
什么是CICD
传统的应用发布模式
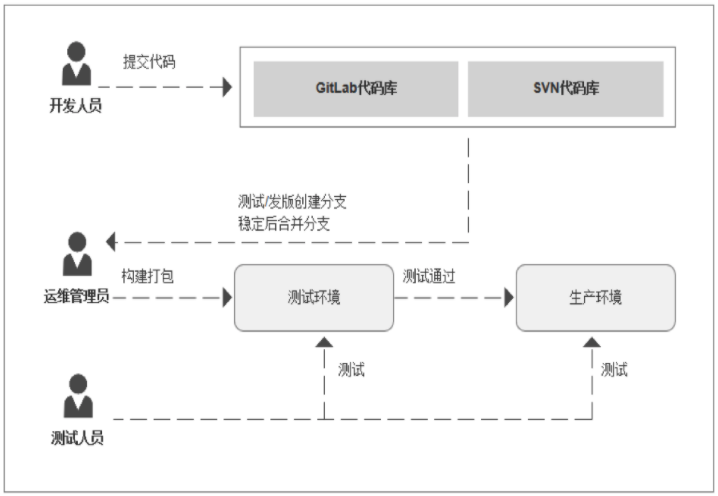
如果你经历体验过传统的应用发布,你可能就会觉得CICD有足够吸引你的地方,反之亦然。一般一个研发体系中都会存在多个角色:开发、测试、运维。当时我们的应用发布模式可以能是这样的:
- 开发团队在开发环境中完成软件开发,单元测试,测试通过,提交到代码版本管理库;
- 开发同学通知运维同学项目可以发布了,然后运维同学下载代码进行打包和构建,生成应用制品;
- 运维同学使用部署脚本将生成的制品部署到测试环境,并提示测试同学可以进行产品的测试;
- 测试同学开始进行手动、自动化测试,测试完成后提醒运维同学可以进行预生产环境部署;
- 运维同学开始进行预生产环境部署,然后测试同学进行测试,测试完成后,开始部署生产环境。
当然我描述的可能只是其中的一部分,手动操作很多、出现的问题很多。上面看似很流畅的过程,其实每次构建或发布都可能会出现问题。未对每次提交验证、构建环境不一致:开发人员本地测试成功后提交代码,运维同学下载代码进行编译却出现了错误。
存在的问题:
- 错误发现不及时: 很多错误在项目的早期可能就存在,到最后集成的时候才发现问题;
- 人工低级错误发生: 产品和服务交付中的关键活动全都需要手动操作;
- 团队工作效率低: 需要等待他人的工作完成后才能进行自己的工作;
- 开发运维对立: 开发人员想要快速更新,运维人员追求稳定,各自的针对的方向不同。
经过上述问题我们需要作出改变,如何改变?
什么是CICD
软件开发的连续方法基于自动执行脚本,以最大程度地减少在开发应用程序时引入错误的机会。从开发新代码到部署新代码,他们几乎不需要人工干预,甚至根本不需要干预。
它涉及到在每次小的迭代中就不断地构建,测试和部署代码更改,从而减少了基于错误或失败的先前版本开发新代码的机会。
此方法有三种主要方法,每种方法都将根据最适合您的策略的方式进行应用。
持续集成 CI(Continuous Integration)
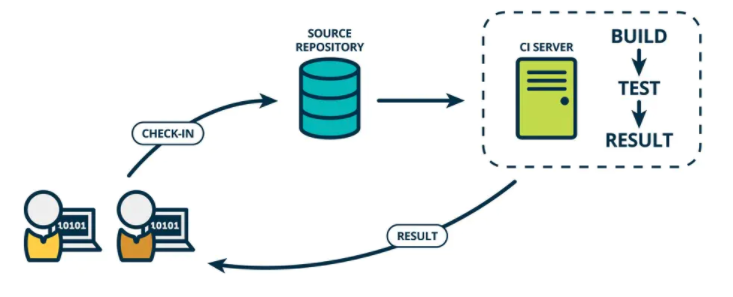
在传统软件开发过程中,集成通常发生在每个人都完成了各自的工作之后。在项目尾声阶段,通常集成还要痛苦的花费数周或者数月的时间来完成。持续集成是一个将集成提前至开发周期的早期阶段的实践方式,让构建、测试和集成代码更经常反复地发生。
开发人员通常使用一种叫做CI Server的工具来做构建和集成。持续集成要求史蒂夫和安妮能够自测代码。分别测试各自代码来保证它能够正常工作,这些测试通常被称为单元测试(Unit tests)。
代码集成以后,当所有的单元测试通过,史蒂夫和安妮就得到了一个绿色构建(Green Build)。这表明他们已经成功地集成在一起,代码正按照测试预期地在工作。然而,尽管集成代码能够成功地一起工作了,它仍未为生产做好准备,因为它没有在类似生产的环境中测试和工作。
CI是需要对开发人员每次的代码提交进行构建测试验证。确定每次提交的代码都是可以正常编译测试通过的。在没有持续集成服务器的时候,我们可以写一个程序来监听版本控制系统的状态,当出现了push动作则触发相应的脚本运行编译构建等步骤。现在有了专业的持续集成服务器后,我们借助持续集成服务器来实现版本控制系统中代码提交触发构建测试等验证步骤。
持续合并开发人员正在开发编写的所有代码的一种做法。通常一天内进行多次合并和提交代码,从存储库或生产环境中进行构建和自动化测试,以确保没有集成问题并及早发现任何问题。
开发人员提交代码的时候一般先在本地测试验证,只要开发人员提交代码到版本控制系统就会触发一条提交流水线,对本次提交进行验证。
持续交付 CD (Continuous Delivery)
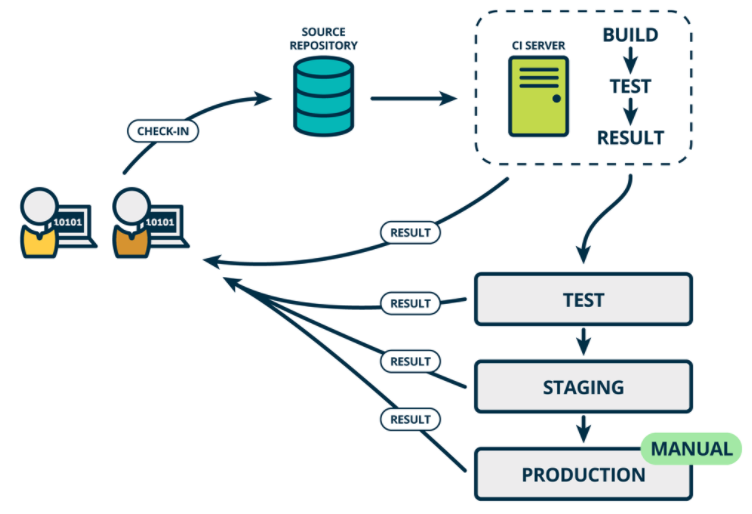
Continuous Delivery (CD) 持续交付是持续集成的延伸,将集成后的代码部署到类生产环境,确保可以以可持续的方式快速向客户发布新的更改。如果代码没有问题,可以继续手工部署到生产环境中。
持续交付CD:是基于持续集成的基础上,将集成后的代码自动化的发布到各个环境中测试(DEV TEST UAT STAG),确定可以发布生产版本。这里我们可以借用制品库实现制品的管理,根据环境类型创建对应的制品库。一次构建,到处运行。
- 开发环境发布:我们可以将开发环境产出的制品部署进行测试,没有问题后上传到测试环境的制品库中。
- 测试环境发布:此时通知测试人员可以进行测试环境发布测试,获取测试环境制品库中的制品,发布到测试环境验证。验证通过将制品上传到预生产环境制品库。
- 预生产环境发布:获取预生产环境制品,进行部署测试。测试成功后可以将制品上传到生产库中。
- 手动部署生产环境。
持续交付是超越持续集成的一步。不仅会在推送到代码库的每次代码更改时都进行构建和测试,而且,作为附加步骤,即使部署是手动触发的,它也可以连续部署。此方法可确保自动检查代码,但需要人工干预才能从策略上手动触发更改的部署。
持续部署 CD(Continuous Deploy)
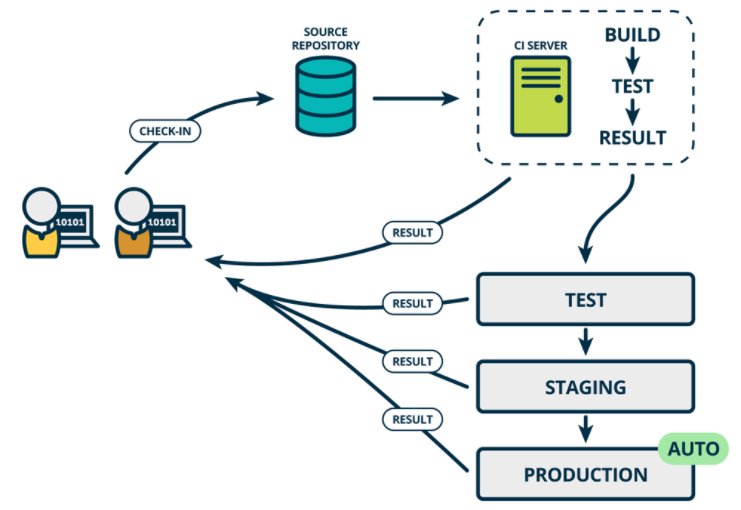
如果真的想获得持续交付的好处,应该尽早部署到生产环境,以确保可以小批次发布,在发生问题时可以轻松排除故障。于是有了持续部署。
通常可以通过将更改自动推送到发布系统来随时将软件发布到生产环境中。持续部署 会更进一步,并自动将更改推送到生产中。类似于持续交付,持续部署也是超越持续集成的进一步。不同之处在于,您无需将其手动部署,而是将其设置为自动部署。部署您的应用程序完全不需要人工干预。
持续部署CD:是基于持续交付的基础上,将在各个环境经过测试的应用自动化部署到生产环境。其实各个环境的发布过程都是一样的。应用发布到生产环境后,我们需要对应用进行健康检查、添加应用的监控项、 应用日志管理。
我们通常将这个在不同环境发布和测试的过程叫做部署流水线, 持续部署是在持续交付的基础上,把部署到生产环境的过程自动化。
参考:
收起阅读 »
https://blog.csdn.net/weixin_40046357/article/details/107478696
http://www.idevops.site/gitlabci/chapter01/01/
https://www.jianshu.com/p/654505d42180
最全医疗细分赛道龙头
今天花时间总结下医疗各赛道龙头公司,每个公司的产品都是自己独特的护城河,或者有的公司有自己的祖传秘方,我们投资的目标就是找寻市场最牛的,最有需求的公司,今天我列举出来,每个人的理解不同,估计还不是很全面。
恒瑞医药:肿瘤创新药龙头,医药总龙头
爱尔眼科:眼科医疗服务龙头
迈瑞医疗:医疗器械总龙头
药明康德:医药CXO龙头
长春高新:生长激素龙头
片仔癀:中药龙头
美年健康:体检医疗服务龙头
云南白药:传统中医药龙头
复星医药:创新药龙头老二,医药综合龙头
乐普医疗:心脏支架系统龙头
新和成:维生素龙头
华兰生物:血液制品龙头
智飞生物:疫苗代理销售龙头
人福医药:麻醉药龙头
科伦药业:大输液龙头
康泰生物:乙肝、肺炎疫苗龙头
我武生物:脱敏药龙头
鱼跃医疗:家用医疗器械龙头
健帆生物:血液灌流器械龙头
健友股份:肝素原料药龙头
华大基因:基因检测龙头
汤臣倍健:保健品龙头
欧普康视:角膜塑形镜龙头
三诺生物:血糖监测仪龙头
安图生物:化学发光试剂龙头
南微医学:微创手术器械龙头
大博医疗:骨科龙头
透景生命:体外试剂诊断龙头
通化东宝:糖尿病药龙头之一
甘李药业:糖尿病药龙头之一
山大华特:新生儿补充剂龙头
司太立: 造影剂龙头
戴维医疗:新生儿医疗器械龙头
沃森生物:肺炎疫苗和HPV疫苗龙头
凯利泰:椎体成形微创介入手术、骨科植入、骨科手术器械龙头。
三友医疗:脊椎类植入耗材、创伤类植入耗材龙头。
楚天科技:医药装备龙头。
华海药业:特色原料药龙头。全球最大的普利类和沙坦类药物提供商。
康美药业:国内中药饮品龙头。
卫宁健康:医疗信息龙头。
英科医疗:专精医用手套世界级龙头。
康龙化成:国内第二、全球第三的临床前CRO企业,次于药明康德。
昭衍新药:临床前CRO安全性评价龙头。
凯莱英:小分子化学制药CDMO龙头
药石科技:药物分子砌块领域CRO龙头
泰格医药:专注定位CRO这个细分市场并成为临床CRO行业龙头
通策医疗:国内口腔医疗龙头,从医生+口碑两个方面加深自己的护城河。
国瓷材料:全资子公司爱尔创在国内高端陶瓷牙用纳米氧化锆市占率第一。
爱美客:注射用玻尿酸龙头,聚焦于医美终端产品。公司研发能力很强,多款产品属于国内首款。
华熙生物:玻尿酸原料龙头,是世界最大的透明质酸生产及销售企业。全产业链布局,在医美和化妆品赛道持续发力。
金域医学:国内第三方医学检验龙头企业,行业核心在于数据积累,数据库越大,检验效率、准确率越高。
万孚生物:即时检测龙头,在POCT领域惟精惟一。
艾德生物:聚焦肿瘤检测。
大参林:国内连锁药店的龙头之一,四大药房中毛利率净利润率排名第一,盈利能力较强,稳扎稳打型。
益丰药房:国内连锁药店的龙头之一。
医疗行业是非常复杂的行业,很多公司都具备自己独特的立身之本,很多小公司靠一两个产品都能稳定于市场之中长期活下去,跟随医疗的上面三大逻辑不断壮大。各位朋友,今天的文章,建议大家收藏,有个大体了解就好。
分享阅读原文: https://henduan.com/Flkgz
敏捷为什么要使用Scrum而不是瀑布?
