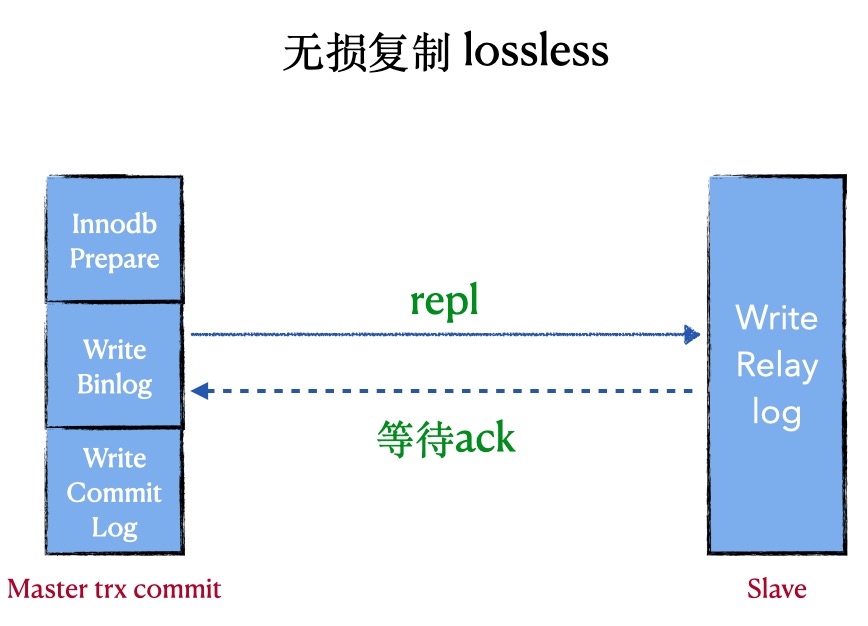
2. 增强版的半同步复制(lossless replication)
原理: 在半同步复制中,master写数据到binlog且sync,然后一直等待ACK. 当至少一个slave request bilog后写入到relay-log并flush disk,就返回ack(不需要回放完日志)
优点:数据零丢失(前提是让其一直是lossless replication),性能好
缺点:会阻塞master session,非常依赖网络
代表:after sync, 原生的半同步
重点:由于master是在三段提交的第二阶段sync binlog完成后才等待, 所以master的其他session是看不见这个提交事务的,所以这时候master上的数据和slave一致,master crash后,slave没有丢失数据
重要参数:
| 参数 | 评论 | 默认值 | 推荐值 | 是否动态 |
|---|---|---|---|---|
| rpl_semi_sync_master_wait_for_slave_count | 至少有N个slave接收到日志 | 1 | 1 | dynamic |
| rpl_semi_sync_master_wait_point | 等待的point | AFTER_SYNC | AFTER_SYNC | dynamic |
| rpl_semi_sync_master_timeout | 切换复制的timeout | 1000(10s) | 1000 (1s) | dynamic |
| rpl_semi_sync_master_enabled | 是否开启半同步 | OFF | ON | dynamic |
| rpl_semi_sync_slave_enabled | 是否开启半同步 | OFF | ON | dynamic |
如何开启lossless replication:
########semi sync replication settings########
plugin_dir=/usr/local/mysql/lib/plugin
plugin_load = "rpl_semi_sync_master=semisync_master.so;rpl_semi_sync_slave=semisync_slave.so"
loose_rpl_semi_sync_master_enabled = 1
loose_rpl_semi_sync_slave_enabled = 1
loose_rpl_semi_sync_master_timeout = 1000
实践是检验真理的唯一标准
如何检验上述after_sync 和 after_commit, 如何检验上述原理的正确性。
InnoDB commit: 三阶段提交过程
A阶段: wite prepare log 写入Xid
B阶段: write binlog
C阶段: write commit log
测试点:master上当一个事务Waiting for semi-sync ACK from slave的时候,后来的事务是在A,B,C哪个阶段卡住呢?
0,RC模式
1. semi-sync C阶段等待
假设设置time-out=100000s,当事务一提交了一个大事务,在write commit log(C阶段)时候等待,
那么第二个事务在敲commit命令的时候,是卡在哪个阶段呢?是卡在 wite prepare log(A阶段)?还是write binlog(B阶段)?还是write commit log(C阶段)
测试:semi-sync vs loss-less semi-sync
【semi-sync】 C阶段等待