Scrum方法需要改变传统方法的思维方式。中心焦点已经从瀑布方法的范围转变为在Scrum中实现最大的商业价值。
在瀑布中,改变成本和进度以确保达到预期的范围,在Scrum中,可以改变质量和约束以实现获得最大商业价值的主要目标。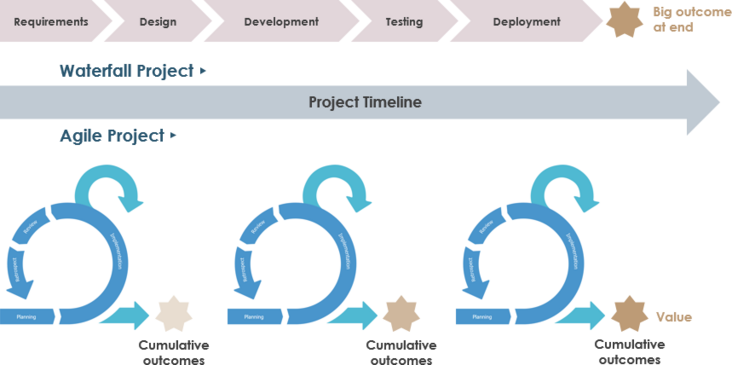
瀑布模型适用于有序和可预测的项目,其中所有要求都明确定义并且可以准确估计,并且在大多数行业中,此类项目正在减少。客户需求的变化导致企业适应和改变其交付方式的压力增大。
Scrum方法在当前市场中更为成功,其特点是不可预测性和波动性。Scrum方法基于inspect-adapt循环,而不是Waterfall方法的命令和控制结构。
Scrum项目以迭代方式完成,其中首先完成具有最高业务价值的功能。各个跨职能团队在Sprint中并行工作,以便在每个Sprint结束时提供潜在的可交付解决方案。
因为每次迭代都会产生可交付的解决方案(这是整个产品的一部分),所以团队必须实现可衡量的目标。这可确保团队正在进行,项目将按时完成。传统方法没有提供这种及时的检查,因此导致团队可能会下班并最终完成大量工作。
当客户定期与团队互动时,定期审查完成的工作; 因此,可以确保进度符合客户的要求。然而,在瀑布中没有这样的交互,因为工作是在筒仓中进行的,并且在项目结束之前没有可用的功能。
在复杂的项目中,客户不清楚他们在最终产品中需要什么,并且功能需求不断变化,迭代模型可以更灵活地确保在项目完成之前可以包含这些更改。
但是,当完成具有明确定义的功能的简单项目,并且当团队具有完成此类项目的先前经验(因此,估计将是准确的)时,瀑布方法可以是成功的。
敏捷 Vs 瀑布
下面是一个表格,可以更好地了解Scrum和瀑布的差异。
敏捷还是瀑布?
Standish Group的最新报告涵盖了他们在2013年至2017年期间研究的项目。在这段时间内,敏捷和瀑布的成功,挑战和失败的整体突破如下所示,敏捷项目成功的可能性大约是后者的2倍,失败的可能性降低1/3。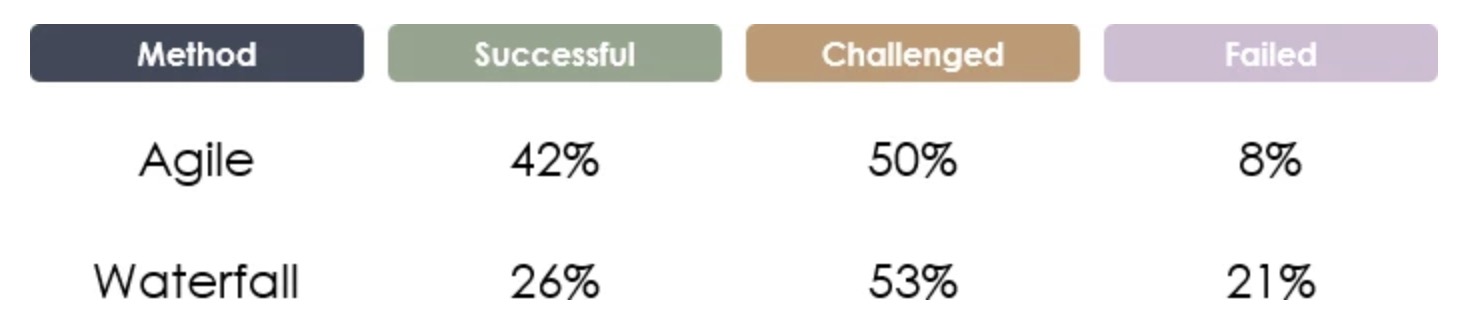
来源:vitalitychicago.com - 比较瀑布和敏捷项目成功率
分享阅读: https://henduan.com/Aynya
收起阅读 »cmake编译程序设置动态链接库加载路径
编译运行的程序需要链接到程序所在路径下的某些个动态库,为方便移植,必须设置链接库的相对路径,比如./lib等等。默认在Linux系统下动态库的搜寻路径如下:
- 使用选项
-Wl,-rpath在编译时指定; - 通过配置
LD_LIBRARY_PATH来指定; - 在
/lib和/usr/lib中查找;
其中第一个在gcc编译选项中添加:-Wl,rpath=xxx会将rpath路径写入到程序中保存起来。
为了方便移植运行一些编译安装的应用程序,在编译的时候需要设置链接库读取的相对路径目录, 比如../lib 或者./lib。
默认在Linux系统下动态库的搜寻路径如下:
- 使用选项
-Wl,-rpath在编译时指定rpath; - 通过配置
LD_LIBRARY_PATH来指定,运行加载; - 在
/lib和/usr/lib等系统默认动态库路径中查找。
其中第一个在gcc编译选项中添加:-Wl,rpath=xxx会将rpath路径写入到程序中保存起来。
以下两种方式都可以用来配置rpath路径。
1、使用gcc编译选项:
add_definitions(-std=c++11)
SET(CMAKE_CXX_FLAGS_DEBUG "$ENV{CXXFLAGS} -O0 -Wall -g -ggdb -Wl,-rpath=./:./lib") #-Wl,-rpath=./
SET(CMAKE_CXX_FLAGS_RELEASE "$ENV{CXXFLAGS} -O3 -Wl,-rpath=./:./lib") #-Wall
2、使用cmake配置
set(CMAKE_SKIP_BUILD_RPATH FALSE)
set(CMAKE_BUILD_WITH_INSTALL_RPATH TRUE)
set(CMAKE_INSTALL_RPATH_USE_LINK_PATH TRUE)
set(CMAKE_INSTALL_RPATH "./lib")
或者
SET(CMAKE_SKIP_BUILD_RPATH FALSE)
SET(CMAKE_BUILD_WITH_INSTALL_RPATH FALSE)
SET(CMAKE_INSTALL_RPATH "${CMAKE_INSTALL_PREFIX}/lib:$ORIGIN/lib")
SET(CMAKE_INSTALL_RPATH_USE_LINK_PATH TRUE)
其中RPATH可以使用"./lib"或"./"配置,有可以使用"$ORIGIN/lib"或"\${ORIGIN}/lib",这里必须加上\符号,否则无法识别。
还可以同时定义多个RPATH,比如:"$ORIGIN:$ORIGIN/lib",中间使用:分割。
参考:https://blog.csdn.net/wh8_2011/article/details/79519293
CMAKE和RPATH:https://blog.csdn.net/zhangzq86/article/details/80718559
CMAKE中RPATH的用法:https://blog.csdn.net/z296671124/article/details/86699720
Linux C编程使用相对路径加载动态库: https://blog.csdn.net/dreamcs/article/details/52138229
每个伟大的产品需要一个伟大的ScrumMaster
摘要
产品负责人和ScrumMaster是两个相互补充的独立敏捷角色。 为了出色地完成工作,产品所有者需要在他们身边强大的ScrumMaster。
不幸的是,我发现通常缺少可以支持产品所有者的ScrumMaster。 有时角色之间会混淆,或者根本没有ScrumMaster。
这篇文章解释了这两个角色之间的区别,产品所有者应该从他们的ScrumMaster中获得什么,以及ScrumMasters从他们中可以期待什么。
产品负责人与ScrumMaster
产品负责人和ScrumMaster是相互补充的两个不同角色。 如果其中一个位置不正确,则另一个会受到影响。 作为产品负责人 ,您应对产品的成功负责-创造一种对用户和客户的工作都非常出色并满足其业务目标的产品。 因此,您可以与用户和客户以及内部利益相关者,开发团队和ScrumMaster进行交互,如下图所示。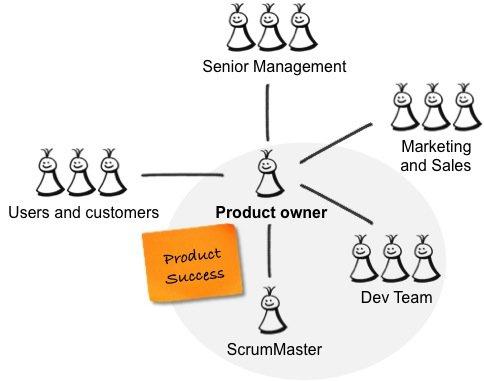
上图中的灰色圆圈描述了由产品所有者,ScrumMaster和跨功能开发团队组成的Scrum团队。
ScrumMaster负责流程的成功 -帮助产品负责人和团队使用正确的流程来创建成功的产品,并促进组织变革和建立敏捷的工作方式。 因此,ScrumMaster与产品所有者和开发团队以及受Scrum影响的高级管理层,人力资源(HR)和业务组合作,如下图所示: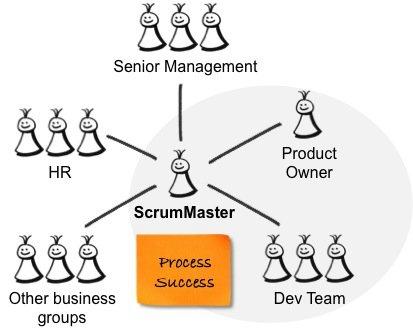
要成功成为产品负责人,需要正确的技能,时间,精力和重点。 扮演ScrumMaster角色也是如此。 将这两个角色(甚至是部分角色)组合在一起不仅非常具有挑战性,而且意味着忽略了某些职责。 如果您是产品所有者,请不要承担ScrumMaster的职责!
产品负责人对ScrumMaster的期望
作为产品所有者,您应该从以下几种方面受益于ScrumMaster的工作。 ScrumMaster应该指导团队,以便团队成员可以构建出色的产品,促进组织变革,以便组织利用Scrum并帮助您完成出色的工作: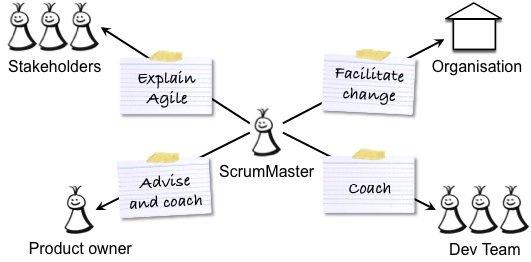
下表详细说明了您应该从ScrumMaster获得的支持:
ScrumMaster支持您作为产品所有者,因此您可以专注于自己的工作-确保创建具有正确用户体验(UX)和正确功能的正确产品。 如果您的ScrumMaster不提供或无法提供此支持,请与个人联系,并找出问题所在。 不要介入并接管ScrumMaster的工作。 如果您没有ScrumMaster,请将上面的列表显示给您的高级管理层赞助商或老板,以解释为什么您需要身边有合格的ScrumMaster。
ScrumMaster应该对产品负责人有什么期望
Tango花了两个时间,ScrumMaster对您作为产品所有者的工作抱有期望,这是公平的。 下图说明了其中的一些:
下表更详细地描述了ScrumMaster的期望:
英文原文: https://henduan.com/1pjvW
收起阅读 »Scrum是一个用于开发和维护复杂产品的框架
Scrum是一个用于开发和维护复杂产品的框架 ,是一个增量的、迭代的开发过程。在这个框架中,整个开发过程由若干个短的迭代周期组成,一个短的迭代周期称为一个Sprint,每个Sprint的建议长度是2到4周(互联网产品研发可以使用1周的Sprint)。
在Scrum中,使用产品Backlog来管理产品的需求,产品backlog是一个按照商业价值排序的需求列表,列表条目的体现形式通常为用户故事。Scrum团队总是先开发对客户具有较高价值的需求。在Sprint中,Scrum团队从产品Backlog中挑选最高优先级的需求进行开发。
挑选的需求在Sprint计划会议上经过讨论、分析和估算得到相应的任务列表,我们称它为Sprint backlog。在每个迭代结束时,Scrum团队将递交潜在可交付的产品增量。 Scrum起源于软件开发项目,但它适用于任何复杂的或是创新性的项目。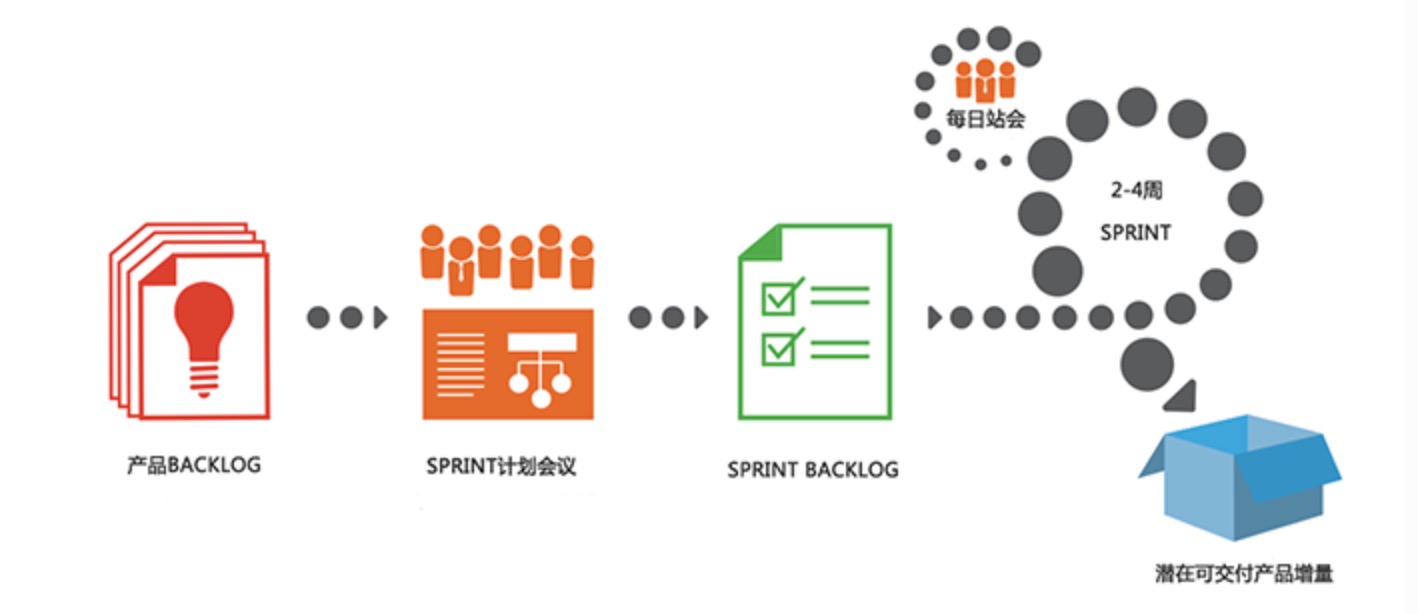
SCRUM框架包括3个角色、3个工件、5个事件、5个价值
3个角色
- 产品负责人(Product Owner)
- Scrum Master
- 开发团队
3个工件
- 产品Backlog(Product Backlog)
- SprintBacklog
- 产品增量(Increment)
5个事件
- Sprint(Sprint本身是一个事件,包括了如下4个事件)
- Sprint计划会议(Sprint Planning Meeting)
- 每日站会(Daily Scrum Meeting)
- Sprint评审会议(Sprint Review Meeting)
- Sprint回顾会议(Sprint Retrospective Meeting)
5个价值
- 承诺 – 愿意对目标做出承诺
- 专注– 把你的心思和能力都用到你承诺的工作上去
- 开放– Scrum 把项目中的一切开放给每个人看
- 尊重– 每个人都有他独特的背景和经验
- 勇气– 有勇气做出承诺,履行承诺,接受别人的尊重
SCRUM理论基础
Scrum以经验性过程控制理论(经验主义)做为理论基础的过程。经验主义主张知识源于经验, 以及基于已知的东西做决定。Scrum 采用迭代、增量的方法来优化可预见性并控制风险。
Scrum 的三大支柱支撑起每个经验性过程控制的实现:透明性、检验和适应。Scrum的三大支柱如下:
第一:透明性(Transparency)
透明度是指,在软件开发过程的各个环节保持高度的可见性,影响交付成果的各个方面对于参与交付的所有人、管理生产结果的人保持透明。管理生产成果的人不仅要能够看到过程的这些方面,而且必须理解他们看到的内容。也就是说,当某个人在检验一个过程,并确信某一个任务已经完成时,这个完成必须等同于他们对完成的定义。
第二:检验(Inspection)
开发过程中的各方面必须做到足够频繁地检验,确保能够及时发现过程中的重大偏差。在确定检验频率时,需要考虑到检验会引起所有过程发生变化。当规定的检验频率超出了过程检验所能容许的程度,那么就会出现问题。幸运的是,软件开发并不会出现这种情况。另一个因素就是检验工作成果人员的技能水平和积极性。
第三:适应(Adaptation)
如果检验人员检验的时候发现过程中的一个或多个方面不满足验收标准,并且最终产品是不合格的,那么便需要对过程或是材料进行调整。调整工作必须尽快实施,以减少进一步的偏差。
Scrum中通过三个活动进行检验和适应:每日例会检验Sprint目标的进展,做出调整,从而优化次日的工作价值;Sprint评审和计划会议检验发布目标的进展,做出调整,从而优化下一个Sprint的工作价值;Sprint回顾会议是用来回顾已经完成的Sprint,并且确定做出什么样的改善可以使接下来的Sprint更加高效、更加令人满意,并且工作更快乐。
全文阅读:https://www.scrumcn.com/agile/scrum-knowledge-library/scrum.html
收起阅读 »了解共享库动态加载
在本文中,我将尝试解释在Linux系统中动态加载共享库的内部工作原理。
这边文章不是一个如何引导,尽管它确实展示了如何编译和调试共享库和可执行文件。为了解动态加载的内部工作方式进行了优化。写这篇文章是为了消除我在该主题上的知识欠缺,以便成为一名更好的程序员。我希望它也能帮助您变得更好。
什么是共享库
库是一个包含编译后的代码和数据的文件。一般来说,库非常有用,因为它们可以缩短编译时间(在编译应用程序时不必编译依赖关系的所有源代码)和模块化开发过程。
静态库链接到已编译的可执行文件(或另一个库)中。编译后,新组件将包含静态库的内容。
共享库在运行时由可执行文件(或其他共享库)加载。这让它们变得更加复杂,通常大家对这个领域可能存在认知障碍,我们将在这篇文章中讨论。
示例设置
为了探索共享库的世界,我们将在本文中使用一个示例。我们将从三个源文件开始:
main.cpp是我们定义的可执行文件的主文件, 它不会做太多, 只是从我们将要编译的随机库random调用一个函数:
$ vi main.cpp
#include "random.h"
int main() {
return get_random_number();
}
头文件random.h将定义一个简单的函数:
$ vi random.h
int get_random_number();
它将在其源文件中提供一个简单的实现, random.cpp:
$ vi random.cpp
#include "random.h"
int get_random_number(void) {
return 4;
}
Note: 所有示例均在Ubuntu 14.04系统上运行
编译共享库
在编译实际库之前,我们将从random.cpp创建一个目标文件:
$ clang++ -o random.o -c random.cpp
通常,一切正常后,构建工具不会打印到标准输出。以下是所有解释的参数:
-o random.o: 将输出文件名定义为random.-c: 不尝试任何链接(只编译)random.cpp: 输入文件
接下来,我们将目标文件编译到共享库中:
$ clang++ -shared -o librandom.so random.o
参数-shared用于指定应该构建共享库的标志。
注意:
librandom.so称为共享库。这不是随心所欲的, 呗调用的共享库应该以lib<name>.so使它们以后正确链接(如我们在下面的链接部分中所见)。
编译和链接动态可执行文件
首先,我们将为main.cpp创建一个共享对象:
$ clang++ -o main.o -c main.cpp
与之前完全相同random.o。
现在,我们将尝试创建一个可执行文件:
$ clang++ -o main main.o
main.o: In function `main':
main.cpp:(.text+0x10): undefined reference to `get_random_number()'
clang: error: linker command failed with exit code 1 (use -v to see invocation)
好吧,看来我们需要告诉clang我们要使用librandom.so:
$ clang++ -o main main.o -lrandom
/usr/bin/ld: cannot find -lrandom
clang: error: linker command failed with exit code 1 (use -v to see invocation)
注意: 我们选择动态链接
librandom.so到main。可以静态地执行此操作-并将random库中的所有符号直接加载到main可执行文件中。
我们告诉编译器我们要使用librandom文件。由于它是动态加载的,为什么我们在编译时需要它?好吧,原因是我们需要确保依赖的库包含可执行文件所需的所有符号。还要注意,我们指定random的是库的名称,而不是librandom.so。还记得关于库文件命名的约定吗?这是使用它的地方。
因此,我们需要让我们clang知道在哪里搜索共享库。我们用-L参数来做到这一点。请注意,由指定的路径-L仅在链接时影响搜索路径,而不会在运行时影响。我们将指定当前目录:
$ clang++ -o main main.o -lrandom -L.