0, 开启事务1,然后在slave上执行stop slave,制造timeout的情况,让其阻塞。(Waiting for semi-sync ACK from slave)
1,在开启一个事务2,事务2插入一条特殊记录(XXXXX)。 (Waiting for semi-sync ACK from slave)
2,在开启一个事务3。
2.1,测试案例:这个时候,kill -9 mysqld,造成人为的mysql crash
3,假设卡在A阶段,那么事务3,肯定是看不到事务1,2写入的记录(XXXXX),且重启mysql后,事务2不会提交。
4,假设卡在C阶段,那么事务3,肯定是可以看见事务1,2写入的记录(XXXXX)。
经过测试:
1,是卡在C阶段,也就是说事务3是可以看见事务1,事务2的。
2,MySQL crash重启后,事务1,事务2的dml都已经提交成功,说明不是卡在A阶段
【loss-less semi-sync】B阶段等待
0, 开启事务1,然后在slave上执行stop slave,制造timeout的情况,让其阻塞。(Waiting for semi-sync ACK from slave)
1,在开启一个事务2,事务2插入一条特殊记录(XXXXX)。(Waiting for semi-sync ACK from slave)
2,在开启一个事务3
3,假设卡在A阶段,那么事务3,肯定是看不到事务1,2写入的记录(XXXXX),且重启mysql后,事务2不会提交。。
4,假设卡在B阶段,那么事务3,肯定是可以看见事务1,2写入的记录(XXXXX),且重启mysql后,事务1,2都会提交。。
5, 假设卡在C阶段,那么事务3,肯定是可以看见事务3写入的记录(XXXXX)。
经过测试:
1,是卡在B阶段,也就是说事务3,既看不见事务1的提交内容,也看不见事务2的提交内容,且重启mysql后,事务1,2都已经提交。。
2,MySQL crash重启后,事务1,事务2的dml都已经提交成功,说明不是卡在A阶段。
性能
semi-sync vs lossless semi-sync 的性能对比
根据以上的测试,可以得知,lossless只卡在B阶段,普通的semi-sync是卡在C阶段。
lossless的性能远远好于普通的semi-sync,即(after_sync 优于 after_commit)
因为lossless 卡在B阶段的时候可以堆积事务,可以在C阶段进行group commit。
普通的semi-sync,卡在C阶段,事务都已经commit了,并没有堆积的过程。
CAP理论:
一致性【C】
可用性【A】
分区容忍性【P】
理论:CAP 三者不可兼得,必须要牺牲一个
分区,是一定存在的,不是你想不要就不要的。所以,这里只剩下两种组合
CP 牺牲可用性
这种做法,就是保留强一致性,牺牲可用性
案例:可以将rpl_semi_sync_master_timeout设置成一个无限大的值,比如:100天,那么master和slave就强一致了,但是可用性就大打折扣
AP 牺牲一致性
这种做法,就是保留高可用性,牺牲一致性
案例:比如原生的异步复制就是这样咯。可以快速做到切换,但是一致性就没有保障
Kubernetes中的容器编排和应用编排
云原生 OS小编 发表了文章 0 个评论 2286 次浏览 2021-11-27 17:06

众所周知,Kubernetes 是一个容器编排平台,它有非常丰富的原始的 API 来支持容器编排,但是对于用户来说更加关心的是一个应用的编排,包含多容器和服务的组合,管理它们之间的依赖关系,以及如何管理存储。
在这个领域,Kubernetes 用 Helm 的来管理和打包应用,但是 Helm 并不是十全十美的,在使用过程中我们发现它并不能完全满足我们的需求,所以在 Helm 的基础上,我们自己研发了一套编排组件……
什么是编排