现在它可以运行了,但是:
$ ./main
./main: error while loading shared libraries: librandom.so: cannot open shared object file: No such file or directory
当找不到依赖项时,这是我们得到的错误。这将在我们的应用程序甚至运行一行代码之前发生,因为共享库是在可执行文件中的符号之前加载的。
到这就需要面对如下几个问题:
- main它怎么知道依赖
librandom.so? - main在哪里查找
librandom.so? - 要这么告诉main在当前目录查找
librandom.so?
要回答这些问题,我们将不得不更深入地研究这些文件的结构。
ELF - 可执行和可链接的格式
共享库和可执行文件格式称为ELF(可执行和可链接格式)。如果您查看Wikipedia文章,您会发现它是一团糟,因此我们不会一一列举。总之,ELF文件包含:
- ELF Header
- 文件数据,可能包含:
- 程序头表(段头列表)
- 段头表(列表章节标题)
- 以上两个标题指向的数据
ELF标头指定程序标头表中段的大小和数量,以及节标头表中段的大小和数量。每个这样的表都由固定大小的条目组成(我使用该条目在适当的表中描述段标题或节标题)。条目是标题,并且包含指向该段或节的实际主体位置的指针(文件中的偏移量)。该主体存在于文件的数据部分中。更复杂的是-每个部分都是一个段的一部分,一个段可以包含许多段。
实际上,相同的数据要么作为段的一部分引用,要么作为段的一部分引用,这取决于当前上下文。链接时使用分段,执行时使用分段。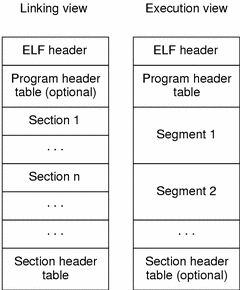
我们将使用readelf命令读取ELF。让我们从查看以下内容的ELF标头开始分析main:
$ readelf -h main
ELF Header:
Magic: 7f 45 4c 46 02 01 01 00 00 00 00 00 00 00 00 00
Class: ELF64
Data: 2's complement, little endian
Version: 1 (current)
OS/ABI: UNIX - System V
ABI Version: 0
Type: EXEC (Executable file)
Machine: Advanced Micro Devices X86-64
Version: 0x1
Entry point address: 0x4005e0
Start of program headers: 64 (bytes into file)
Start of section headers: 4584 (bytes into file)
Flags: 0x0
Size of this header: 64 (bytes)
Size of program headers: 56 (bytes)
Number of program headers: 9
Size of section headers: 64 (bytes)
Number of section headers: 30
Section header string table index: 27
我们可以看到,这是Unix上的ELF文件(64位), 其类型为EXEC,这是一个可执行文件-符合预期。它有9个程序标头(意味着有9个segment)和30个节标头(即section)。
下一步-程序头(program headers):
$ readelf -l main
Elf file type is EXEC (Executable file)
Entry point 0x4005e0
There are 9 program headers, starting at offset 64
Program Headers:
Type Offset VirtAddr PhysAddr
FileSiz MemSiz Flags Align
PHDR 0x0000000000000040 0x0000000000400040 0x0000000000400040
0x00000000000001f8 0x00000000000001f8 R E 8
INTERP 0x0000000000000238 0x0000000000400238 0x0000000000400238
0x000000000000001c 0x000000000000001c R 1
[Requesting program interpreter: /lib64/ld-linux-x86-64.so.2]
LOAD 0x0000000000000000 0x0000000000400000 0x0000000000400000
0x000000000000089c 0x000000000000089c R E 200000
LOAD 0x0000000000000dd0 0x0000000000600dd0 0x0000000000600dd0
0x0000000000000270 0x0000000000000278 RW 200000
DYNAMIC 0x0000000000000de8 0x0000000000600de8 0x0000000000600de8
0x0000000000000210 0x0000000000000210 RW 8
NOTE 0x0000000000000254 0x0000000000400254 0x0000000000400254
0x0000000000000044 0x0000000000000044 R 4
GNU_EH_FRAME 0x0000000000000774 0x0000000000400774 0x0000000000400774
0x0000000000000034 0x0000000000000034 R 4
GNU_STACK 0x0000000000000000 0x0000000000000000 0x0000000000000000
0x0000000000000000 0x0000000000000000 RW 10
GNU_RELRO 0x0000000000000dd0 0x0000000000600dd0 0x0000000000600dd0
0x0000000000000230 0x0000000000000230 R 1
Section to Segment mapping:
Segment Sections...
00
01 .interp
02 .interp .note.ABI-tag .note.gnu.build-id .gnu.hash .dynsym .dynstr .gnu.version .gnu.version_r .rela.dyn .rela.plt .init .plt .text .fini .rodata .eh_frame_hdr .eh_frame
03 .init_array .fini_array .jcr .dynamic .got .got.plt .data .bss
04 .dynamic
05 .note.ABI-tag .note.gnu.build-id
06 .eh_frame_hdr
07
08 .init_array .fini_array .jcr .dynamic .got
同样,我们看到我们有9个程序标头。它们的类型LOAD(有2个),DYNAMIC,NOTE等等。我们也可以看到各段的部分所有权。
最后-节标题(section headers):
$ readelf -S main
There are 30 section headers, starting at offset 0x11e8:
Section Headers:
[Nr] Name Type Address Offset
Size EntSize Flags Link Info Align
[ 0] NULL 0000000000000000 00000000
0000000000000000 0000000000000000 0 0 0
[ 1] .interp PROGBITS 0000000000400238 00000238
000000000000001c 0000000000000000 A 0 0 1
[ 2] .note.ABI-tag NOTE 0000000000400254 00000254
0000000000000020 0000000000000000 A 0 0 4
[..]
[21] .dynamic DYNAMIC 0000000000600de8 00000de8
0000000000000210 0000000000000010 WA 6 0 8
[..]
[28] .symtab SYMTAB 0000000000000000 00001968
0000000000000618 0000000000000018 29 45 8
[29] .strtab STRTAB 0000000000000000 00001f80
000000000000023d 0000000000000000 0 0 1
Key to Flags:
W (write), A (alloc), X (execute), M (merge), S (strings), l (large)
I (info), L (link order), G (group), T (TLS), E (exclude), x (unknown)
O (extra OS processing required) o (OS specific), p (processor specific)
为了简洁起见,我对此进行了修剪。我们看到列出的30个部分带有各种名称(例如.note.ABI-tag)和类型(例如SYMTAB)。
您现在可能会感到困惑, 不用担心一般不会考这方面的东西。在他们的:因为我们感兴趣的是这个文件的特定部分,我解释这个程序头表,ELF文件可以有(和共享特别库必须具有)段头一个描述段型的PT_DYNAMIC。该部分拥有一个名为的部分.dynamic,其中包含有用的信息以了解动态依赖性。
直接依赖
我们可以使用readelf实用工具来进一步探索.dynamic可执行文件的部分。
特别是,本节包含我们ELF文件的所有动态依赖项。我们仅将其指定librandom.so为依赖项,因此我们希望列出main的依赖项:
$ readelf -d main | grep NEEDED
0x0000000000000001 (NEEDED) Shared library: [librandom.so]
0x0000000000000001 (NEEDED) Shared library: [libstdc++.so.6]
0x0000000000000001 (NEEDED) Shared library: [libm.so.6]
0x0000000000000001 (NEEDED) Shared library: [libgcc_s.so.1]
0x0000000000000001 (NEEDED) Shared library: [libc.so.6]
objdump可执行文件可以提供类似的结果。在这种情况下,例如:objdump -p librandom.so | grep NEEDED将打印非常相似的输出。
我们可以看到librandom.so我们指定的,但是我们还得到了四个我们没有想到的额外依赖项。这些依赖性似乎出现在所有已编译的共享库中。这些是什么呢?
libstdc++: 标准C++库libm: 包含基本数学函数的库libgcc_s: GCC(GNU编译器集合)运行时库libc: C库:它定义了系统调用和其他基础设施如库open,malloc,printf,exit等。
好的, 我们已经知道main依赖于librandom.so, 那么,为什么在运行时main找不到librandom.so ?
运行时搜索路径
ldd是一个工具,使我们可以查看递归共享库的依赖关系。这意味着我们可以看到程序在运行时需要的所有共享库的完整列表。这也让我们看到了在那里这些依赖所在。让我们继续运行main,看看会发生什么:
$ ldd main
linux-vdso.so.1 => (0x00007fff889bd000)
librandom.so => not found
libstdc++.so.6 => /usr/lib/x86_64-linux-gnu/libstdc++.so.6 (0x00007f07c55c5000)
libm.so.6 => /lib/x86_64-linux-gnu/libm.so.6 (0x00007f07c52bf000)
libgcc_s.so.1 => /lib/x86_64-linux-gnu/libgcc_s.so.1 (0x00007f07c50a9000)
libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007f07c4ce4000)
/lib64/ld-linux-x86-64.so.2 (0x00007f07c58c9000)
如上,我们看到了文件librandom.so依赖的动态链接库文件,但是提示是not found。
我们还可以看到,我们还有两个附加的库(vdso和ld-linux-x86-64)。它们是间接依赖关系, 更重要的是,我们看到ldd报告了库的位置。比如libstdc++ldd报告其位置为/usr/lib/x86_64-linux-gnu/libstdc++.so.6, 这是怎么知道的呢?
我们的依赖项中的每个共享库都按顺序在以下位置进行搜索:
- 可执行文件
rpath中列出的目录; LD_LIBRARY_PATH环境变量中的目录,该变量包含以冒号分隔的目录列表(例如:/path/to/libdir:/another/path);- 可执行文件
runpath中列出的目录; - 文件
/etc/ld.so.conf中包含的文件目录列表; - 默认系统库-通常为
/lib和/usr/lib(设置-z nodefaultlib参数编译时可跳过)
修复我们的可执行文件
好的, 我们验证了librandom.so是列出的依赖项,但找不到。我们知道在哪里搜索依赖项,ldd再次使用以下命令,确保目录实际上不在搜索路径中:
$ LD_DEBUG=libs ldd main
[..]
3650: find library=librandom.so [0]; searching
3650: search cache=/etc/ld.so.cache
3650: search path=/lib/x86_64-linux-gnu/tls/x86_64:/lib/x86_64-linux-gnu/tls:/lib/x86_64-linux-gnu/x86_64:/lib/x86_64-linux-gnu:/usr/lib/x86_64-linux-gnu/tls/x86_64:/usr/lib/x86_64-linux-gnu/tls:/usr/lib/x86_64-linux-gnu/x86_64:/usr/lib/x86_64-linux-gnu:/lib/tls/x86_64:/lib/tls:/lib/x86_64:/lib:/usr/lib/tls/x86_64:/usr/lib/tls:/usr/lib/x86_64:/usr/lib (system search path)
3650: trying file=/lib/x86_64-linux-gnu/tls/x86_64/librandom.so
3650: trying file=/lib/x86_64-linux-gnu/tls/librandom.so
3650: trying file=/lib/x86_64-linux-gnu/x86_64/librandom.so
3650: trying file=/lib/x86_64-linux-gnu/librandom.so
3650: trying file=/usr/lib/x86_64-linux-gnu/tls/x86_64/librandom.so
3650: trying file=/usr/lib/x86_64-linux-gnu/tls/librandom.so
3650: trying file=/usr/lib/x86_64-linux-gnu/x86_64/librandom.so
3650: trying file=/usr/lib/x86_64-linux-gnu/librandom.so
3650: trying file=/lib/tls/x86_64/librandom.so
3650: trying file=/lib/tls/librandom.so
3650: trying file=/lib/x86_64/librandom.so
3650: trying file=/lib/librandom.so
3650: trying file=/usr/lib/tls/x86_64/librandom.so
3650: trying file=/usr/lib/tls/librandom.so
3650: trying file=/usr/lib/x86_64/librandom.so
3650: trying file=/usr/lib/librandom.so
[..]
我剪裁了输出。难怪找不到我们的共享库-所在目录librandom.so不在搜索路径中!解决此问题的最特别的方法是使用LD_LIBRARY_PATH:
$ LD_LIBRARY_PATH=. ./main
它可以工作,但不是很轻便。我们不想每次运行程序时都指定lib目录。更好的方法是将依赖项放入文件中, 这就需要设置rpath和runpath。
rpath和runpath
rpath并且runpath是我们的运行时搜索路径“清单”中最复杂的项目。可执行文件或共享库的rpath和runpath在.dynamic我们前面介绍的部分中是可选条目。它们都是要搜索的目录列表。
rpath的类型为
DT_RPATH, runpath的类型为DT_RUNPATH。
rpath和runpath之间的唯一区别是搜索它们的顺序。具体来说,它们与LD_LIBRARY_PATH的顺序: rpath在LD_LIBRARY_PATH之前搜索,而runpath在LD_LIBRARY_PATH之后搜索。这意味着rpath不能用环境变量动态改变,而runpath可以。
设置rpath,看看是否可以让main工作:
$ clang++ -o main main.o -lrandom -L. -Wl,-rpath,.
参数-Wl与-rpath逗号分隔将.标志传递给链接器。要进行设置runpath,我们还必须通过--enable-new-dtags参数设置(-Wl,--enable-new-dtags,-rpath,.)。让我们检查一下结果:
$ readelf -d main | grep path
0x000000000000000f (RPATH) Library rpath: [.]
$ ./main
可执行文件可以运行,但是已将其添加.到rpath当前的工作目录中。这意味着它将无法从其他目录运行:
$ cd /tmp
$ ~/code/shared_lib_demo/main
/home/nurdok/code/shared_lib_demo/main: error while loading shared libraries: librandom.so: cannot open shared object file: No such file or directory
我们有几种解决方法。最简单的方法是复制librandom.so到搜索路径中的目录(例如/lib)。显然,更复杂的方法是我们要执行的操作-指定rpath相对于可执行文件的位置。
$ORIGIN
rpath和runpath中的路径可以是相对于当前工作目录的绝对路径(例如/path/to/my/libs/),但它们也可以是相对于可执行文件的。这是通过使用rpath定义中的$ORIGIN变量来实现的:
$ clang++ -o main main.o -lrandom -L. -Wl,-rpath,"\$ORIGIN"
注意,
$ORIGIN不是一个环境变量。如果你设置ORIGIN=/path,它将不起作用。它总是放置可执行文件的目录。
请注意,我们需要对美元符号进行转义(或使用单引号),以便我们的shell不会尝试对其进行扩展。结果是main可以在每个目录下工作并librandom.so正确找到:
$ ./main
$ cd /tmp
$ ~/code/shared_lib_demo/main
让我们使用我们的工具包来确保:
$ readelf -d main | grep path
0x000000000000000f (RPATH) Library rpath: [$ORIGIN]
$ ldd main
linux-vdso.so.1 => (0x00007ffe13dfe000)
librandom.so => /home/nurdok/code/shared_lib_demo/./librandom.so (0x00007fbd0ce06000)
[..]
运行时搜索目录之安全性
如果您从命令行更改了Linux用户密码,则可能使用了该passwd实用程序:
$ passwd
Changing password for nurdok.
(current) UNIX password:
Enter new UNIX password:
Retype new UNIX password:
passwd: password updated successfully
密码被哈希之后存储在受root保护的文件/etc/shadow中,所以问题来了,非root用户如何更改此文件?
答案是passwd程序设置了setuid位,你可以通过ls看到:
$ ls -l `which passwd`
-rwsr-xr-x 1 root root 39104 2009-12-06 05:35 /usr/bin/passwd
# ^--- This means that the "setuid" bit is set for user execution.
这是s(该行的第四个字符)。设置了此权限位的所有程序均以该程序的所有者身份运行。在此示例中,用户是root(该行的第三个单词)。
这与共享库有什么关系? 我们举个例子.
现在我们在libs目录下有了librandom.so,并且我们将main程序的rpath设置为$ORIGIN/libs:
$ ls
libs main
$ ls libs
librandom.so
$ readelf -d main | grep path
0x000000000000000f (RPATH) Library rpath: [$ORIGIN/libs]
正常我们是可以运行main的,但是我们给它设置setuid位,并设置属主为root:
$ sudo chown root main
$ sudo chmod a+s main
$ ./main
./main: error while loading shared libraries: librandom.so: cannot open shared object file: No such file or directory
好吧,rpath行不通。让我们尝试设置LD_LIBRARY_PATH:
$ LD_LIBRARY_PATH=./libs ./main
./main: error while loading shared libraries: librandom.so: cannot open shared object file: No such file or directory
还是不行,这里发生了什么?
出于安全考虑,使用提升的权限运行可执行文件(例如,当setuid,setgid特殊功能等)的搜索路径不同于正常:LD_LIBRARY_PATH被忽略,以及任何路径rpath或runpath包含$ORIGIN。
原因是使用这些搜索路径允许利用提升的特权可执行文件以as身份运行root。有关此漏洞利用的详细信息,请参见此处。
基本上,它允许您使提升特权的可执行文件加载您自己的库,该库将以root用户(或其他用户)身份运行。以root身份运行自己的代码几乎可以使您完全控制所使用的计算机。
如果您的可执行文件需要提升的特权,则需要在绝对路径中指定依赖项,或将其放置在默认位置(例如/lib)。
这里要注意的重要行为是,对于此类应用程序,ldd我们必须面对:
$ ldd main
linux-vdso.so.1 => (0x00007ffc2afd2000)
librandom.so => /home/nurdok/code/shared_lib_demo/libs/librandom.so (0x00007f1f666ca000)
libstdc++.so.6 => /usr/lib/x86_64-linux-gnu/libstdc++.so.6 (0x00007f1f663c6000)
libm.so.6 => /lib/x86_64-linux-gnu/libm.so.6 (0x00007f1f660c0000)
libgcc_s.so.1 => /lib/x86_64-linux-gnu/libgcc_s.so.1 (0x00007f1f65eaa000)
libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007f1f65ae5000)
/lib64/ld-linux-x86-64.so.2 (0x00007f1f668cc000)
ldd不在乎setuid,它会$ORIGIN在搜索我们的依赖项时扩展。在调试对setuid应用程序的依赖项时,这可能是一个陷阱。
调试备忘单
如果在运行可执行文件时遇到此错误:
$ ./main
./main: error while loading shared libraries: librandom.so: cannot open shared object file: No such file or directory
您可以尝试执行以下操作:
- 找出缺少哪些依赖项
ldd <executable>; - 如果您不能识别它们,则可以通过运行来检查它们是否是直接依赖项
readelf -d <executable> | grep NEEDED; - 确保依赖项确实存在。也许您忘了编译它们或将它们移动到libs目录中?
- 找出使用来搜索依赖项的位置
LD_DEBUG=libs ldd <executable>; - 如果您需要在搜索中添加目录:
临时:将目录添加到LD_LIBRARY_PATH环境变量
嵌入文件中:将目录添加到可执行文件或共享库的目录中,rpath或runpath通过传递-Wl,-rpath,<dir>(for rpath)或-Wl,--enable-new-dtags,-rpath,<dir>(for runpath)。使用$ORIGIN相对于可执行文件的路径。
- 如果ldd显示没有依赖项丢失,请查看您的应用程序是否具有提升的特权。如果是这样,ldd可能会撒谎。请参阅上面的安全问题。
原文: https://amir.rachum.com/blog/2016/09/17/shared-libraries/#debugging-cheat-sheet
参考:
https://en.wikipedia.org/wiki/Executable_and_Linkable_Format
https://docs.oracle.com/cd/E23824_01/html/819-0690/chapter6-42444.html
https://www.gnu.org/software/libc/
http://tldp.org/HOWTO/Program-Library-HOWTO/shared-libraries.html
http://unix.stackexchange.com/questions/22926/where-do-executables-look-for-shared-objects-at-runtime
http://www.sco.com/developers/gabi/latest/ch5.pheader.html
https://greek0.net/elf.html
https://en.wikipedia.org/wiki/Rpath
http://blog.lxgcc.net/?tag=dt_rpath
https://cs.nyu.edu/~xiaojian/bookmark/linux/ld_so%20%20Dynamic-Link%20Library%20support.htm
http://unix.stackexchange.com/questions/101467/how-does-the-passwd-command-gain-root-user-permissions
http://nairobi-embedded.org/004_elf_format.html
什么是Serverless?