不知道大家有没仔细思考过编排到底是什么意思? 我查阅了 Wiki 百科,了解到我们常说的编排的英文单词为 “Orchestration”,它常被解释为:
- 本意:为管弦乐中的配器法,主要是研究各种管弦乐器的运用和配合方法,通过各种乐器的不同音色,以便充分表现乐曲的内容和风格。
- 计算机领域:引申为描述复杂计算机系统、中间件 (middleware) 和业务的自动化的安排、协调和管理。
有趣的是 “Orchestration” 的标准翻译应该为“编配”,而“编排”则是另外一个单词 “Choreography”,为了方便大家理解, 符合平时的习惯,我们还是使用编排 (Orchestration) 来描述下面的问题。至于“编配 (Orchestration)” 和 “编排(Choreography)” 之争,这里有一篇文章,有兴趣可以看一下 。http://www.infoq.com/cn/news/2008/09/Orchestration
Kubernetes 容器编排技术
当我们在说容器编排的时候,我们在说什么?
在传统的单体式架构的应用中,我们开发、测试、交付、部署等都是针对单个组件,我们很少听到编排这个概念。而在云的时代,微服务和容器大行其道,除了为我们显示出了它们在敏捷性,可移植性等方面的巨大优势以外,也为我们的交付和运维带来了新的挑战:我们将单体式的架构拆分成越来越多细小的服务,运行在各自的容器中,那么该如何解决它们之间的依赖管理,服务发现,资源管理,高可用等问题呢?
在容器环境中,编排通常涉及到三个方面:
- 资源编排 - 负责资源的分配,如限制 namespace 的可用资源,scheduler 针对资源的不同调度策略;
- 工作负载编排 - 负责在资源之间共享工作负载,如 Kubernetes 通过不同的 controller 将 Pod 调度到合适的 node 上,并且负责管理它们的生命周期;
- 服务编排 - 负责服务发现和高可用等,如 Kubernetes 中可用通过 Service 来对内暴露服务,通过 Ingress 来对外暴露服务。
在 Kubernetes 中有 5 种经常会用到的控制器来帮助我们进行容器编排,分别是 Deployment, StatefulSet, DaemonSet, CronJob, Job。
在这 5 种常见资源中,Deployment 经常被作为无状态实例控制器使用; StatefulSet 是一个有状态实例控制器; DaemonSet 可以指定在选定的 Node 上跑,每个Node 上会跑一个副本,它有一个特点是它的Pod的调度不经过调度器,在Pod 创建的时候就直接绑定NodeName;最后一个是定时任务,它是一个上级控制器,和 Deployment 有些类似,当一个定时任务触发的时候,它会去创建一个 Job,具体的任务实际上是由 Job 来负责执行的。他们之间的关系如下图: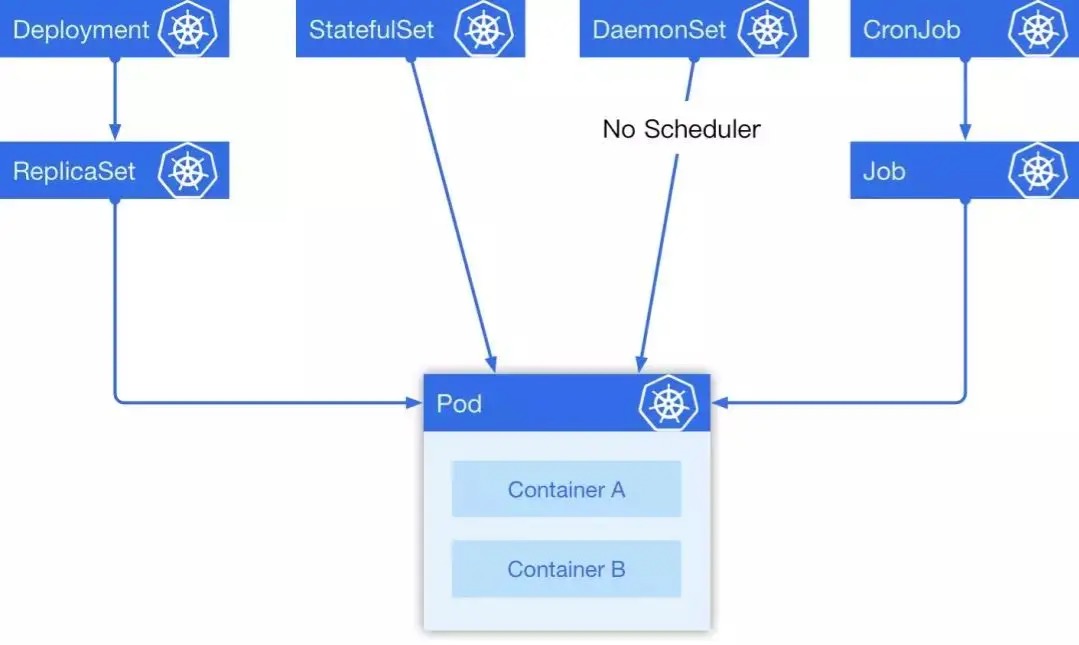
一个简单的例子
我们来考虑这么一个简单的例子,一个需要使用到数据库的 API 服务在 Kubernetes 中应该如何表示:
客户端程序通过 Ingress 来访问到内部的 API Service, API Service 将流量导流到 API Server Deployment 管理的其中一个 Pod 中,这个 Server 还需要访问数据库服务,它通过 DB Service 来访问 DataBase StatefulSet 的有状态副本。由定时任务 CronJob 来定期备份数据库,通过 DaemonSet 的 Logging 来采集日志,Monitoring 来负责收集监控指标。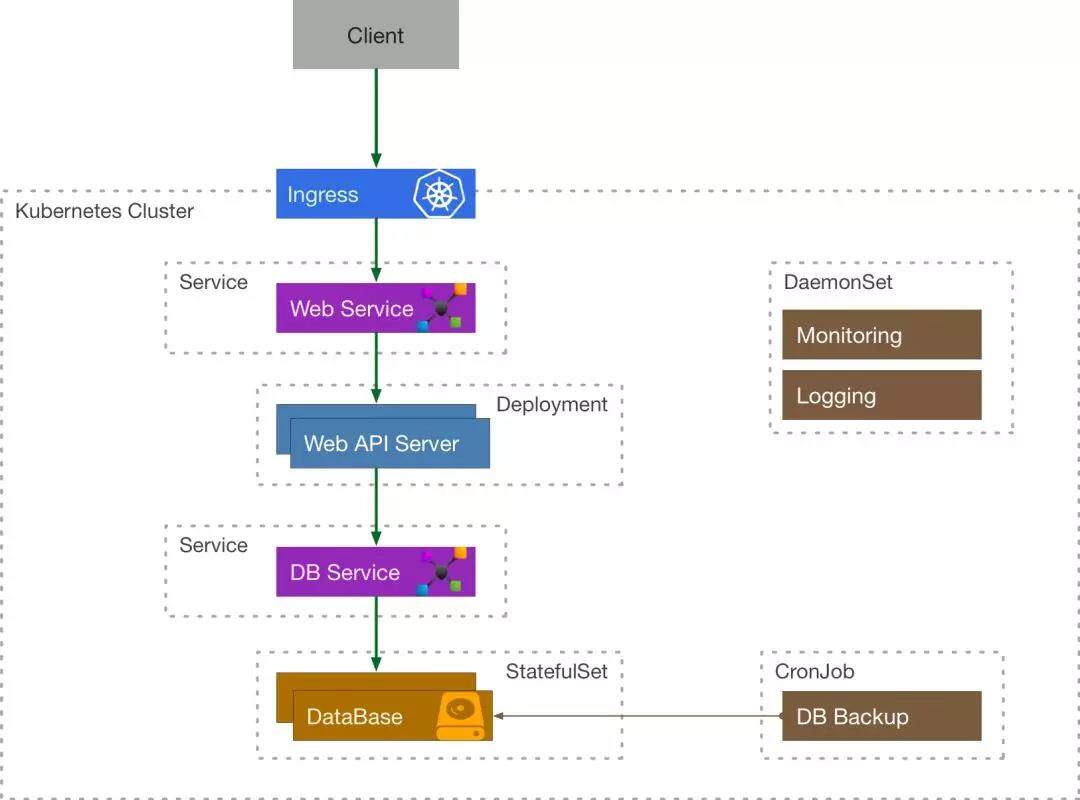
容器编排的困境
Kubernetes 为我们带来了什么?
通过上面的例子,我们发现 Kubernetes 已经为我们对大量常用的基础资源进行了抽象和封装,我们可以非常灵活地组合、使用这些资源来解决问题,同时它还提供了一系列自动化运维的机制:如 HPA, VPA, Rollback, Rolling Update 等帮助我们进行弹性伸缩和滚动更新,而且上述所有的功能都可以用 YAML 声明式进行部署。
困境
但是这些抽象还是在容器层面的,对于一个大型的应用而言,需要组合大量的 Kubernetes 原生资源,需要非常多的 Services, Deployments, StatefulSets 等,这里面用起来就会比较繁琐,而且其中服务之间的依赖关系需要用户自己解决,缺乏统一的依赖管理机制。
应用编排
什么是应用?
一个对外提供服务的应用,首先它需要一个能够与外部通讯的网络,其次还需要能运行这个服务的载体 (Pods),如果这个应用需要存储数据,这还需要配套的存储,所以我们可以认为:
应用单元 = 网络 + 服务载体 +存储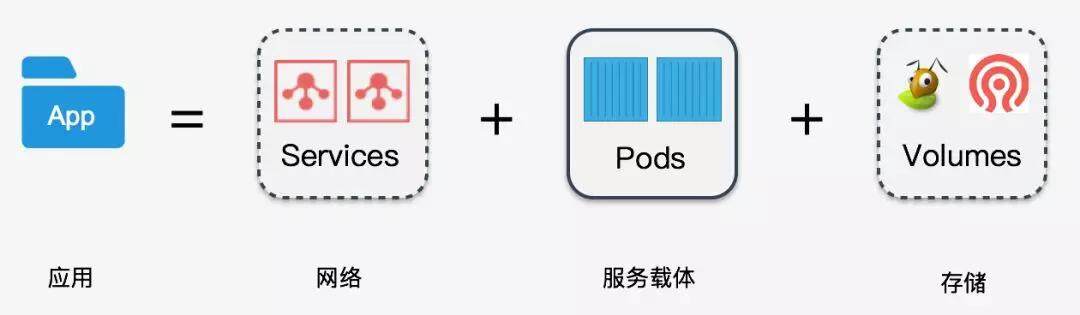
那么我们很容易地可以将 Kubernetes 的资源联系起来,然后将他们划分为 4 种类型的应用:
- 无状态应用 = Services + Volumes + Deployment
- 有状态应用 = Services + Volumes + StatefulSet
- 守护型应用 = Services + Volumes + DaemonSet
- 批处理应用 = Services + Volumes + CronJob/Job
我们来重新审视一下之前的例子: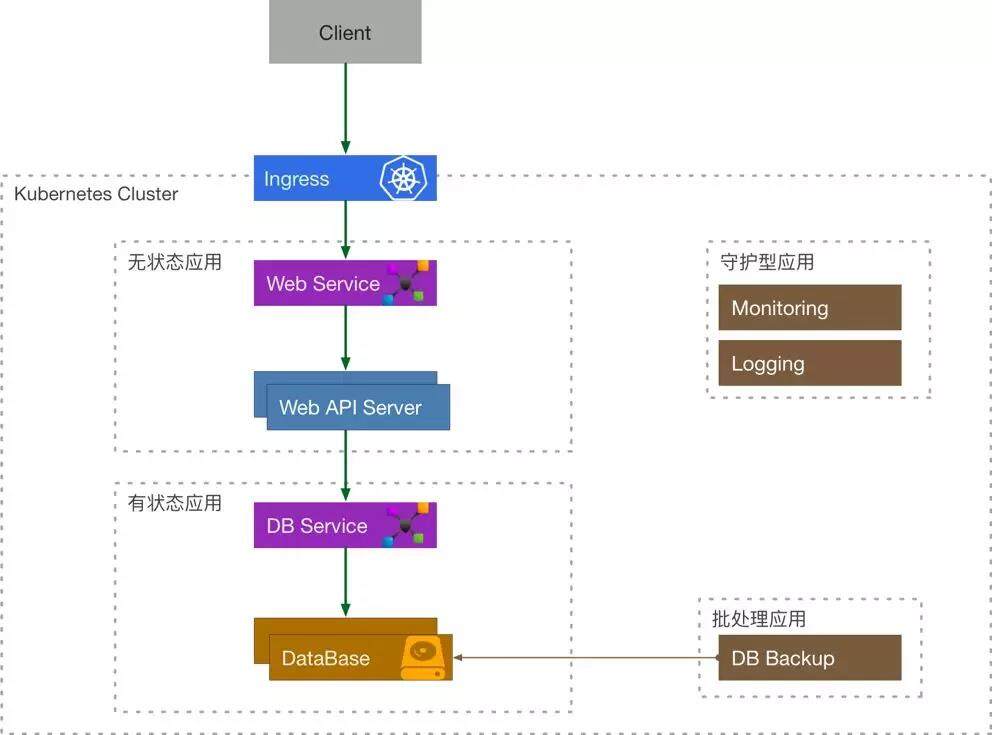
应用层面的四个问题
通过前面的探索,我们可以引出应用层面的四个问题:
- 应用包的定义
- 应用依赖管理
- 包存储
- 运行时管理
在社区中,这四个方面的问题分别由三个组件或者项目来解决:
- Helm Charts: 定义了应用包的结构以及依赖关系;
- Helm Registry: 解决了包存储;
- HelmTiller: 负责将包运行在 Kubernetes 集群中。
Helm Charts
Charts 在本质上是一个 tar 包,包含了一些 yaml 的 template 以及解析 template 需要的 values, 如下图:templates 是 Golang 的 template 模板,values.yaml 里面包含了这个 Charts 需要的值。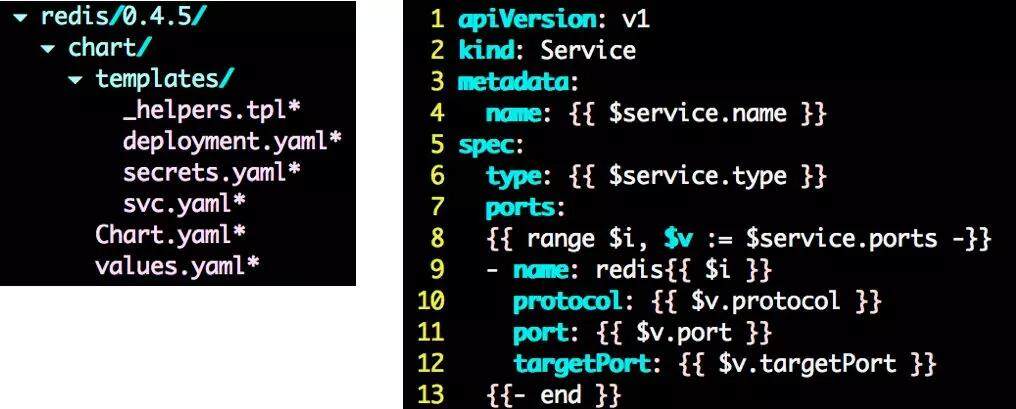