1. 无服务器(Serverless)计算是什么
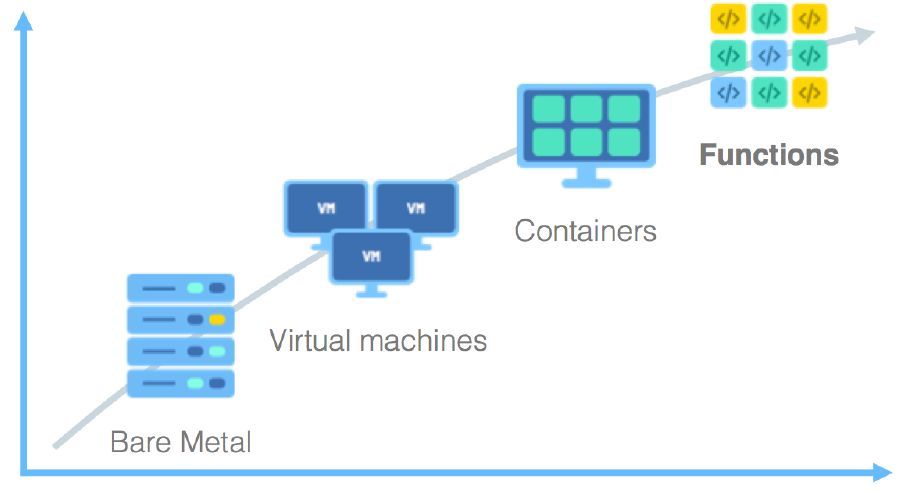
云计算涌现出很多改变传统IT架构和运维方式的新技术,比如虚拟机、容器、微服务,无论这些技术应用在哪些场景,降低成本、提升效率是云服务永恒的主题。
过去十年来,我们已经把应用和环境中很多通用的部分变成了服务。Serverless的出现,带来了跨越式变革。Serverless把主机管理、操作系统管理、资源分配、扩容,甚至是应用逻辑的全部组件都外包出去,把它们看作某种形式的商品——厂商提供服务,我们掏钱购买。
过去是“构建一个框架运行在一台服务器上,对多个事件进行响应”,Serverless则变为“构建或使用一个微服务或微功能来响应一个事件”,做到当访问时,调入相关资源开始运行,运行完成后,卸载所有开销,真正做到按需按次计费。这是云计算向纵深发展的一种自然而然的过程。
Serverless是一种构建和管理基于微服务架构的完整流程,允许你在服务部署级别而不是服务器部署级别来管理你的应用部署。它与传统架构的不同之处在于,完全由第三方管理,由事件触发,存在于无状态(Stateless)、暂存(可能只存在于一次调用的过程中)计算容器内。构建无服务器应用程序意味着开发者可以专注在产品代码上,而无须管理和操作云端或本地的服务器或运行时。Serverless真正做到了部署应用无需涉及基础设施的建设,自动构建、部署和启动服务。
国内外的各大云厂商 Amazon、微软、Google、IBM、阿里云、腾讯云、华为云相继推出Serverless产品,Serverless也从概念、愿景逐步走向落地,在各企业、公司应用开来。
2. 理解Serverless技术 - FaaS和BaaS
Serverless由开发者实现的服务端逻辑运行在无状态的计算容器中,它由事件触发, 完全被第三方管理,其业务层面的状态则被开发者使用的数据库和存储资源所记录。Serverless涵盖了很多技术,分为两类:FaaS和BaaS。
2.1 FaaS(Function as a Service,函数即服务)
FaaS意在无须自行管理服务器系统或自己的服务器应用程序,即可直接运行后端代码。其中所指的服务器应用程序,是该技术与容器和PaaS(平台即服务)等其他现代化架构最大的差异。
FaaS可以取代一些服务处理服务器(可能是物理计算机,但绝对需要运行某种应用程序),这样不仅不需要自行供应服务器,也不需要全时运行应用程序。
FaaS产品不要求必须使用特定框架或库进行开发。在语言和环境方面,FaaS函数就是常规的应用程序。例如AWS Lambda的函数可以通过Javascript、Python以及任何JVM语言(Java、Clojure、Scala)等实现。然而Lambda函数也可以执行任何捆绑有所需部署构件的进程,因此可以使用任何语言,只要能编译为Unix进程即可。FaaS函数在架构方面确实存在一定的局限,尤其是在状态和执行时间方面。
在迁往FaaS的过程中,唯一需要修改的代码是“主方法/启动”代码,其中可能需要删除顶级消息处理程序的相关代码(“消息监听器接口”的实现),但这可能只需要更改方法签名即可。在FaaS的世界中,代码的其余所有部分(例如向数据库执行写入的代码)无须任何变化。
相比传统系统,部署方法会有较大变化 – 将代码上传至FaaS供应商,其他事情均可由供应商完成。目前这种方式通常意味着需要上传代码的全新定义(例如上传zip或JAR文件),随后调用一个专有API发起更新过程。
FaaS中的函数可以通过供应商定义的事件类型触发。对于亚马逊AWS,此类触发事件可以包括S3(文件)更新、时间(计划任务),以及加入消息总线的消息(例如Kinesis)。通常你的函数需要通过参数指定自己需要绑定到的事件源。
大部分供应商还允许函数作为对传入Http请求的响应来触发,通常这类请求来自某种该类型的API网关(例如AWS API网关、Webtask)。
2.2 BaaS(Backend as a Service,后端即服务)
BaaS(Backend as a Service,后端即服务)是指我们不再编写或管理所有服务端组件,可以使用领域通用的远程组件(而不是进程内的库)来提供服务。理解BaaS,需要搞清楚它与PaaS的区别。
首先BaaS并非PaaS,它们的区别在于:PaaS需要参与应用的生命周期管理,BaaS则仅仅提供应用依赖的第三方服务。典型的PaaS平台需要提供手段让开发者部署和配置应用,例如自动将应用部署到Tomcat容器中,并管理应用的生命周期。BaaS不包含这些内容,BaaS只以API的方式提供应用依赖的后端服务,例如数据库和对象存储。BaaS可以是公共云服务商提供的,也可以是第三方厂商提供的。其次从功能上讲,BaaS可以看作PaaS的一个子集,即提供第三方依赖组件的部分。
BaaS服务还允许我们依赖其他人已经实现的应用逻辑。对于这点,认证就是一个很好的例子。很多应用都要自己编写实现注册、登录、密码管理等逻辑的代码,而对于不同的应用这些代码往往大同小异。完全可以把这些重复性的工作提取出来,再做成外部服务,而这正是Auth0和Amazon Cognito等产品的目标。它们能实现全面的认证和用户管理,开发团队再也不用自己编写或者管理实现这些功能的代码。
3. 无服务器(Serverless)计算如何工作?
与使用虚拟机或一些底层的技术来部署和管理应用程序相比,无服务器计算提供了一种更高级别的抽象。因为它们有不同的抽象和“触发器”的集合。
拿计算来讲,这种抽象有一个特定函数和抽象的触发器,它通常是一个事件。以数据库为例,这种抽象也许是一个表,而触发器相当于表的查询或搜索,或者通过在表中做一些事情而生成的事件。
比如一款手机游戏,允许用户在不同的平台上为全球顶级玩家使用高分数表。当请求此信息时,请求从应用程序到API接口。API接口或许会触发AWS的Lambda函数,或者无服务器函数,这些函数再从数据库表中获取到数据流,返回包含前五名分数的一定格式的数据。
一旦构建完成,应用程序的功能就可以在基于移动和基于 Web 的游戏版本中重用。
这跟设置服务器不同,不是必须要有Amazon EC2实例或服务器,然后等待请求。环境由事件触发,而响应事件所需的逻辑只在响应时执行。这意味着,运行函数的资源只有在函数运行时被创建,产生一种非常高效的方法来构建应用程序。
4. 无服务器(Serverless)适用于哪些场景?
在现阶段,Serverless主要应用在以下几个场景。首先在Web及移动端服务中,可以整合API网关和Serverles服务构建Web及移动后端,帮助开发者构建可弹性扩展、高可用的移动或 Web后端应用服务。在IoT场景下可高效的处理实时流数据,由设备产生海量的实时信息流数据,通过Serverles服务分类处理并写入后端处理。另外在实时媒体资讯内容处理场景里,用户上传的音视频到对象存储OBS,通过上传事件触发多个函数,分别完成高清转码、音频转码等功能,满足用户对实时性和并发能力的高要求。无服务器计算还适合于任何事件驱动的各种不同的用例,这包括物联网,移动应用,基于网络的应用程序和聊天机器人等。这里简单说两个场景,方便大家思考。
4.1 场景一:应用负载有显著的波峰波谷
Serverless 应用成功与否的评判标准并不是公司规模的大小,而是其业务背后的具体技术问题,比如业务波峰波谷明显,如何实现削峰填谷。一个公司的业务负载具有波峰波谷时,机器资源要按照峰值需求预估;而在波谷时期机器利用率则明显下降,因为不能进行资源复用而导致浪费。
业界普遍共识是,当自有机器的利用率小于 30%,使用 Serverless 后会有显著的效率提升。对于云服务厂商,在具备了足够多的用户之后,各种波峰波谷叠加后平稳化,聚合之后资源复用性更高。比如,外卖企业负载高峰是在用餐时期,安防行业的负载高峰则是夜间,这是受各个企业业务定位所限的;而对于一个成熟的云服务厂商,如果其平台足够大,用户足够多,是不应该有明显的波峰波谷现象的。
4.2 场景二:典型用例 - 基于事件的数据处理
视频处理的后端系统,常见功能需求如下:视频转码、抽取数据、人脸识别等,这些均为通用计算任务,可由函数计算执行。
开发者需要自己写出实现逻辑,再将任务按照控制流连接起来,每个任务的具体执行由云厂商来负责。如此,开发变得更便捷,并且构建的系统天然高可用、实时弹性伸缩,用户不需要关心机器层面问题。
5. Serverless的问题
对于企业来说,支持Serverless计算的平台可以节省大量时间和成本,同时可以释放员工,让开发者得以开展更有价值的工作,而不是管理基础设施。另一方面可以提高敏捷度,更快速地推出新应用和新服务,进而提高客户满意度。但是Serverless不是完美的,它也存在一些问题,需要慎重应用在生产环境。
5.1 不适合长时间运行应用
Serverless 在请求到来时才运行。这意味着,当应用不运行的时候就会进入 “休眠状态”,下次当请求来临时,应用将会需要一个启动时间,即冷启动时间。如果你的应用需要一直长期不间断的运行、处理大量的请求,那么你可能就不适合采用 Serverless 架构。如果你通过 CRON 的方式或者 CloudWatch 来定期唤醒应用,又会比较消耗资源。这就需要我们对它做优化,如果频繁调用,这个资源将会常驻内存,第一次冷启之后,就可以一直服务,直到一段时间内没有新的调用请求进来,则会转入“休眠”状态,甚至被回收,从而不消耗任何资源。
5.2 完全依赖于第三方服务
当你所在的企业云环境已经有大量的基础设施的时候,Serverless 对于你来说,并不是一个好东西。当我们采用某云服务厂商的 Serverless 架构时,我们就和该服务供应商绑定了,那么我们再将服务迁到别的云服务商上就没有那么容易了。
我们需要修改一下系列的底层代码,能采取的应对方案,便是建立隔离层。这意味着,在设计应用的时候,就需要隔离 API 网关、隔离数据库层,考虑到市面上还没有成熟的 ORM 工具,让你既支持Firebase,又支持 DynamoDB等等。这些也将带给我们一些额外的成本,可能带来的问题会比解决的问题多。
5.3 缺乏调试和开发工具
当我使用 Serverless Framework 的时候,遇到了这样的问题:缺乏调试和开发工具。后来,我发现了 serverless-offline、dynamodb-local 等一系列插件之后,问题有一些改善。然而,对于日志系统来说,这仍然是一个艰巨的挑战。
每次你调试的时候,你需要一遍又一遍地上传代码。而每次上传的时候,你就好像是在部署服务器,并不能总是快速地定位出问题在哪。后来,找了一个类似于 log4j 这样的可以分级别记录日志的 Node.js 库 winston。它可以支持 error、warn、info、verbose、debug、silly 六个不同级别的日志,再结合大数据进行日志分析过滤,才能快速定位问题。
5.4 构建复杂
Serverless 很便宜,但是这并不意味着它很简单。AWS Lambda的 CloudFormation配置是如此的复杂,并且难以阅读及编写(JSON 格式),虽然CloudFomation提供了Template模板,但想要使用它的话,需要创建一个Stack,在Stack中指定你要使用的Template,然后aws才会按照Template中的定义来创建及初始化资源。
而Serverless Framework的配置更加简单,采用的是 YAML 格式。在部署的时候,Serverless Framework 会根据我们的配置生成 CloudFormation 配置。然而这也并非是一个真正用于生产的配置,真实的应用场景远远比这复杂。
6. 总结
云计算经过这么多年的发展,逐渐进化到用户仅需关注业务和所需的资源。比如,通过K8S这类编排工具,用户只要关注自己的计算和需要的资源(CPU、内存等)就行了,不需要操心到机器这一层。
Serverless架构让人们不再操心运行所需的资源,只需关注自己的业务逻辑,并且为实际消耗的资源付费。可以说,随着Serverless架构的兴起,真正的云计算时代才算到来了。
任何新概念新技术的落地,本质上都是要和具体业务去结合,去真正解决具体问题。虽然Serverless很多地方不成熟,亟待完善。不过Serverless自身的优越特性,对于开发者来说,吸引力是巨大的。相信随着技术的飞速发展,Serverless在未来还有无限可能!