Helm Registry
用来负责存储和管理用户的 Charts, 并提供简单的版本管理,与容器领域的镜像仓库类似这个项目是开源的。( https://github.com/caicloud/helm-registry)
Tiller
- 负责将 Chart 部署到指定的集群当中,并管理生成的 Release (应用);
- 支持对 Release 的更新,删除,回滚操作;
- 支持对 Release 的资源进行增量更新;
- Release 的状态管理;
- Kubernetes下属子项目(https://github.com/kubernetes/helm) 。
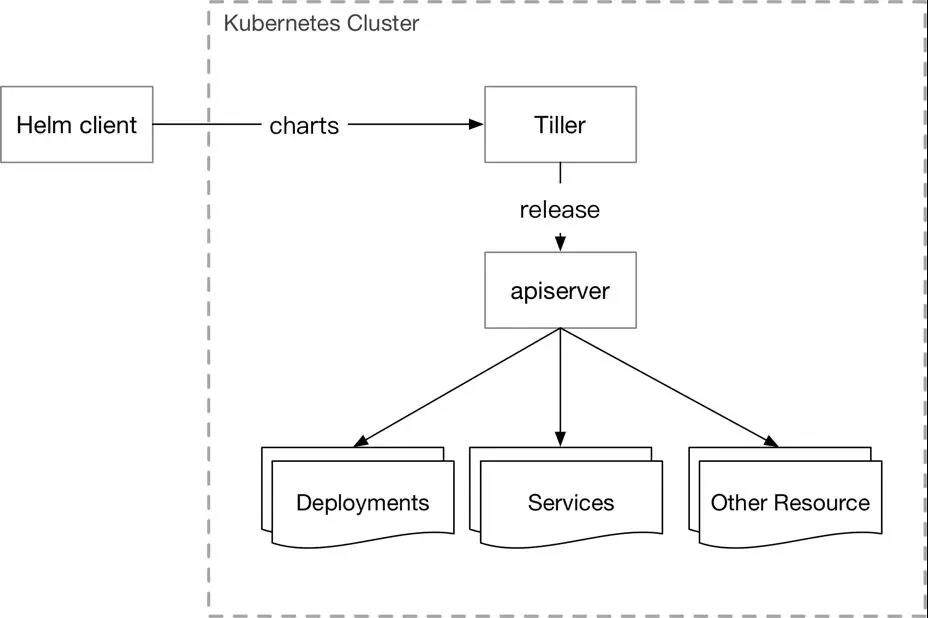
Tiller 的缺陷
- 没有内建的认知授权机制,Tiller 跑在 kube-system 分区下,拥有整个集群的权限;
- Tiller 将 Release 安装到 Kubernetes 集群中后并不会继续追踪他们的状态;
- Helm+Tiller的架构并不符合 Kubernetes 的设计模式,这就导致它的拓展性比较差;
- Tiller 创建的 Release 是全局的并不是在某一个分区下,这就导致多用户/租户下,不能进行隔离;
- Tiller 的回滚机制是基于更新的,每次回滚会使版本号增加,这不符合用户的直觉。
Release Controller
为了解决上述的问题,我们基于 Kubernetes 的 Custom Resource Definition 设计并实现了我们自己的运行时管理系统 – Release Controller, 为此我们设计了两个新的 CRD – Release 和 Release History。
Release 创建
当 Release CRD 被创建出来,controller 为它创建一个新的 Release History, 然后将 Release 中的 Chart 和 Configuration 解析成 Kubernetes 的资源,然后将这些资源在集群中创建出来,同时会监听这些资源的变化,将它们的状态反映在 Release CRD 的 status 中。
Release 更新
当用户更新 Release 的时候,controller 计算出更新后的资源与集群中现有资源的 diff, 然后删除一部分,更新一部分,创建一部分,来使得集群中的资源与 Release 描述的一致,同时为旧的 Release 创建一份 Release History。
Release 回滚和删除
用户希望回滚到某一个版本的 Release, controller 从 Release History 中找到对应的版本,然后将 Release 的 Spec 覆盖,同时去更新集群中对应的资源。当 Release 被删除后,controller 将它关联的 Release History 删除,同时将集群中的其他资源一并删除。
架构图 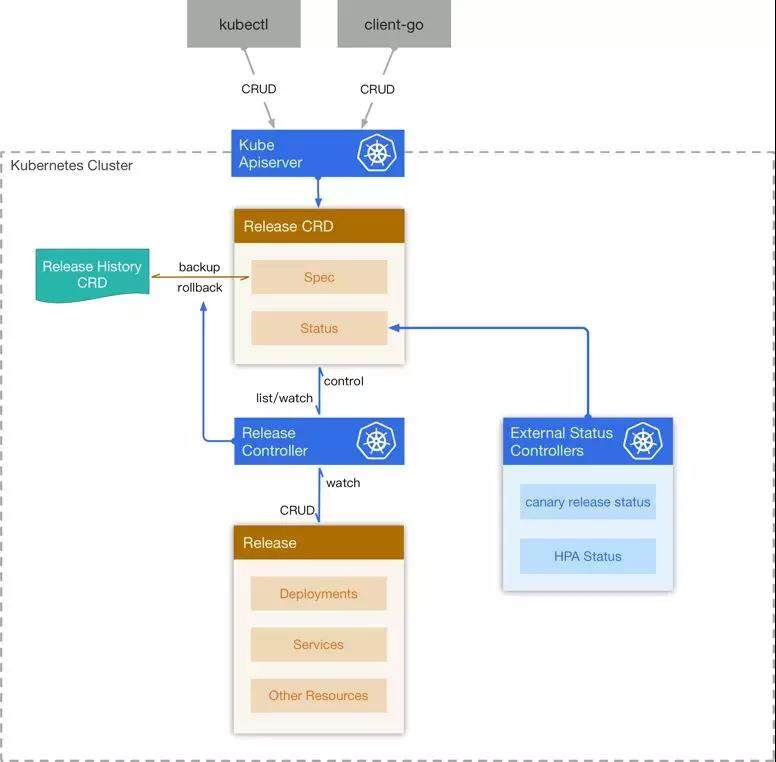
这样的设计有什么好处?
- 隔离性:资源使用 Namespace 隔离,适应多用户/租户;
- 可读性:Release Controller 会追踪每个 Release 的子资源的状态;
- 版本控制:你可以很容易地会退到某一个版本;
- 拓展性:整个架构是遵循 Kubernetes 的 controller pattern,具有良好的可扩展性,可以在上面进行二次开发;
- 安全性:因为所有的操作都是基于 Kubernetes 的 Resource,可以充分利用 Kubernetes 内建的认证鉴权模块,如 ABAC, RBAC 。
总而言之,编排不仅仅是一门技术也是一门艺术!谢谢!
分享阅读原文链接:https://mp.weixin.qq.com/s/zHlS2cQEHzRea_bqKpNA9A
漏洞风险评估CVSS介绍
运维 koyo 发表了文章 0 个评论 5318 次浏览 2021-11-06 17:29

什么是CVSS
通用弱点评价体系(CVSS)是由NIAC开发、FIRST维护的一个开放并且能够被产品厂商免费采用的标准。利用该标准,可以对弱点进行评分,进而帮助我们判断修复不同弱点的优先等级。
CVSS(Common Vulnerability Scoring System),即”通用漏洞评分系统”,是一个”行业公开标准,其被设计用来评测漏洞的严重程度,并帮助确定所需反应的紧急度和重要度”。
它的主要目的是帮助人们建立衡量漏洞严重程度的标准,使得人们可以比较漏洞的严重程度,从而确定处理它们的优先级。CVSS得分基于一系列维度上的测量结果,这些测量维度被称为量度(Metrics)。漏洞的最终得分最大为10,最小为0。
得分7~10的漏洞通常被认为比较严重,得分在4~6.9之间的是中级漏洞,0~3.9的则是低级漏洞。
CVSS系统包括三种类型的分数:基本分数、暂时分和环境分。
基本得分和临时得分通常由安全产品卖主、供应商给出,因为他们能够更加清楚的了解漏洞的详细信息;
环境得分通常由用户给出,因为他们能够在自己的使用环境下更好的评价该漏洞存在的潜在影响。
所以应该是基于漏洞库的扫描, 需要预先知道该漏洞的威胁值?
就是说漏洞应该预先有脆弱性等级,系统的安全性评估是综合各个漏洞来进行的?