作者介绍:孙杰 北京中油瑞飞资深架构师,著名技术博客博主。
收起阅读 »Go模块代理大全
1.GoProxy
官网地址: https://www.goproxy.io/zh/
Bash (Linux or macOS):
# 配置 GOPROXY 环境变量
export GOPROXY=https://goproxy.io,direct
# 还可以设置不走 proxy 的私有仓库或组,多个用逗号相隔(可选)
export GOPRIVATE=git.mycompany.com,github.com/my/private
PowerShell (Windows)
# 配置 GOPROXY 环境变量
$env:GOPROXY = "https://goproxy.io,direct"
# 还可以设置不走 proxy 的私有仓库或组,多个用逗号相隔(可选)
$env:GOPRIVATE = "git.mycompany.com,github.com/my/private"
设置完上面几个环境变量后,您的 go 命令将从公共代理镜像中快速拉取您所需的依赖代码了。或者,还可以根据文档进行设置使其长期生效。如果您使用的是老版本的 Go(< 1.13), 我们建议您升级为最新稳定版本。
2.七牛GoProxy中国
官网地址:https://goproxy.cn/
Go 1.13 及以上(推荐),打开你的终端并执行
$ go env -w GO111MODULE=on
$ go env -w GOPROXY=https://goproxy.cn,direct
macOS 或 Linux
$ export GO111MODULE=on
$ export GOPROXY=https://goproxy.cn
或者
$ echo "export GO111MODULE=on" >> ~/.profile
$ echo "export GOPROXY=https://goproxy.cn" >> ~/.profile
$ source ~/.profile
Windows, 打开你的 PowerShell 并执行
C:\> $env:GO111MODULE = "on"
C:\> $env:GOPROXY = "https://goproxy.cn"
或者
1. 打开“开始”并搜索“env”
2. 选择“编辑系统环境变量”
3. 点击“环境变量…”按钮
4. 在“<你的用户名> 的用户变量”章节下(上半部分)
5. 点击“新建…”按钮
6. 选择“变量名”输入框并输入“GO111MODULE”
7. 选择“变量值”输入框并输入“on”
8. 点击“确定”按钮
9. 点击“新建…”按钮
10. 选择“变量名”输入框并输入“GOPROXY”
11. 选择“变量值”输入框并输入“https://goproxy.cn”
12. 点击“确定”按钮
3.百度Go Module代理
官网地址: https://goproxy.baidu.com/
简介:go module公共代理仓库,代理并缓存go模块。你可以利用该代理来避免DNS污染导致的模块拉取缓慢或失败的问题,加速你的构建
1.使用go1.11以上版本并开启go module机制
export GOPROXY=https://goproxy.baidu.com/ ## 配置GOPROXY环境变量
2.使用go1.13以上版本
go env -w GONOPROXY=\*\*.baidu.com\*\* ## 配置GONOPROXY环境变量,所有百度内代码,不走代理
go env -w GONOSUMDB=\* ## 配置GONOSUMDB,暂不支持sumdb索引
go env -w GOPROXY=https://goproxy.baidu.com ## 配置GOPROXY,可以下载墙外代码
4.阿里云Go Module代理
官网:http://mirrors.aliyun.com/goproxy/
1.使用go1.11以上版本并开启go module机制
2.导出GOPROXY环境变量
export GOPROXY=https://mirrors.aliyun.com/goproxy/
官网安装包国内下载地址
- Go中文社区:https://studygolang.com/dl
- Gomirrors: https://gomirrors.org/
Zookeeper新手指南
目标
今天,我们将开始迈向Apache ZooKeeper的新旅程。在这个ZooKeeper教程中,我们将看到Apache ZooKeeper的含义以及ZooKeeper的流行度。此外,我们将了解ZooKeeper 的功能,优点,应用和用例。此外,我们将讨论不同的术语,如ZooKeeper Client,ZooKeeper Cluster,ZooKeeper WebUI。除此之外,Apache ZooKeeper教程将为使用ZooKeeper的原因提供答案。此外,我们将看到使用ZooKeeper的公司。最后,我们将看到Apache ZooKeeper架构。
由于ZooKeeper本质上是分布式的,因此在进一步研究之前,了解分布式应用程序的一两件事非常重要。因此,首先,我们将看到ZooKeeper讨论,快速介绍分布式应用程序。
那么,让我们开始Apache ZooKeeper教程。
什么是分布式应用程序?
为了以快速有效的方式完成特定任务,分布式应用程序可以在给定时间(同时)在网络中的多个系统上运行。它们可以通过中间协调来实现。此外,我们可以说,通过使用所涉及的所有系统的计算能力,复杂且耗时的任务(需要数小时才能完成非分布式应用程序(在单个系统中运行))可以在几分钟内通过帮助完成分布式应用程序。
此外,通过将分布式应用程序配置为在更多系统上运行,可以进一步减少完成任务的时间。有一个集群,它基本上是一组运行分布式应用程序的系统。在集群中有机器在运行,那些在集群中运行的机器就是我们所说的节点。
通常,服务器和客户端应用程序是分布式应用程序的两个部分。定义两者:
服务器端应用
具有通用接口的分布式应用程序就是我们所说的服务器端应用程序。基本上,它确保客户端可以连接到群集中的任何服务器并获取相同的结果。
客户端应用
有助于与分布式应用程序交互的工具就是我们所说的客户端应用程序。
分布式应用的好处
a.可靠性
如果一个或几个系统发生故障,则不会使整个系统失效。
b.可伸缩性
通过添加更多的机器,只需对应用程序的配置进行少量更改,而无需停机,就可以根据需要提高性能。
c.透明度
这仅仅意味着它隐藏了系统的复杂性。而且,它显示自己是一个单独的实体/应用程序。
分布式应用程序的挑战
1.竞争条件
有时有两个或更多的机器试图执行一个特定的任务,即使当任务实际上只需要在任何给定的时间由一台机器来完成。
2.死锁
为了无限期地完成,两个或多个操作等待彼此。
3.不一致
这意味着数据部分失效。
什么是ZooKeeper?
我们称之为ZooKeeper的分布式协调服务也有助于管理大量主机。由于特别是在分布式环境中管理和协调服务是一个复杂的过程,因此ZooKeeper由于其简单的架构和API而解决了这个问题。ZooKeeper是最好的,不用担心应用程序的分布式特性,它允许开发人员专注于核心应用程序逻辑。
最初,为了以简单而强大的方式访问应用程序,ZooKeeper框架最初是在“Yahoo!”上构建的。但在此之后,为了组织Hadoop,HBase和其他分布式框架所使用的服务,Apache ZooKeeper成为了标准。例如,要跟踪分布式数据的状态,Apache HBase使用ZooKeeper。
此外,它们还可以轻松支持大型Hadoop集群。为了检索信息,每个客户机与其中一个服务器通信。但是,在过去,大多数工作都需要在实现分布式应用程序时修复错误。虽然我们可以说,实现中的这些各种困难是创建ZooKeeper背后的主要原因。因为它简明扼要地关注整个集群的同步和协调。
Zookeeper受众
那些希望通过使用ZooKeeper框架在大数据分析领域开展事业的专业人士可以参考这个Zookeeper序列文章。因为这个Apache ZooKeeper序列教程文章将详细介绍如何使用ZooKeeper创建分布式集群。
Zookeeper运行先决条件
虽然,在继续使用这个ZooKeeper教程之前,必须对Java有一个很好的理解,因为它的服务器运行在JVM,分布式进程以及Linux环境中。
Zookeeper的功能
有一些最好的Apache ZooKeeper功能,这使它从人群中脱颖而出:
简单
在共享的分层命名空间的帮助下,它进行协调。
可靠性
即使多个节点发生故障,系统也会继续运行。
速度
在“读取”更常见的情况下,它以10:1的比例运行。
可扩展性
通过部署更多集群节点,可以提高性能。
ZooKeeper教程设计
下面,我们将讨论Apache ZooKeeper的一些设计目标: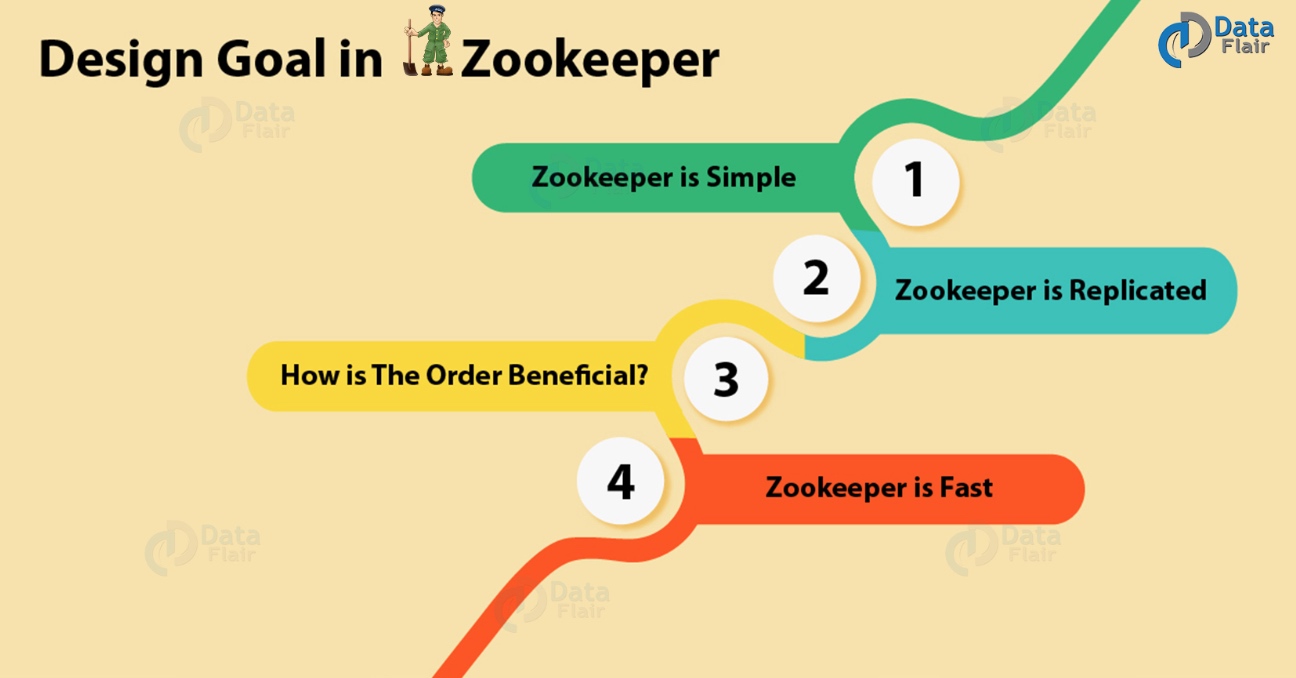
a. Zookeeper是简单的
在使用ZooKeeper时,所有分布式进程都可以相互协调。这种协调可以通过共享的分层命名空间实现。但是,它的组织方式与标准文件系统相同。这里的命名空间由数据寄存器组成,我们称之为znodes,用ZooKeeper的说法。但是,这些与文件和目录相同。此外,ZooKeeper数据保留在内存中,因为它实现了高吞吐量和低延迟数量。
b. Zookeeper支持复制
Apache ZooKeeper本身旨在通过一组称为集合的主机进行复制,就像它协调的分布式进程一样。
c. 如何让Zookeeper顺序一致性更有效?
为了实现更高级别的抽象(同步原语,后续操作),需要使用顺序一致性。
d. Zookeepr很快
特别是,在“读取占优势”的工作负载中,ZooKeeper的工作速度非常快。
Apache ZooKeeper架构
在这个Apache ZooKeeper教程的下面,给出了ZooKeeper架构的几个组成部分,例如:
- 服务器端应用程序:通过通用接口,这些应用程序便于与客户端应用程序进
- 客户端应用程序:有几种工具可以帮助与分布式应用程序进行交互。
- ZooKeeper节点:这些是集群运行的系统。
- Znode:通过集群中的任何节点,我们都可以更新或修改Znode。
我们可以通过一组机器轻松地通过Hadoop ZooKeeper的架构复制ZooKeeper服务。但是,每个都维护一个内存数据树的映像以及事务日志。此外,客户端应用程序联系到单个服务器并且还建立TCP链接。因此,通过他们,他们发送请求,接收回复,观看事件等等。
为什么选择Apache ZooKeeper?
基本上,为了在(节点组)之间进行协调并使用强大的同步技术维护共享数据,集群使用 Apache ZooKeeper。但是,对于编写分布式应用程序,ZooKeeper本身就是一个提供多种服务的分布式应用程序。所以,我们在这里列出了ZooKeeper提供的常用服务,例如: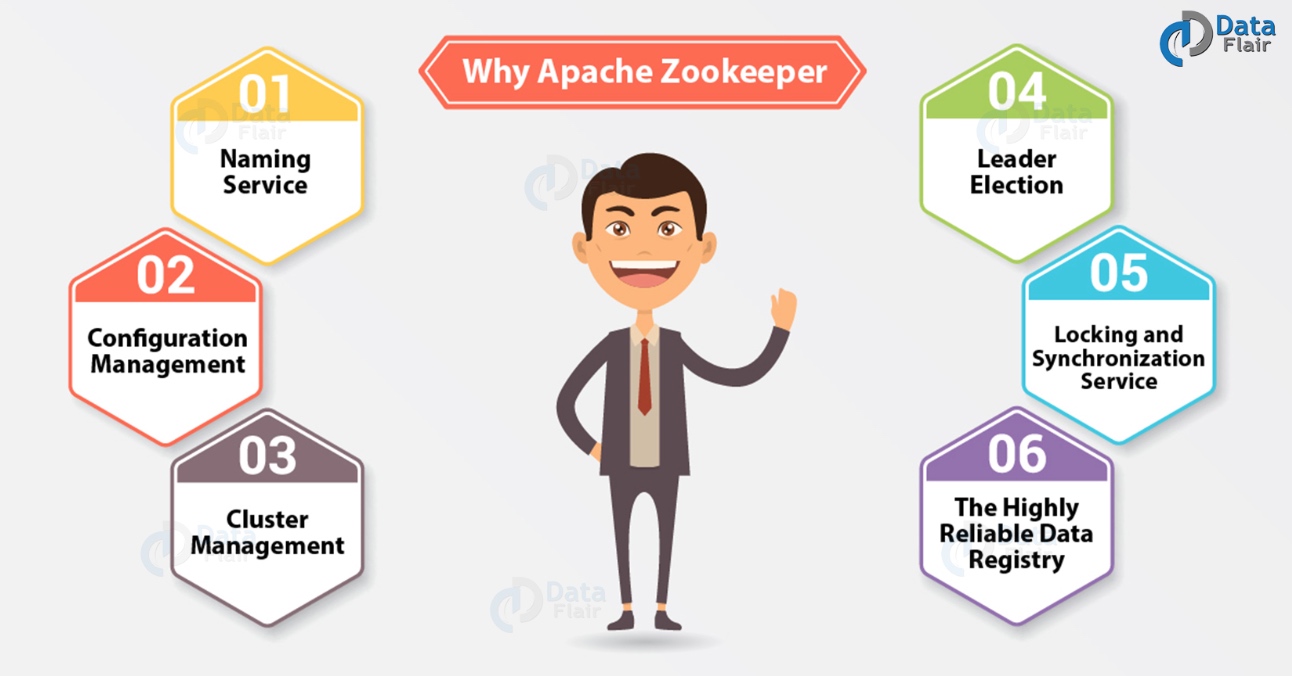
a. 命名服务
在群集中,按名称标识节点。
b. 配置管理
对于加入节点,系统的最新和最新配置信息。
c. 集群管理
实时地,在群集和节点状态中加入/下架节点。
d. Leader选举
出于协调目的,选择一个节点作为领导者。
e. 锁定和同步服务
在修改它时,锁定数据。在连接其他分布式应用程序(如Apache HBase)时,此机制可帮助我们自动进行故障恢复。
f. 高度可靠的数据注册表
即使一个或几个节点关闭 了数据的可用性。
由于分布式应用程序也提供了很少的复杂和难以破解的挑战,因此,为了克服所有挑战,ZooKeeper框架提供了一个完整的机制。此外,使用故障安全同步方法,我们可以处理竞争条件和死锁。此外,ZooKeeper解决了数据与原子性的不一致性。
使用Docker容器化ZooKeeper
通过使用Docker容器化ZooKeeper。因此,作为一个很大的好处,可以按需添加和删除节点。但是,只能通过在Docker镜像中添加ZooKeeper并在集群的每个主服务器上使用它来运行容器。
此外,它应该独立地创建一个集群,或者它应该能够在启动容器期间连接到现有集群并成为其一部分。因此,它允许使用Docker容器化动态重新配置整个Hadoop集群,这是使用Docker容器的好处。
什么是ZooKeeper客户端?
与所有分布式应用程序一样,Zookeeper分布式应用程序也包含服务器和客户端。它有一个集中的界面,客户端可以通过该界面连接到服务。但是,这些客户端可以是命令行或GUI客户端。基本上,可用于与ZooKeeper分布式应用程序交互的工具就是我们所说的ZooKeeper客户端应用程序。
什么是Zookeeper群集?
因为我们需要在集群模式下拥有ZooKeeper基础架构,以便在我们大规模运行Apache ZooKeeper时使系统处于最佳值。我们还将ZooKeeper集群称为集合体。但是,如果ZooKeeper集群必须成功运行,请确保大多数集群节点始终需要启动并运行。
ZooKeeper WebUI
基本上,要使用ZooKeeper资源管理,ZooKeeper WebUI或Web用户界面是一种更简单的方法。因此,WebUI允许使用Web用户界面使用ZooKeeper,而不是使用命令行与ZooKeeper应用程序进行交互。因此,我们可以说它使工作变得更加容易和有效。
Apache ZooKeeper应用程序
简而言之,为了大规模创建高度可用的分布式系统,它已成为最受欢迎的选择之一。因此,Apache基金会最成功的项目之一是ZooKeeper项目。
点击链接了解有关ZooKeeper Applications的更多信息
Apache ZooKeeper通过为实现不同的大数据工具提供坚实的基础,使公司能够在大数据世界中顺利运行。因此,它是大规模实施的最优选应用之一,因为它能够一次提供多种益处。
使用ZooKeeper的公司
现在,在这个Apache ZooKeeper教程中,我们提供了一个使用ZooKeeper的公司列表:
- Yahoo
- 易趣
- eBay
- Netflix
- Netflix
- Zynga
- Nutanix
- 百度
- 腾讯
- 阿里
- 携程
- 京东
- 小米
Apache ZooKeeper的好处
有各种ZooKeeper的好处,例如: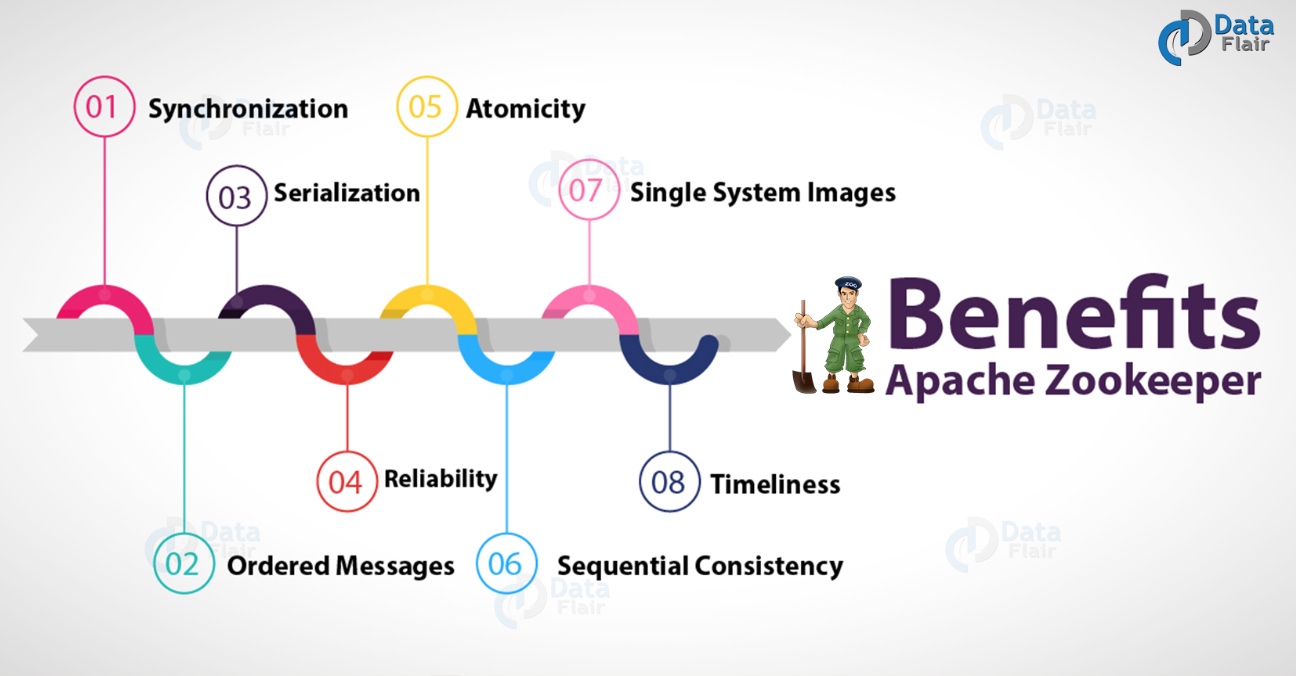
a. 同步
它允许互斥以及服务器进程之间的协作。因此,这有助于Apache HBase,用于配置管理
b. 有序消息
通过用表示其顺序的数字标记每个更新,它会跟踪。
c. 序列化
它确保我们的应用程序一致运行。要协调队列以执行正在运行的线程,可以在MapReduce中使用此方法。
d. 可靠性
应用更新后,它将从该时间开始持续,直到客户端覆盖更新。
e. 原子性
没有事务是部分的,数据传输成功或完全失败。
f. 顺序一致性
按照发送它们的顺序,它应用来自客户端的更新。
g. 单系统镜像
无论它连接到哪个服务器,客户端都会看到相同的服务视图。
h. 及时性
在一定的时间范围内,客户端对系统的视图是最新的。
ZooKeeper用例
Apache ZooKeeper教程中ZooKeeper的一些最突出的用例是:
- 管理配置
- 命名服务
- 选择Leader
- 对消息进行排队
- 管理通知系统
- 同步
通过使用ZooKeeper CLI,我们还可以与ZooKeeper集合进行通信。基本上,这为我们提供了使用各种选项的功能。此外,为了调试,还依赖于命令行界面。
教程英文原文: https://henduan.com/igCAR