CVSS 2.0 计算方法: 通用漏洞评估方法CVSS 3.0 计算公式及说明 - caya - 博客园 (cnblogs.com)
一些指标具有不确定性和复杂性,会导致完全的定量分析困难。3个客观性指标和11个主观性指标。下一步:指标量化(客观性指标量化和主观性指标量化)。
CVSS评分计算方法
A. 基本评价(Base Metric)
基本评价指的是该漏洞本身固有的一些特点及这些特点可能造成的影响的评价分值
| 序号 | 要素 | 可选值 | 评分 |
|---|---|---|---|
| 1 | 攻击途径 (AccessVector) | 本地/远程 | 0.7/1.0 |
| 2 | 攻击复杂度(AccessComplexity) | 高/中/低 | 0.6/0.8/1.0 |
| 3 | 认证(Authentication) | 需要/不需要 | 0.6/1.0 |
| 4 | 机密性(Conflmpact) | 不受影响/部分/完全 | 0/0.7/1 |
| 5 | 完整性(integlmpact) | 不受影响/部分/完全 | 0/0.7/1 |
| 6 | 可用性(Availlmpact) | 不受影响/部分/完全 | 0/0.7/1 |
| 7 | 权值倾向 | 平均/机密性/完整性/可用性 | 各0.333/权值倾向要素0.5另两个0.25 |
基础评价 = 四舍五入(10 * 攻击途径 攻击复杂度 认证 ((机密性 机密性权重) + (完整性 完整性权重) + (可用性 可用性权重)))
B.生命周期评价(Temporal Metric)
是针对最新类型漏洞(如: 0day漏洞)设置的评分项,因此SQL注入漏洞不用考虑。
因此这里也列举出三个与时间紧密关联的要素如下:
| 序号 | 要素 | 可选值 | 评分 |
|---|---|---|---|
| 1 | 可利用性 | 未证明/概念证明/功能性/完全代码 | 0.85/0.9/0.95/1.0 |
| 2 | 修复措施 | 官方补丁/临时补丁/临时解决方案/无 | 0.87/0.90/0.95/1.0 |
| 3 | 确认程度 | 不确认/未经确认/已确认 | 0.9/0.95/1.0 |
生命周期评价 =四舍五入(基础评价 可利用性 修复措施 * 未经确认)
C.环境评价(Environmental Metric)
每个漏洞会造成的影响大小都与用户自身的实际环境密不可分,因此可选项中也包括了环境评价,这可以由用户自评。(用户扫描配置时填写)
| 序号 | 要素 | 可选值 | 评分 |
|---|---|---|---|
| 1 | 危害影响程度 | 无/低/中/高 | 0/0.1/0.3/0.5 |
| 2 | 目标分布范围 | 无/低/中/高(0/1-15%/16-49%/50-100%) | 0/0.25/0.75/1.0 |
环境评价 = 四舍五入<(生命周期评价 + [(10 -生命周期评价) *危害影响程度]) *目标分布范围>
评分与危险等级
| 序号 | 评分 | 危险等级 |
|---|---|---|
| 1 | [0,4] | 低 |
| 2 | [4,7] | 中 |
| 3 | [7,10] | 高 |
使用kubekey部署kubernetes集群
DevOps Rock 发表了文章 0 个评论 2650 次浏览 2021-10-22 11:52

kubekey简介
kubeykey是KubeSphere基于Go 语言开发的kubernetes集群部署工具,使用 KubeKey,您可以轻松、高效、灵活地单独或整体安装 Kubernetes 和 KubeSphere。
KubeKey可以用于以下三种安装场景:
- 仅安装 Kubernetes集群
- 使用一个命令安装 Kubernetes 和 KubeSphere
- 已有Kubernetes集群,使用ks-installer 在其上部署 KubeSphere
项目地址:https://github.com/kubesphere/kubekey 开源公司:青云
kubekey安装
下载kk二进制部署命令,您可以在任意节点下载该工具,比如准备一个部署节点,或者复用集群中已有节点:
wget https://github.com/kubesphere/kubekey/releases/download/v1.2.0-alpha.2/kubekey-v1.2.0-alpha.2-linux-amd64.tar.gz
tar -zxvf kubekey-v1.2.0-alpha.2-linux-amd64.tar.gz
mv kk /usr/local/bin/
脚本下载安装:
export KKZONE=cn
curl -sfL | VERSION=v1.1.0 sh -
mv kk /usr/local/bin/
查看版本:
kk version
在所有节点上安装相关依赖
yum install -y socat conntrack ebtables ipset
所有节点关闭selinux和firewalld
setenforce 0 && sed -i 's/^SELINUX=enforcing$/SELINUX=disabled/' /etc/selinux/config
systemctl disable --now firewalld
所有节点时间同步
yum install -y chrony
systemctl enable --now chronyd
timedatectl set-timezone Asia/Shanghai
节点无需配置主机名,kubekey会自动纠正主机名。
部署单节点集群
部署单节点kubernetes
kk create cluster
同时部署kubernetes和kubesphere,可指定kubernetes版本或kubesphere版本
kk create cluster --with-kubernetes v1.20.4 --with-kubesphere v3.1.0
当指定安装KubeSphere时,要求集群中有可用的持久化存储。默认使用localVolume,如果需要使用其他持久化存储,请参阅addons配置。
部署多节点集群
准备6个节点,部署高可用kubernetes集群,kubekey的高可用实现目前是基于haproxy的本地负载均衡模式。
创建示例配置文件:
kk create config
根据您的环境修改配置文件config-sample.yaml,以下示例以部署3个master节点和3个node节点为例(不执行kubesphere部署,仅搭建kubernetes集群):
cat > config-sample.yaml <使用配置文件创建集群
export KKZONE=cn
kk create cluster -f config-sample.yaml | tee kk.log
创建完成后查看节点状态
[root@kube-master1 ~]# kubectl get nodes -o wide
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
kube-master1 Ready control-plane,master 4m58s v1.20.6 192.168.93.60 CentOS Linux 7 (Core) 3.10.0-1127.el7.x86_64
kube-master2 Ready control-plane,master 3m58s v1.20.6 192.168.93.61 CentOS Linux 7 (Core) 3.10.0-1127.el7.x86_64
kube-master3 Ready control-plane,master 3m58s v1.20.6 192.168.93.62 CentOS Linux 7 (Core) 3.10.0-1127.el7.x86_64
kube-node1 Ready worker 4m13s v1.20.6 192.168.93.63 CentOS Linux 7 (Core) 3.10.0-1127.el7.x86_64
kube-node2 Ready worker 3m59s v1.20.6 192.168.93.64 CentOS Linux 7 (Core) 3.10.0-1127.el7.x86_64
kube-node3 Ready worker 3m59s v1.20.6 192.168.93.65 CentOS Linux 7 (Core) 3.10.0-1127.el7.x86_64
查看所有pod状态
[root@kube-master1 ~]# kubectl get pods -A
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system calico-kube-controllers-8545b68dd4-rbshc 1/1 Running 2 3m48s
kube-system calico-node-5k7b5 1/1 Running 1 3m48s
kube-system calico-node-6cv8z 1/1 Running 1 3m48s
kube-system calico-node-8rbjs 1/1 Running 0 3m48s
kube-system calico-node-d6wkc 1/1 Running 0 3m48s
kube-system calico-node-q8qp8 1/1 Running 0 3m48s
kube-system calico-node-rvqpj 1/1 Running 0 3m48s
kube-system coredns-7f87749d6c-66wqb 1/1 Running 0 4m58s
kube-system coredns-7f87749d6c-htqww 1/1 Running 0 4m58s
kube-system haproxy-kube-node1 1/1 Running 0 4m3s
kube-system haproxy-kube-node2 1/1 Running 0 4m3s
kube-system haproxy-kube-node3 1/1 Running 0 2m47s
kube-system kube-apiserver-kube-master1 1/1 Running 0 5m13s
kube-system kube-apiserver-kube-master2 1/1 Running 0 4m10s
kube-system kube-apiserver-kube-master3 1/1 Running 0 4m16s
kube-system kube-controller-manager-kube-master1 1/1 Running 0 5m13s
kube-system kube-controller-manager-kube-master2 1/1 Running 0 4m10s
kube-system kube-controller-manager-kube-master3 1/1 Running 0 4m16s
kube-system kube-proxy-2t5l6 1/1 Running 0 3m55s
kube-system kube-proxy-b8q6g 1/1 Running 0 3m56s
kube-system kube-proxy-dsz5g 1/1 Running 0 3m55s
kube-system kube-proxy-g2gxz 1/1 Running 0 3m55s
kube-system kube-proxy-p6gb7 1/1 Running 0 3m57s
kube-system kube-proxy-q44jp 1/1 Running 0 3m56s
kube-system kube-scheduler-kube-master1 1/1 Running 0 5m13s
kube-system kube-scheduler-kube-master2 1/1 Running 0 4m10s
kube-system kube-scheduler-kube-master3 1/1 Running 0 4m16s
kube-system nodelocaldns-l958t 1/1 Running 0 4m19s
kube-system nodelocaldns-n7vkn 1/1 Running 0 4m18s
kube-system nodelocaldns-q6wjc 1/1 Running 0 4m33s
kube-system nodelocaldns-sfmcc 1/1 Running 0 4m58s
kube-system nodelocaldns-tvdbh 1/1 Running 0 4m18s
kube-system nodelocaldns-vg5t7 1/1 Running 0 4m19s
kubekey集群维护
添加节点
kk add nodes -f config-sample.yaml
删除节点
kk delete node -f config-sample.yaml
删除集群
kk delete cluster
kk delete cluster [-f config-sample.yaml]
集群升级
kk upgrade [--with-kubernetes version] [--with-kubesphere version]
kk upgrade [--with-kubernetes version] [--with-kubesphere version] [(-f | --file) path]
什么是PDCA模型和SMART原则
创意生活 OS小编 发表了文章 0 个评论 2910 次浏览 2021-09-15 17:23
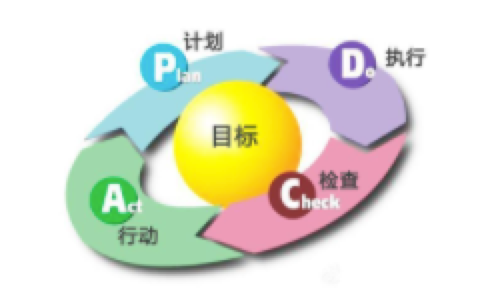
什么是 PDCA 模型?
PDCA 循环是提高工作质量的理论方法,广泛应用在企业管理和个人工作中。P-D-C-A 这四个字母,分别代表:Plan(计划),Do(行动),Check(检查),Act(处理)。美国的质量管理大师戴明认为,高质量,不是来自基于结果的产品检验,而是来自于基于过程的不断改善。
PDCA循环的四个过程
第一,Plan(计划)
一个 PDCA 循环式的「计划」,一定要有「Who do what by when」,也就是:「谁在什么时间之前做什么」,发给大家,而不是口头布置。
第二,Do(行动)
行动,是最占用时间,也是最重要的部分。因为有了计划,以及基于计划分解的,分配到每个人任务栏里的,有时间限制的具体任务,执行就变得责任明确、优先级清晰。
第三,Check(检查)
每一件交代出去的任务,就像一个扔出去的回行镖,最终必须回到你的手上。这是 PDCA 的关键。
第四,Act(处理)
处理不是行动,而是总结成功经验,制定相应标准,或者把未解决或新出现的问题转入下一个 PDCA 循环。
什么是 SMART 原则?
SMART原则是一套制定目标的原则。S-M-A-R-T这5个字母,代表Specific(具体的),Measurable(可衡量的),Attainable(可实现的),Relevant(相关的),和Time-Based(有时间限制的)。
它的本质,是砍掉模棱两可,砍掉标准争议,砍掉不切实际,砍掉无关目标,砍掉无限拖延,让目标从“一千个人心中的一千个哈姆雷特”,变成同一个。
五个字母的含义
第一,Specific(具体的)
绩效考核要切中特定的工作指标,不能笼统。
第二,Measurable(可衡量的)
绩效指标是数量化或者行为化的,验证这些绩效指标的数据或者信息是可以获得的。
第三,Attainable(可实现的)
绩效指标在付出努力的情况下可以实现,避免设立过高或过低的目标。
第四,Relevant(相关性的)
绩效指标是与工作的其它目标是相关联的;绩效指标是与本职工作相关联的。
第五,Time-bound(有时间限制的)
注重完成绩效指标的特定期限。





